Logiciel de transcription pour la recherche qualitative
Découvrez le meilleur logiciel de transcription pour la recherche qualitative. Ce guide couvre la précision, l'intégration du flux de travail et la confidentialité des données pour un usage académique.
Praveen
November 20, 2024
Choisir le bon logiciel de transcription pour la recherche qualitative est plus qu'une simple étape logistique, c'est le fondement de toute votre analyse. Si vous faites le bon choix, vous obtiendrez un texte structuré et consultable qui accélérera vos découvertes. Si vous vous trompez, vous vous retrouverez face à des heures de corrections fastidieuses.
Ce choix a un impact direct sur l'intégrité de vos données et l'efficacité de votre flux de travail. Il s'agit d'équilibrer la précision, les fonctionnalités spécifiques à la recherche et une sécurité des données solide.
Choisir le bon logiciel de transcription pour votre recherche
La recherche qualitative réside dans la nuance. Ce sont les pauses subtiles, les dialogues qui se chevauchent et le jargon spécifique qui révèlent ce qui se passe réellement. Votre logiciel de transcription n'est pas seulement un outil ; c'est un partenaire pour capturer cette richesse. Un mauvais choix peut introduire des inexactitudes qui faussent vos résultats ou, pire encore, compromettre la confidentialité des participants.
L'une des premières choses que vous devrez décider est de savoir si vous optez pour un service d'IA purement automatisé ou pour une plateforme qui intègre un humain pour la révision. L'IA a fait beaucoup de chemin, mais elle peut encore buter sur le jargon académique, les accents prononcés ou un enregistrement dans un café bruyant. C'est là qu'une touche humaine apporte une couche essentielle de contrôle qualité.
Fonctionnalités essentielles dont tout chercheur a besoin
Lorsque vous examinez un logiciel de transcription pour la recherche qualitative, vous devez penser au-delà de la simple conversion parole-texte. Votre objectif est de trouver des fonctionnalités qui facilitent réellement la partie analyse.
Voici les éléments indispensables :
Capacités de transcription essentielles pour les chercheurs
IA de pointe
Alimenté par Whisper d'OpenAI pour une précision de premier plan. Prise en charge des vocabulaires personnalisés, des fichiers jusqu'à 10 heures et des résultats ultra rapides.

Importer depuis plusieurs sources
Importez des fichiers audio et vidéo depuis diverses sources, y compris le téléchargement direct, Google Drive, Dropbox, les URL, Zoom et plus encore.
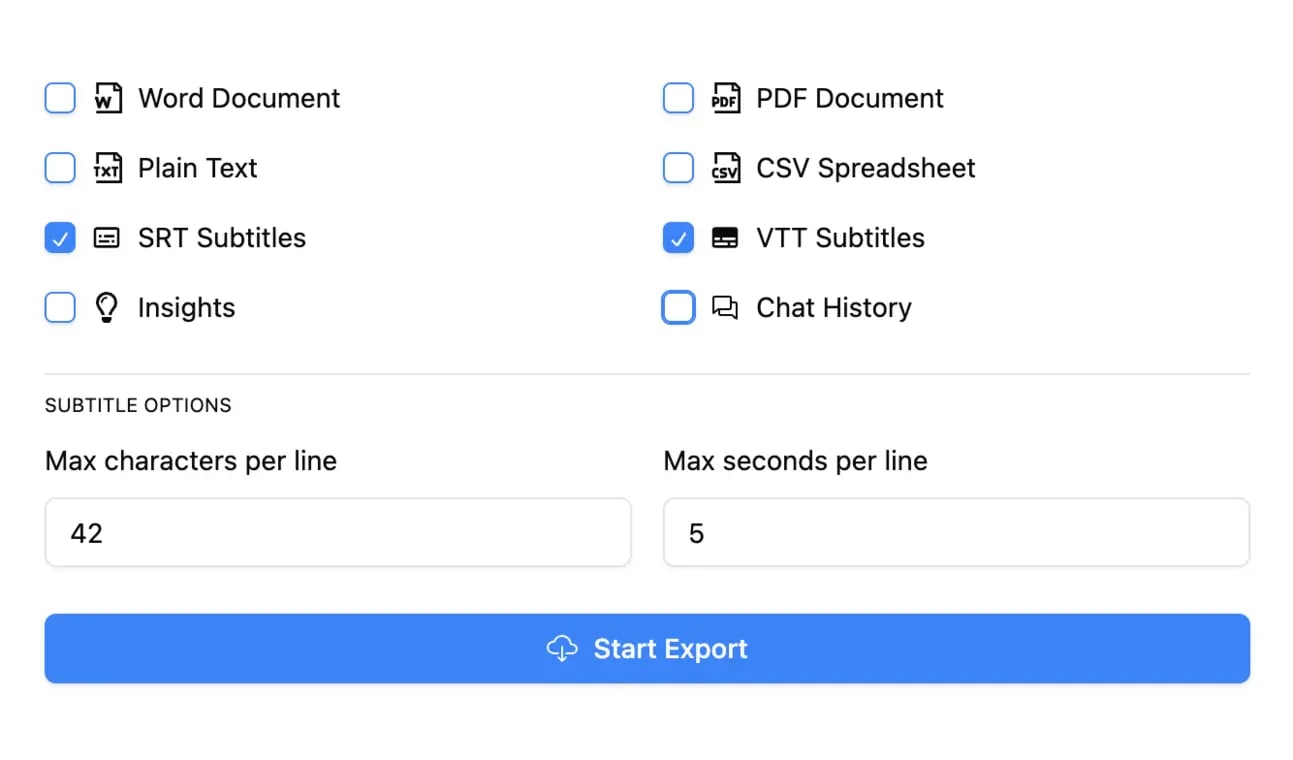
Exporter en plusieurs formats
Exportez vos transcriptions en plusieurs formats dont TXT, DOCX, PDF, SRT et VTT avec des options de formatage personnalisables.
- Haute précision : La transcription doit être un enregistrement fidèle de la conversation. Assurez-vous que le service peut gérer votre sujet spécifique et vos conditions audio.
- Identification fiable des intervenants : Vous devez absolument savoir qui a dit quoi, surtout dans les groupes de discussion. La détection automatique des intervenants est un gain de temps énorme, mais elle doit être facile à modifier lorsque l'IA se trompe.
- Horodatages précis : Les horodatages sont votre bouée de sauvetage, reliant le texte à l'audio d'origine. C'est ainsi que vous pouvez rapidement revenir au ton d'un participant ou clarifier une phrase marmonnée directement depuis votre logiciel d'analyse. Nous avons rédigé un guide complet sur l'importance de la transcription avec timecode si vous souhaitez approfondir le sujet.
- Formats d'exportation flexibles : Le logiciel doit être compatible avec votre logiciel d'analyse de données qualitatives (QDAS). Recherchez des options d'exportation simples comme .docx ou .txt que vous pouvez importer directement dans des outils tels que NVivo, ATLAS.ti ou Dedoose.
L'objectif est d'obtenir une transcription prête à être codée immédiatement, et non une transcription qui nécessite une réécriture complète. Chaque minute que vous passez à corriger la mise en forme ou les noms est une minute que vous ne consacrez pas à l'analyse.
Pourquoi un formatage prêt pour la recherche permet d'économiser des semaines de travail ?
Des transcriptions propres réduisent le temps de configuration dans les logiciels d'analyse qualitative. Des étiquettes de locuteur appropriées, des horodatages et des formats d'exportation simples permettent un codage instantané sans restructurer les fichiers. Cela accélère considérablement la transition de la collecte de données à la génération d'idées.
Lorsque vous serez prêt à évaluer différentes plateformes, une simple liste de contrôle vous permettra de vous concentrer sur ce qui compte vraiment pour la recherche.
Liste de contrôle des fonctionnalités clés pour les logiciels de recherche qualitative
| Fonctionnalité | Pourquoi elle est essentielle pour les chercheurs | Ce qu'il faut rechercher |
|---|---|---|
| Haute précision | Si les données d'entrée sont mauvaises, les données de sortie le seront aussi. Des transcriptions inexactes entraînent une analyse erronée et peuvent compromettre l'ensemble de votre étude. | Taux de précision de 98 % et plus ; capacité à gérer le jargon, les accents et le bruit de fond. |
| Étiquetage des intervenants | Essentiel pour suivre les dialogues dans les entretiens et les groupes de discussion. Sans cela, vous ne pouvez pas attribuer correctement les citations. | Identification automatisée de plusieurs intervenants, facilement modifiable. |
| Horodatages | Lie le texte à l'audio d'origine pour vérification. Crucial pour vérifier le ton, l'émotion et le contexte. | Horodatages au niveau du mot ou du paragraphe, faciles à naviguer. |
| Formats d'exportation multiples | Assure la compatibilité avec votre logiciel d'analyse qualitative préféré (QDAS). | Formats .docx, .txt et .srt qui s'importent proprement dans des outils tels que NVivo ou ATLAS.ti. |
| Sécurité et confidentialité des données | Votre recherche implique souvent des informations sensibles. La protection de la confidentialité des participants est indispensable. | Politiques de confidentialité claires, chiffrement des données et conformité aux normes telles que le RGPD ou la HIPAA. |
Cette liste de contrôle n'est pas exhaustive, mais elle couvre les fonctionnalités essentielles qui rendront votre projet soit un jeu d'enfant, soit un cauchemar.
Qui bénéficie le plus de la transcription de qualité recherche ?
Chercheurs universitaires
Convertissez les entretiens et les groupes de discussion en ensembles de données structurés pour le codage, l'analyse thématique et des aperçus prêts à être publiés.
Étudiants en doctorat et en master
Transformez les réunions de supervision enregistrées et les entretiens sur le terrain en matériel d'étude organisé et consultable.
Chercheurs en UX et en marché
Analysez plus rapidement les entretiens clients avec des transcriptions étiquetées par locuteur et horodatées, prêtes pour la cartographie du parcours.
Analystes dans le domaine de la santé et des politiques
Traitez en toute sécurité des entretiens sensibles tout en maintenant une conformité et une confidentialité strictes.
Il n'est pas surprenant que le marché de ces outils soit en plein essor. Le marché américain de la transcription était évalué à 30,42 milliards USD en 2024 et devrait atteindre 41,93 milliards USD d'ici 2030, les logiciels basés sur l'IA menant la charge. Cette croissance signifie plus d'options pour les chercheurs, mais elle signifie aussi que vous devez être plus perspicace.
En fin de compte, le choix de votre logiciel est une décision stratégique. En donnant la priorité aux fonctionnalités qui soutiennent le travail ardu de l'analyse qualitative, vous préparez votre projet au succès dès le premier jour.
Décoder les affirmations d'exactitude dans la transcription par IA
Dans la recherche qualitative, l'exactitude n'est pas seulement un chiffre, c'est le fondement absolu de votre analyse. C'est la différence entre capturer l'intuition authentique d'un participant et mal interpréter complètement son sens. Il s'agit de préserver cette tournure de phrase précise, cette pause hésitante ou ce bavardage qui déborde de données précieuses.
Bien que les outils de transcription par IA soient devenus incroyablement puissants, leur marketing peut être un champ de mines pour les chercheurs. Une entreprise pourrait afficher "95 % d'exactitude" sur sa page d'accueil, mais ce chiffre est presque toujours basé sur des conditions de laboratoire parfaites : un seul locuteur clair, sans bruit de fond et sans terminologie complexe.
La recherche qualitative ne se déroule jamais dans un environnement aussi immaculé.
L'écart d'exactitude dans le monde réel
Soyons honnêtes, nos données sont désordonnées. Les groupes de discussion, les notes de terrain ethnographiques et même les entretiens individuels sont remplis de plusieurs locuteurs, d'accents divers, de moments émotionnels et de jargon académique. Dans ces scénarios du monde réel, les performances d'une IA peuvent chuter, mettant l'intégrité de vos données en grave danger.
Pensez à ces situations courantes où l'IA trébuche souvent :
- Mauvaise interprétation du sarcasme : Une IA transcrira un commentaire sarcastique littéralement, manquant complètement le ton ironique et déformant le sens entier de la réponse du participant.
- Fusion de locuteurs : Dans un groupe de discussion au rythme rapide, une IA peut facilement se confondre et attribuer une citation critique à la mauvaise personne.
- Ignorer les indices non verbaux : Un silence réfléchi (par exemple, "[pause 5s]") ou un rire partagé est une donnée contextuelle cruciale que les systèmes automatisés manquent presque toujours.
- Bousculer le jargon : Les termes spécialisés en médecine, en droit ou en sociologie sont souvent transcrits comme un non-sens phonétique que l'IA pense avoir entendu, vous obligeant à passer des heures à le nettoyer.
Ce ne sont pas de simples fautes de frappe ; ce sont des événements de corruption de données. Ils peuvent vous mener sur la mauvaise voie et directement à des conclusions erronées. C'est pourquoi vous devez regarder au-delà des chiffres marketing attrayants et être réaliste quant aux limites.
Les erreurs de l'IA peuvent invalider les résultats de la recherche
Même de petites erreurs de transcription peuvent déformer le sens des participants, introduire de faux codes et affaiblir la validité de la recherche. Sans examen humain, les transcriptions générées par l'IA peuvent introduire silencieusement des biais et de la désinformation dans votre analyse.
Pourquoi 86 % est une note d'échec pour la recherche
Le passage de la précision de la machine à la précision humaine n'est pas un petit pas, c'est un gouffre qualitatif énorme. Les études montrent souvent que la transcription par IA atteint environ 86 % de précision dans des conditions typiques, moins qu'idéales. Pour un travail qualitatif où chaque mot compte, ce n'est tout simplement pas suffisant.
Comparez cela aux services humains professionnels, qui peuvent atteindre 99,9 % de précision. Cet écart a un impact direct sur la validité de votre analyse.
Un taux de précision de 86 % signifie qu'en moyenne, 14 mots sur 100 pourraient être erronés. Dans un entretien de 30 minutes (environ 4 500 mots), cela se traduit par plus de 600 erreurs potentielles. Corriger ce volume d'erreurs n'est pas seulement fastidieux ; c'est une tâche de recherche massive en soi.
L'erreur la plus dangereuse n'est pas celle qui est flagrante. C'est l'erreur subtile qui passe inaperçue, s'intègre dans votre codage et est traitée comme un fait.
Une approche hybride pour protéger votre travail
Cela ne signifie pas que l'IA est inutile. Loin de là. Une transcription automatisée peut être une excellente première ébauche, surtout si vous avez un budget ou un délai serré. La clé est de la traiter exactement comme telle : une ébauche qui exige une révision humaine rigoureuse. Ce flux de travail hybride vous permet d'obtenir la vitesse de l'IA sans sacrifier l'intégrité de vos données.
Pour bien comprendre ce qui influence les résultats, il est utile de connaître les rouages de ce qui rend une transcription précise. Pour une analyse plus approfondie, consultez notre guide sur comment la précision de la parole au texte est mesurée et améliorée.
Lorsque vous évaluez des logiciels de transcription pour la recherche qualitative, votre choix doit être basé sur votre projet spécifique. Si votre audio est d'une clarté cristalline et que le sujet est général, l'IA pourrait vous mener la majeure partie du chemin. Mais pour la grande majorité des projets qualitatifs, où la nuance est primordiale, budgétiser du temps pour une révision humaine approfondie n'est pas seulement une bonne pratique. C'est une obligation éthique envers vos participants et votre recherche.
Intégrer la transcription dans votre flux de travail de recherche
Soyons honnêtes, la transcription est souvent considérée comme la partie fastidieuse de la recherche qualitative, la corvée à accomplir avant que la vraie analyse ne commence. Mais penser ainsi est une erreur.
Votre processus de transcription n'est pas juste une tâche ; c'est le pont critique entre l'audio brut et les découvertes éclairantes. Un flux de travail maladroit ici ne fait pas que perdre du temps, il peut introduire des erreurs et créer des goulots d'étranglement qui font dérailler tout votre projet. Le véritable objectif est un flux fluide de l'enregistrement jusqu'au codage.
Tout cela dépend de la façon dont votre logiciel de transcription s'intègre à votre logiciel d'analyse de données qualitatives (QDAS). Les grands noms comme NVivo, ATLAS.ti et Dedoose sont conçus pour gérer du texte structuré, mais la qualité de cet import dépend entièrement de la transcription que vous leur fournissez.
Au-delà de l'importation et de l'exportation simples
Une véritable intégration va bien au-delà du simple déversement d'un fichier texte dans votre QDAS. Il s'agit d'utiliser les fonctionnalités de votre outil de transcription pour rendre le processus de codage plus rapide, plus précis et, franchement, plus agréable.
Voici ce qui compte réellement pour une transition en douceur :
Intégration du flux de travail et outils d'analyse

Détection des intervenants
Identifiez automatiquement les différents intervenants dans vos enregistrements et étiquetez-les avec leurs noms.
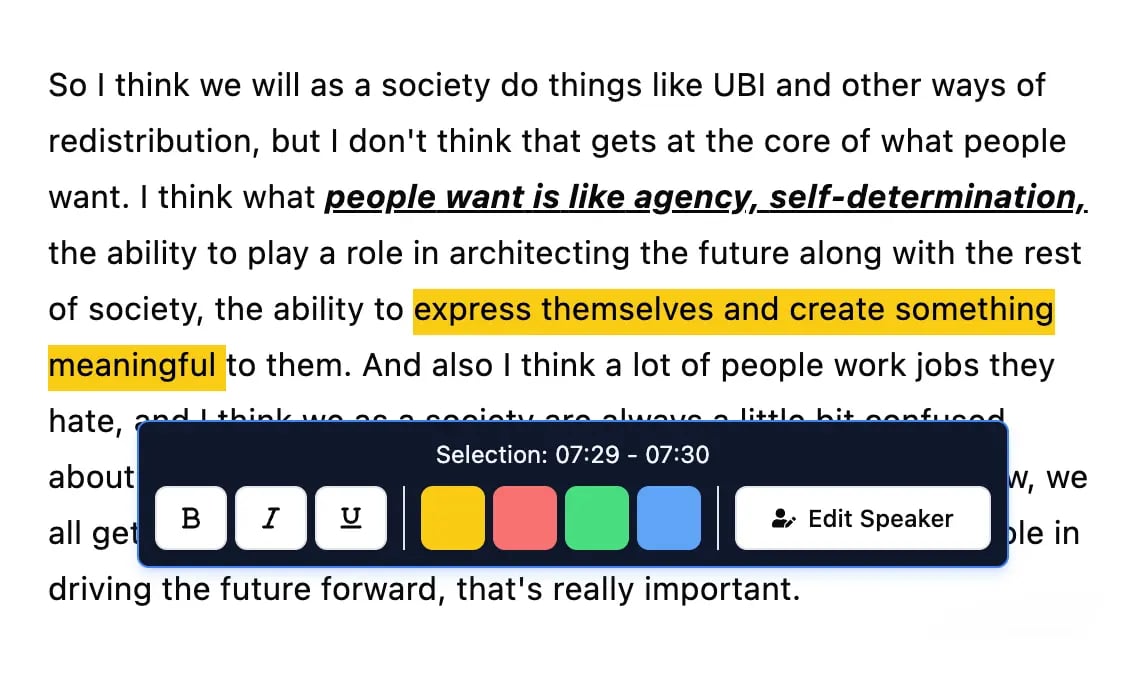
Outils d'édition
Modifiez les transcriptions avec des outils puissants incluant rechercher et remplacer, attribution des intervenants, formats de texte enrichi et surlignage.
Résumés et Chatbot
Générez des résumés et d'autres analyses de votre transcription, des prompts personnalisés réutilisables et un chatbot pour votre contenu.
Intégrations
Connectez-vous à vos outils et plateformes préférés pour optimiser votre flux de travail de transcription.
- Horodatages précis : C'est un atout majeur. Lorsque les horodatages sont intégrés à votre transcription, vous pouvez cliquer sur une citation dans votre QDAS et sauter instantanément à ce moment précis de l'audio. C'est inestimable pour saisir le ton d'un participant, clarifier un mot marmonné ou revivre le contexte émotionnel d'une déclaration puissante.
- Étiquettes d'interlocuteur claires : Des étiquettes d'interlocuteur cohérentes et précises (comme "Interviewer", "Participant 1", "Dr. Smith") sont absolument non négociables. Si vous faites cela correctement, votre QDAS peut trier automatiquement les citations par interlocuteur, ce qui facilite grandement la comparaison des réponses ou le suivi de l'histoire d'une personne tout au long de la conversation.
- Options d'exportation intelligentes : Les meilleurs outils proposent des exportations conçues spécifiquement pour l'analyse. Vous voulez des formats simples et clairs comme le texte brut (.txt) ou des documents Word de base (.docx) qui ne perturberont pas vos outils d'importation QDAS avec un formatage étrange.
Considérez votre transcription comme un ensemble de données pré-organisé. Plus vous intégrez de structure lors de la transcription — avec des interlocuteurs et des horodatages clairs — moins vous aurez de travail fastidieux à faire lors de l'analyse.
Cette infographie détaille à quoi ressemble un flux de travail solide, de qualité recherche.
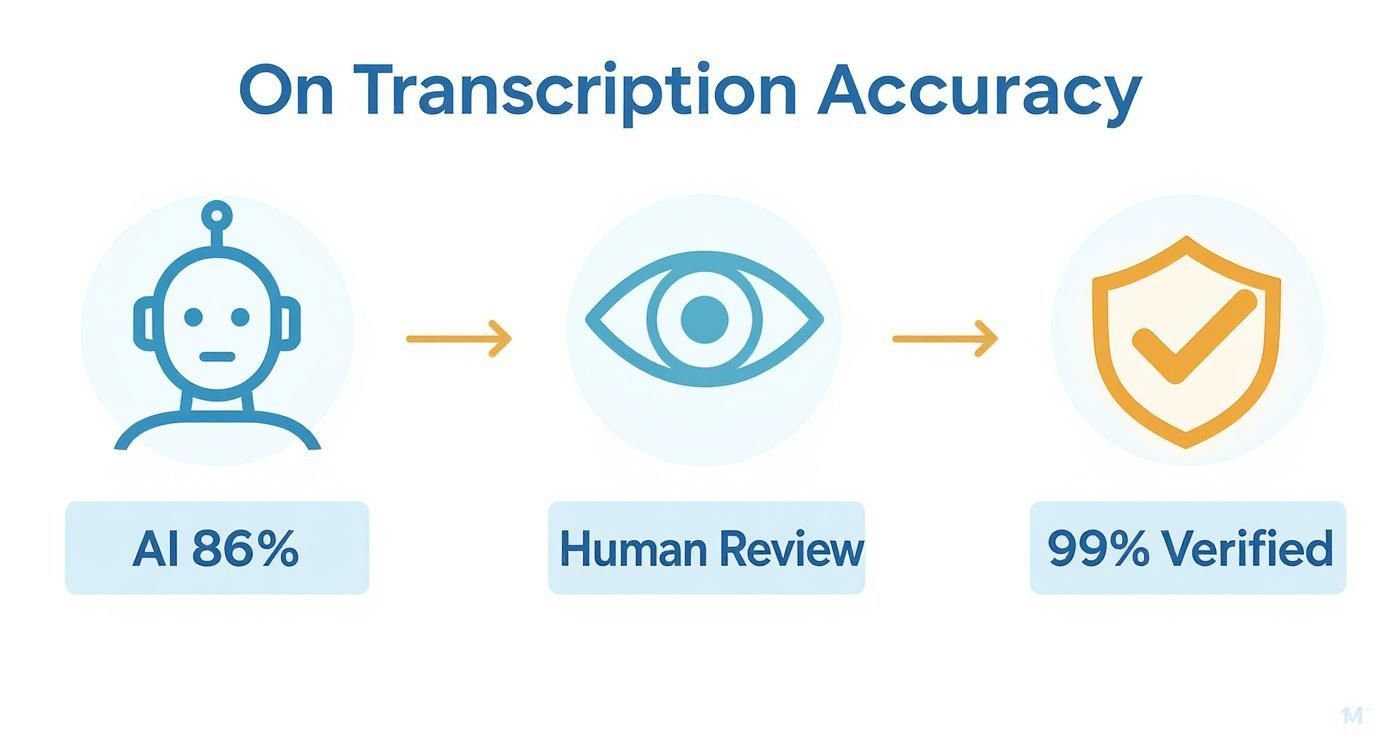
Comme vous pouvez le constater, le processus commence par une bonne ébauche par IA, puis repose sur une révision humaine pour atteindre la marque de 99 % de précision — la norme requise pour une recherche académique et professionnelle rigoureuse.
L'approche hybride IA + examen humain est la nouvelle norme de recherche
La plupart des universités et des comités d'éthique recommandent désormais une approche hybride : l'IA pour la vitesse, l'examen humain pour la précision. Cela garantit à la fois la productivité et l'intégrité complète des données dans la recherche qualitative moderne.
Adapter les flux de travail à différents scénarios de recherche
Bien sûr, votre flux de travail changera en fonction de votre méthode de recherche. Un entretien individuel est à des années-lumière d'un groupe de discussion chaotique.
- Pour les entretiens approfondis : Ici, l'accent est mis sur les détails riches et nuancés d'une seule personne. Les horodatages au niveau des mots sont d'une aide précieuse pour analyser les pauses et les hésitations. Un export propre vous permet de coder automatiquement l'intégralité du document pour le dossier de ce participant dans NVivo en quelques secondes.
- Pour les groupes de discussion : L'identification des intervenants est primordiale. Avant même de penser à exporter, votre priorité absolue est de vous assurer que chaque intervenant est correctement et systématiquement étiqueté. Ce travail de préparation permet à votre logiciel d'analyse qualitative (QDAS) de traiter chaque participant comme une source unique, ce qui est essentiel pour comparer les perspectives au sein du groupe.
- Pour les notes de terrain ethnographiques : Si vous dictez des notes en déplacement, une transcription IA solide peut transformer vos pensées parlées en texte consultable presque instantanément. De là, vous pouvez importer le texte dans votre logiciel d'analyse et le coder aux côtés de vos autres données.
Une fois votre texte prêt, vous aurez besoin de stratégies efficaces pour analyser les données d'entretien pour en extraire ces précieuses informations. Pour approfondir cette partie du processus, consultez notre guide sur comment analyser les données d'entretien.
Connexion avec les logiciels d'analyse de données qualitatives
Nous ne sommes pas les seuls à nous concentrer sur une meilleure intégration. Le marché mondial des logiciels d'analyse de données qualitatives était évalué à 1,56 milliard USD en 2024 et devrait atteindre 2,76 milliards USD d'ici 2033. Cette croissance est due à la demande croissante d'outils qui fonctionnent ensemble de manière transparente. Lisez la recherche complète sur le marché des logiciels d'analyse qualitative.
Construire un flux de travail de recherche efficace signifie considérer la transcription non pas comme un produit final, mais comme une étape préparatoire cruciale. Lorsque vous choisissez un outil en gardant à l'esprit une forte intégration, vous investissez dans un processus de recherche plus intelligent, plus rapide et plus rigoureux.
Transcription par méthode de recherche
Entretiens approfondis
Mieux pris en charge par des horodatages au niveau du mot et un étiquetage propre des locuteurs pour l'analyse émotionnelle et narrative.
Groupes de discussion
Nécessite une détection multi-locuteurs de haute précision pour comparer les points de vue et les dynamiques d'interaction.
Études ethnographiques
La transcription de notes vocales permet une transformation rapide des observations sur le terrain en données codées.
Recherche politique et juridique
Exige une précision extrême, un stockage de données à long terme et des protocoles de sécurité stricts.
Protection des données et de la confidentialité des participants

Lorsque votre travail implique des sujets humains, la sécurité des données n'est pas seulement une case technique à cocher, c'est une pierre angulaire éthique. Chaque fichier audio que vous téléchargez contient des informations sensibles et personnelles que vos participants vous ont confiées. Placer ces fichiers dans un outil en ligne non vérifié peut facilement enfreindre les protocoles des comités d'éthique de la recherche (CER), violer des accords légaux et, plus important encore, trahir cette confiance.
La responsabilité de la protection de ces données vous incombe entièrement en tant que chercheur. La commodité d'un service rapide et gratuit a souvent un prix élevé et caché, généralement enfoui profondément dans des conditions d'utilisation complexes. S'associer à un fournisseur de transcription qui respecte les normes les plus élevées en matière d'éthique de la recherche est absolument non négociable.
Évaluation des politiques de confidentialité et des mesures de sécurité
Avant de télécharger le moindre octet de données, vous devez vous familiariser avec la lecture des politiques de confidentialité. Oui, elles peuvent être denses, mais elles contiennent les indices cruciaux sur la manière dont une entreprise gérera réellement vos données de recherche. Ne vous contentez pas de les parcourir, recherchez activement des réponses à quelques questions clés.
Voici ce que vous devriez rechercher :
- Chiffrement de bout en bout : C'est la base. Il garantit que vos données sont brouillées et illisibles dès le moment où elles quittent votre ordinateur jusqu'au moment où elles sont traitées. Recherchez des termes tels que le chiffrement AES-256, une référence absolue pour sécuriser les données.
- Protocoles clairs de traitement des données : La politique doit indiquer explicitement qui peut accéder à vos données et pourquoi. Un langage vague est un signal d'alarme majeur.
- Conformité aux réglementations : Selon l'endroit où vous et vos participants vous trouvez, vous devrez voir des engagements envers des normes telles que le RGPD pour les données européennes ou le HIPAA pour les informations relatives à la santé.
Votre principe directeur ici est simple : si un service ne peut pas expliquer clairement comment il protège vos données, supposez qu'il ne le fait pas. La confiance se construit sur la transparence, pas sur l'espoir.
Pour un exemple solide de ce à quoi cela ressemble en pratique, vous pouvez consulter la documentation telle que la Politique de confidentialité de Parakeet-AI. C'est le type de document qui vous permet d'avoir confiance dans l'engagement de sécurité d'une plateforme.
Les risques cachés de la formation des modèles d'IA
L'un des plus grands pièges éthiques dans l'utilisation des logiciels de transcription modernes pour la recherche qualitative réside dans la manière dont les modèles d'IA sont formés. De nombreux services, en particulier les services gratuits, insèrent une clause dans leurs conditions leur donnant le droit d'utiliser vos enregistrements audio et vos transcriptions pour améliorer leur propre IA.
C'est un point rédhibitoire pour la recherche confidentielle. Cela signifie que les histoires, les opinions et les données personnelles de vos participants pourraient faire partie d'un ensemble de données permanent et propriétaire, utilisé à des fins commerciales sur lesquelles vous n'avez aucun contrôle.
L'entraînement de l'IA sur des données de recherche est une violation éthique
Si votre fournisseur de transcription utilise les données des participants pour l'entraînement de l'IA, vous pourriez involontairement enfreindre des accords de consentement, des conditions de comité d'éthique de la recherche (CER) et des lois internationales sur la protection de la vie privée. Exigez toujours une politique stricte de zéro entraînement.
Vous devez trouver un service avec une politique de formation explicite et nulle. C'est une promesse ferme que vos données seront uniquement utilisées pour générer votre transcription, rien d'autre. Par exemple, vous pouvez voir comment une position stricte de non-formation protège vos données dans cette politique de confidentialité : https://transcript.lol/legal/privacy. Cette garantie est la norme absolue pour toute recherche académique ou professionnelle sérieuse.
Un autre facteur crucial est la résidence des données, l'emplacement physique et géographique où vos données sont stockées. De nombreuses subventions et exigences du comité d'éthique de la recherche (CER) exigent que les données restent dans un pays ou une région spécifique (comme l'Union européenne). Un service digne de confiance sera transparent quant à l'emplacement de ses serveurs, vous permettant de respecter vos obligations institutionnelles et de financement sans aucune conjecture.
Votre Premier Projet Avec Transcript.LOL
Passons à la pratique. La théorie est excellente, mais la meilleure façon de voir comment un bon logiciel de transcription pour la recherche qualitative change vraiment les choses est de se lancer. Je vais vous guider à travers un projet de recherche réel, du début à la fin, en utilisant Transcript.LOL pour vous montrer comment il résout les problèmes habituels.
https://www.youtube.com/embed/eSOssNY9v6A
Imaginez ceci : vous venez de terminer un groupe de discussion de 45 minutes. Vous avez trois participants et un modérateur. Le fichier audio est sur votre bureau, et vous devez le transférer dans NVivo pour le codage, sans passer une semaine sur une transcription manuelle.
De l'audio brut à une ébauche fonctionnelle
Avant toute chose, vous devez importer votre fichier audio dans le système. Avec Transcript.LOL, vous pouvez simplement glisser-déposer le fichier depuis votre ordinateur ou même le tirer depuis le stockage cloud comme Google Drive. Il se met immédiatement au travail, alimenté par le moteur Whisper d'OpenAI.
En quelques minutes seulement, vous aurez une première ébauche complète. L'IA détermine automatiquement qui parle et leur attribue des étiquettes comme "Locuteur 1", "Locuteur 2", etc. Ce n'est pas le produit final, mais c'est une base solide sur laquelle construire.
L'interface est épurée et simple. Elle place le texte juste à côté d'un lecteur audio, vous permettant d'écouter et de lire en même temps.
Cette vue est votre centre de commande. Vous pouvez voir les tours de parole clairs et disposer de tous les outils d'édition dont vous avez besoin, ce qui rend le processus de révision beaucoup plus rapide.
Affiner la transcription pour l'analyse
C'est là que votre expertise de chercheur entre en jeu. L'IA est une assistante fantastique, mais elle manque de contexte. Votre première tâche est de donner un sens à ces étiquettes de locuteurs génériques. Cliquez simplement sur "Locuteur 1" et renommez-le en "Modérateur", changez "Locuteur 2" en "Participant A", et ainsi de suite. Le meilleur dans tout ça ? Le changement s'applique automatiquement partout. Fini les cauchemars de recherche et remplacement.
Ensuite, abordons le jargon et la terminologie. Supposons que votre groupe de discussion discutait de "phénoménologie herméneutique", mais que l'IA ait entendu "phénomène hermétique". Correction facile. Il vous suffit de cliquer sur la phrase et de taper le terme correct.
L'une des fonctionnalités les plus puissantes pour les chercheurs est la création d'un vocabulaire personnalisé. Si vous indiquez au logiciel de toujours reconnaître "phénoménologie" ou le nom de votre chercheur principal, vous verrez la précision s'améliorer dans toutes les transcriptions futures pour ce projet. C'est une petite étape qui permet d'économiser beaucoup de temps d'édition par la suite.
C'est aussi l'occasion de faire un contrôle qualité final. Vous pouvez fusionner des paragraphes si la pensée de quelqu'un a été divisée, corriger la ponctuation errante et simplement vous assurer que la transcription reflète fidèlement le flux de la conversation originale. C'est une étape rapide mais absolument essentielle.
Préparer l'exportation pour votre logiciel d'analyse qualitative (QDAS)
Une fois que vous êtes satisfait de la transcription, il est temps de l'exporter pour votre logiciel d'analyse, comme ATLAS.ti ou Dedoose. C'est souvent là que les choses se compliquent avec d'autres outils, mais une plateforme conçue pour les chercheurs rend cela indolore.
Au lieu de simplement produire un fichier .txt générique, vous obtenez des options adaptées à l'analyse qualitative des données.
Liste de contrôle d'exportation pour NVivo ou ATLAS.ti :
- Sélectionnez le format .docx. C'est l'option la plus fiable pour une importation propre, préservant votre texte sans formatage étrange qui pourrait perturber votre QDAS.
- Assurez-vous que les étiquettes de locuteurs sont activées. Votre exportation doit inclure les noms corrigés ("Modérateur", "Participant A") afin que votre logiciel puisse les reconnaître comme des personnes différentes.
- Incluez les horodatages. Vous pouvez choisir d'ajouter des horodatages à intervalles réguliers ou simplement au début de chaque paragraphe. C'est ce qui relie le texte de votre logiciel d'analyse au moment exact de l'audio.
Avec ces paramètres réglés, il vous suffit de télécharger le fichier. Lorsque vous importerez ce document dans NVivo, il reconnaîtra automatiquement les différents locuteurs et synchronisera les horodatages. Ainsi, vous obtenez une transcription propre et parfaitement formatée, prête pour le codage.
Vous êtes passé d'un fichier audio brut à une analyse approfondie en une fraction du temps qu'il aurait fallu manuellement, le tout sans compromettre la précision dont votre recherche a besoin.
Des questions ? Nous avons des réponses.
Lorsque vous êtes plongé dans la recherche qualitative, la transcription peut sembler être un champ de mines de questions pratiques et éthiques. Nous comprenons. Vous avez besoin d'outils qui ne sont pas seulement précis, mais qui s'intègrent à votre flux de travail et respectent vos données. Abordons certaines des questions les plus courantes que nous entendons de la part des chercheurs.
Comment gérer les enregistrements audio de mauvaise qualité ?
Ah, le redoutable enregistrement de mauvaise qualité. C'est probablement le plus gros casse-tête pour toute transcription, que vous utilisiez une IA ou un humain. La meilleure chose à faire est toujours la prévention : sérieusement, un microphone externe vous donnera des résultats considérablement meilleurs que le microphone intégré de votre ordinateur portable.
Mais parfois, vous êtes coincé avec ce que vous avez. Tout n'est pas perdu.
Avant même de penser à l'importer, essayez de le nettoyer avec un outil gratuit comme Audacity. Son filtre de réduction de bruit peut faire des merveilles sur le bourdonnement de fond, et l'outil d'amplification peut augmenter le volume des voix trop faibles. Vous seriez surpris de voir à quel point quelques ajustements simples peuvent aider.
Si l'audio est absolument critique mais toujours en désordre, c'est là qu'un transcripteur humain professionnel gagne vraiment sa vie. Ils sont formés pour déchiffrer la parole brouillée et peuvent souvent sauver des informations clés qu'un algorithme marquerait simplement comme [inintelligible].
Ce logiciel peut-il gérer différentes langues et accents ?
La plupart des services de transcription de premier plan gèrent une multitude de langues, mais les performances peuvent être mitigées. Vérifiez toujours la liste des langues prises en charge par le fournisseur, mais plus important encore, effectuez un test rapide avec un court fichier audio dans votre langue cible pour voir la précision réelle par vous-même.
Les accents sont une tout autre affaire. Ils représentent un défi majeur pour les systèmes automatisés.
Bien que de nombreuses plateformes s'améliorent avec l'anglais américain ou britannique standard, les dialectes régionaux prononcés ou les accents non natifs peuvent faire chuter la précision.
Si votre recherche dépend de l'analyse des dialectes, des accents ou des nuances linguistiques, un transcripteur humain spécialisé dans ce dialecte spécifique est presque toujours le meilleur choix. Un algorithme peut facilement manquer les détails subtils mais significatifs que vous recherchez.
Quelle est la meilleure façon de formater les transcriptions pour le codage ?
Le format parfait dépend vraiment de votre plan d'analyse et du logiciel d'analyse qualitative des données (QDAS) que vous utilisez, comme NVivo ou ATLAS.ti. Pour la plupart des projets, cependant, plus c'est simple, mieux c'est.
Voici quelques bonnes pratiques pour vous assurer que vos transcriptions fonctionnent bien avec votre QDAS :
- Étiquettes de locuteurs claires : La cohérence est primordiale. Utilisez les mêmes étiquettes, comme "Interviewer" et "Participant 1", pour chaque fichier.
- Horodatages fréquents : Ajouter des horodatages à intervalles réguliers (par exemple, toutes les 30 à 60 secondes) ou à chaque changement de locuteur est une aubaine. Cela vous permet de cliquer sur un extrait de texte et de sauter instantanément à ce moment précis de l'audio dans votre logiciel d'analyse.
- Formats d'exportation simples : Tenez-vous-en aux bases. L'exportation en fichier .docx ou .txt garantit une importation propre, sans problèmes de formatage étranges qui pourraient perturber votre logiciel.
Cette capacité à synchroniser le texte et l'audio est de l'or pur lorsque vous avez besoin de vérifier le ton d'un participant, de vérifier le contexte ou de déterminer ce qui a été dit dans une phrase marmonnée pendant le processus de codage.
Vaut-il vraiment la peine de payer pour un logiciel de transcription ?
La tentation du "gratuit" est forte, mais pour tout projet qualitatif sérieux, un service payant est un investissement qui rapporte. Les outils gratuits ont souvent des coûts cachés qui peuvent sérieusement compromettre votre recherche.
Voici ce que vous rencontrez souvent avec les services gratuits :
- Précision réduite : Ils utilisent des modèles d'IA plus anciens et moins sophistiqués, ce qui signifie plus d'erreurs et plus de temps passé sur des corrections manuelles.
- Fonctionnalités limitées : Vous trouverez probablement aucune identification de locuteur, des limites de taille de fichier minuscules et des options d'exportation basiques.
- Risques majeurs pour la confidentialité : C'est le point le plus important. De nombreux outils gratuits se financent en utilisant vos données confidentielles pour entraîner leur IA. Pour toute recherche impliquant des participants humains, c'est une violation éthique massive.
Un service payant réputé vous offre une précision plus élevée et des fonctionnalités indispensables, mais il offre également une sécurité solide et une politique de confidentialité des données claire. Il vous fait gagner énormément de temps, protège l'intégrité de votre recherche et vous aide à respecter vos obligations éthiques.
Prêt à rendre vos données prêtes pour l'analyse en quelques minutes, pas en quelques jours ? Transcript.LOL est conçu pour les chercheurs. Nous offrons une transcription rapide, précise et sécurisée avec des fonctionnalités telles que l'identification des locuteurs, un vocabulaire personnalisé et des exportations flexibles. Plus important encore, nous avons une politique stricte de non-formation pour protéger la confidentialité de vos participants.