Transcription vocale pour vidéo : transcriptions rapides et précises
Découvrez comment la transcription vocale pour vidéo améliore l'accessibilité, fait gagner du temps et élargit la portée grâce à des étapes pratiques pour les créateurs.
Praveen
October 30, 2024
Avez-vous déjà essayé de trouver une citation spécifique enfouie quelque part dans un webinaire de deux heures ? C'est un cauchemar. La reconnaissance vocale pour la vidéo résout complètement ce problème en transformant chaque mot prononcé en une transcription consultable et utilisable. C'est comme donner à toute votre bibliothèque vidéo son propre moteur de recherche puissant.
Transformez le dialogue de vos vidéos en contenu consultable

Sans transcription, toutes les informations précieuses prononcées dans vos vidéos restent enfermées. Pensez-y comme à une bibliothèque remplie de livres non écrits : le savoir est là, mais bonne chance pour trouver une phrase spécifique. Cette technologie inverse complètement la donne, transformant le dialogue en données que vous pouvez réellement utiliser.
Ce simple changement rend votre contenu plus découvrable, accessible et précieux. Il permet d'économiser d'innombrables heures pour les créateurs de contenu, les chercheurs et les équipes marketing qui n'ont plus à parcourir manuellement des heures de séquences juste pour trouver un petit extrait.
Fonctionnalités clés basées sur l'IA pour une transcription vidéo plus intelligente
IA de pointe
Alimenté par Whisper d'OpenAI pour une précision de premier plan. Prise en charge des vocabulaires personnalisés, des fichiers jusqu'à 10 heures et des résultats ultra rapides.

Importer depuis plusieurs sources
Importez des fichiers audio et vidéo depuis diverses sources, y compris le téléchargement direct, Google Drive, Dropbox, les URL, Zoom et plus encore.
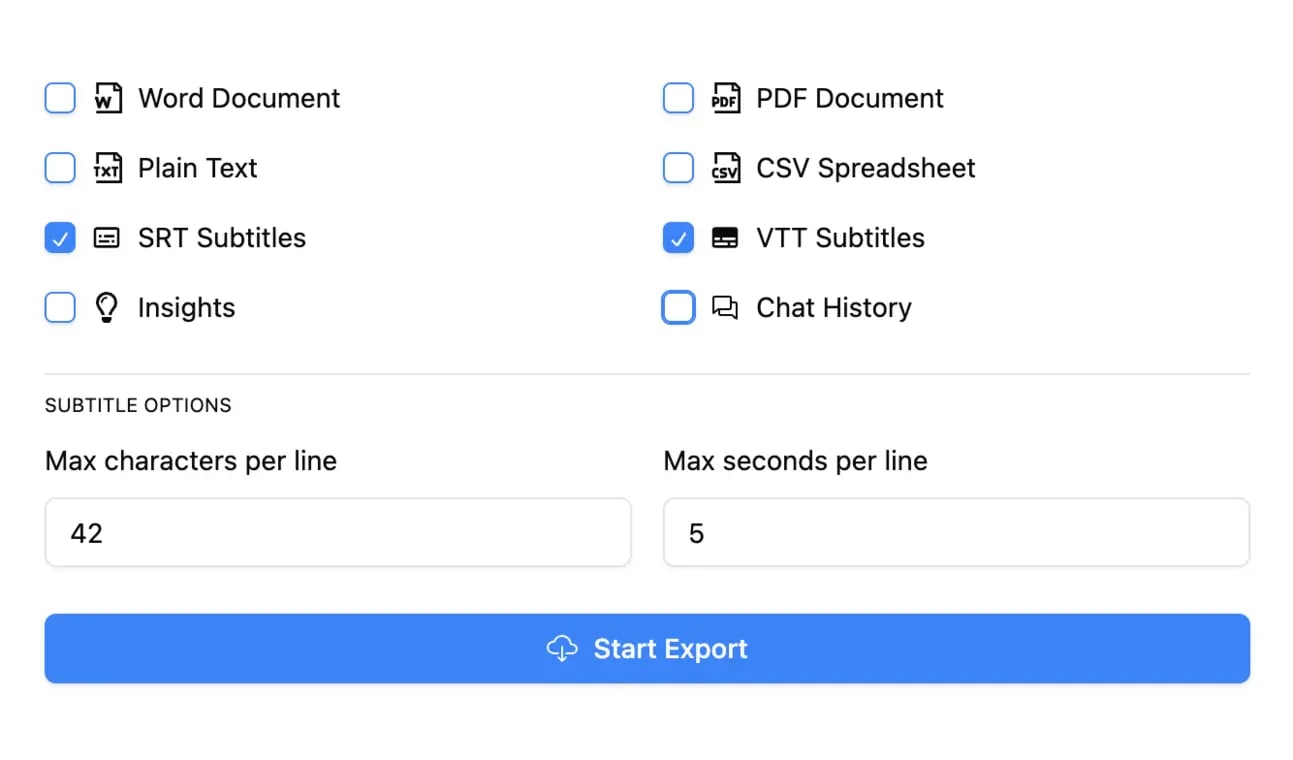
Exporter en plusieurs formats
Exportez vos transcriptions en plusieurs formats dont TXT, DOCX, PDF, SRT et VTT avec des options de formatage personnalisables.
La demande croissante de vidéos transcrites
Le besoin de transcription automatisée explose. Le marché mondial des API de reconnaissance vocale (speech-to-text), qui est le moteur de cette technologie, était évalué à environ 5 milliards USD en 2024 et devrait atteindre 21 milliards USD d'ici 2034.
Cette croissance n'est pas une simple hausse aléatoire ; elle témoigne d'un changement clair dans la manière dont nous traitons la vidéo. Au lieu de considérer la vidéo comme une boîte noire, les outils modernes en libèrent tout le potentiel. En convertissant le dialogue de votre vidéo en texte, vous créez une base pour toutes sortes de nouvelles stratégies de contenu. Si vous souhaitez approfondir le sujet, consultez notre guide sur les avantages de la conversion vidéo en texte.
Le contenu vidéo croît plus rapidement que le contenu textuel, et les entreprises se tournent vers des données vidéo structurées et consultables. La technologie de reconnaissance vocale garantit que vous ne perdez jamais d'informations précieuses enfouies dans les enregistrements. Elle améliore également l'efficacité des équipes en transformant l'audio non structuré en informations exploitables et lisibles.
Point clé : Convertir la parole en texte pour la vidéo ne consiste pas seulement à créer des sous-titres ; il s'agit de rendre toute votre bibliothèque vidéo aussi consultable et utile qu'un document texte.
Alors, qu'est-ce que cela signifie concrètement pour vous ? Voici un rapide aperçu des avantages immédiats que vous obtenez en transformant les paroles de votre vidéo en texte.
| Avantage | Impact sur votre contenu |
|---|---|
| SEO amélioré | Les moteurs de recherche ne peuvent pas regarder de vidéos, mais ils peuvent explorer du texte. Une transcription rend votre vidéo indexable, l'aidant à se classer pour les mots-clés pertinents. |
| Accessibilité améliorée | Les transcriptions et les légendes rendent votre contenu accessible aux personnes sourdes ou malentendantes, garantissant que vous respectez des normes telles que l'ADA. |
| Réutilisation de contenu sans effort | Une seule transcription vidéo peut être transformée en articles de blog, extraits pour les réseaux sociaux, newsletters par e-mail et notes d'émission avec un minimum d'effort. |
| Meilleur engagement des utilisateurs | Les légendes et les transcriptions consultables maintiennent l'engagement des spectateurs, en particulier ceux qui regardent dans des environnements sans son (ce qui représente beaucoup de monde !). |
Ce processus débloque plusieurs avantages considérables pour quiconque travaille avec des vidéos. L'une des utilisations les plus courantes et les plus puissantes est de rendre votre contenu plus accessible et plus engageant. Pour tirer le meilleur parti de vos dialogues, il vaut la peine d'explorer les meilleures applications pour générer des légendes vidéo.
Comment l'IA apprend réellement à comprendre vos vidéos

La technologie derrière la reconnaissance vocale pour la vidéo n'est pas magique, c'est un processus d'apprentissage sophistiqué qui ressemble beaucoup à la façon dont nous apprenons une langue. Pensez à l'enseignement de la lecture à un enfant. Cela commence par des sons individuels (lettres), puis se construit pour former des mots entiers, et enfin, il comprend des phrases entières parce qu'il en saisit le contexte.
L'IA suit un chemin étonnamment similaire. L'ensemble de l'opération est alimenté par une technologie appelée Reconnaissance Automatique de la Parole (ASR). La première tâche du système ASR est d'écouter l'audio de votre vidéo et de le découper en plus petites unités sonores possibles, ou phonèmes. Il apprend essentiellement à faire la différence entre le "c" de "chat" et le "ch" de "chapeau".
Des sons aux phrases
Une fois que l'audio est décomposé en ces minuscules morceaux, le véritable entraînement de l'IA commence. Les modèles de transcription modernes, comme Whisper d'OpenAI, sont alimentés par une quantité ahurissante de données audio, nous parlons de centaines de milliers d'heures extraites d'Internet. Cette immense bibliothèque est ce qui apprend à l'IA à mapper ces sons phonétiques aux mots écrits.
Ces données d'entraînement sont incroyablement diverses, couvrant d'innombrables accents, vitesses de parole et bruits de fond. C'est ainsi que l'IA peut comprendre quelqu'un avec un fort accent écossais aussi bien que quelqu'un qui parle un anglais de diffusion parfait. C'est là que les outils d'aujourd'hui se démarquent vraiment, allant bien au-delà de la dictée de base pour saisir les véritables nuances de la parole humaine.
Vous pouvez voir comment tout cet entraînement porte ses fruits en consultant la manière dont les meilleurs logiciels de transcription alimentés par l'IA atteignent une telle précision aujourd'hui.
Le contexte est primordial : Le véritable génie de l'IA réside dans sa capacité à comprendre le contexte. Lorsque vous dites : « Je dois aller à la banque », le modèle utilise les mots autour de « à » pour savoir qu'il ne s'agit pas de « deux » ou « tout ».
Pourquoi le contexte est important dans la transcription
Comprendre l'intention
Les modèles d'IA analysent les mots environnants pour déterminer si vous vouliez dire « banque » (institution financière) ou « banque » (verbe, s'appuyer), préservant ainsi le sens à travers les phrases.
Gérer les accents
Le contexte aide le modèle à faire des prédictions plus précises, même lorsque les accents ou la prononciation varient considérablement entre les locuteurs.
Corriger les mots ambigus
Des mots comme « et », « est », « ai » sont automatiquement corrigés en fonction des modèles contextuels appris à partir de vastes ensembles de données.
Améliorer la fluidité des phrases
La compréhension contextuelle aide à générer une ponctuation et une structure naturelles, rendant les transcriptions plus faciles à lire et à utiliser.
La puissance des ensembles de données massifs
Le volume colossal de données d'entraînement est ce qui fait la différence entre une transcription approximative et une transcription quasi parfaite. L'IA a entendu tellement de discours humains qu'elle peut faire des suppositions incroyablement intelligentes, même lorsque la qualité audio est loin d'être idéale.
Elle apprend à ignorer une toux, à filtrer une sirène lointaine, et même à identifier correctement le jargon industriel qu'elle a déjà entendu. L'ensemble de ce processus est un exemple fantastique d'automatisation intelligente, où une tâche sérieusement complexe est traitée avec une vitesse et une précision incroyables.
Le parcours de votre vidéo, de l'envoi à la transcription
Vous êtes-vous déjà demandé ce qui se passe réellement après avoir cliqué sur "envoyer" pour un fichier vidéo ? Ce n'est pas une seule étape magique, c'est plutôt une chaîne d'assemblage à plusieurs étapes qui transforme vos séquences brutes en une transcription polie et utilisable.
Parcourons l'ensemble du processus, étape par étape. Imaginons que nous suivions une vidéo de témoignage client depuis le moment où vous l'envoyez jusqu'à l'exportation finale, parfaitement formatée.
Traitement initial et extraction audio
Le voyage commence dès que vous confiez votre fichier. Que vous le fassiez glisser-déposer directement ou que vous le liaisiez depuis un lecteur cloud, le premier travail du système est le triage.
Il se met immédiatement au travail pour isoler la piste audio de la vidéo. Pensez-y comme un chef qui sépare les jaunes d'œufs des blancs ; l'IA n'a besoin que de l'audio pour faire son travail. Cet audio est ensuite standardisé et décomposé en morceaux plus petits et plus gérables, le préparant pour l'événement principal.
Le cœur de la transcription par IA
Une fois l'audio préparé et prêt, il est envoyé au moteur principal de reconnaissance vocale automatique (ASR). C'est là que se fait le gros du travail.
L'IA "écoute" les morceaux audio, faisant correspondre rapidement les sons phonétiques aux mots qu'elle reconnaît dans sa bibliothèque d'entraînement massive. Elle produit un fichier texte brut et non formaté, la première ébauche. Ce résultat initial est souvent étonnamment précis, mais il manque encore des détails clés comme les étiquettes de locuteur et une ponctuation parfaite. C'est là qu'interviennent les étapes suivantes.

Détection des intervenants
Identifiez automatiquement les différents intervenants dans vos enregistrements et étiquetez-les avec leurs noms.
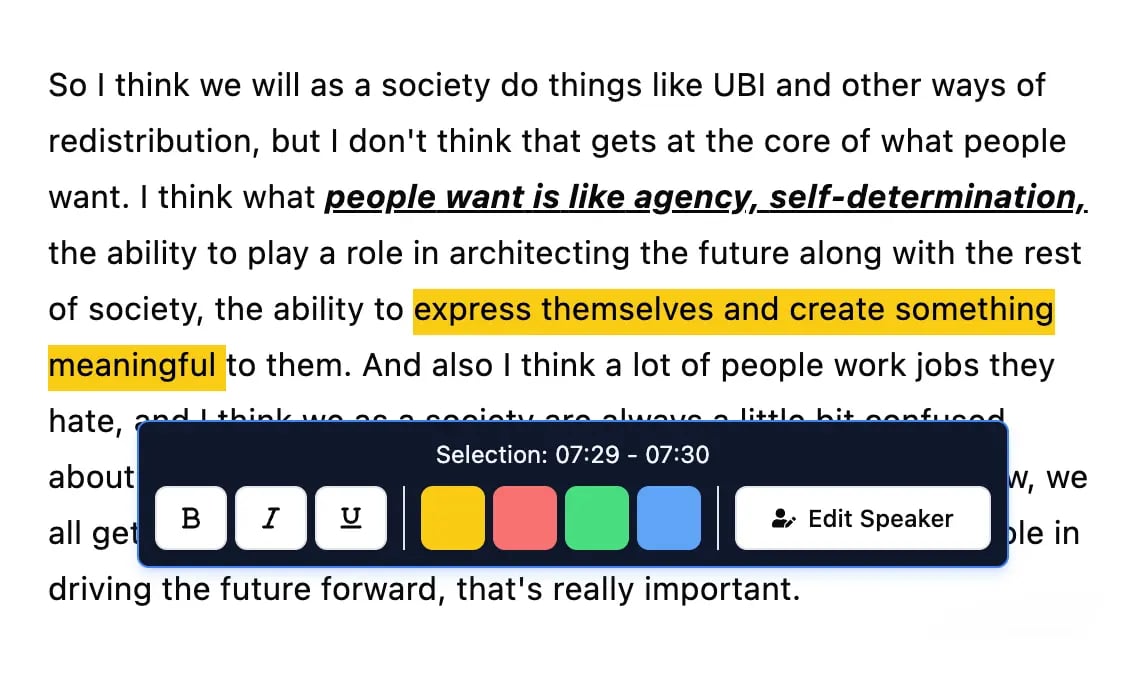
Outils d'édition
Modifiez les transcriptions avec des outils puissants incluant rechercher et remplacer, attribution des intervenants, formats de texte enrichi et surlignage.
Résumés et Chatbot
Générez des résumés et d'autres analyses de votre transcription, des prompts personnalisés réutilisables et un chatbot pour votre contenu.
La demande pour cette technologie explose. Le marché de la transcription par IA devrait atteindre 19,2 milliards USD d'ici 2034, démontrant à quel point ces outils sont devenus essentiels pour rendre le contenu vidéo accessible et consultable. Vous pouvez en savoir plus sur cette tendance sur Sonix.ai.
Détection et Étiquetage Intelligents des Locuteurs
Pour toute vidéo impliquant plus d'une personne — comme une interview, un podcast ou une table ronde — savoir qui a dit quoi est non négociable. C'est là qu'intervient une technologie intéressante appelée diarisation des locuteurs.
L'IA analyse les empreintes vocales uniques dans l'audio — hauteur, ton et rythme — pour déterminer qui parle. Elle attribue ensuite automatiquement des étiquettes génériques comme "Locuteur 1" et "Locuteur 2" aux bonnes lignes de dialogue. Dans un outil comme Transcript.LOL, vous pouvez ensuite facilement renommer ces étiquettes avec les noms des participants réels, transformant un bloc de texte confus en un script clair et professionnel.
Astuce de pro : Plus votre audio est clair, meilleure est la détection des locuteurs. Si possible, donnez à chaque personne son propre microphone. Cela fait une énorme différence en termes de précision.
La Phase d'Édition Interactive
Soyons honnêtes : aucune IA n'est parfaite. Elle peut mal entendre un nom d'entreprise unique, avoir du mal avec un accent prononcé, ou se tromper sur un jargon technique. C'est pourquoi la phase d'édition est si importante — elle vous remet aux commandes.
Un bon éditeur interactif vous permet de cliquer sur n'importe quel mot de la transcription et de sauter instantanément à ce moment précis de la vidéo. Cela rend la correction des erreurs un jeu d'enfant. Vous pouvez corriger les noms, ajuster la ponctuation et corriger les termes techniques en quelques secondes, pas en quelques heures. De plus, obtenir les horodatages corrects est crucial pour créer des sous-titres parfaitement synchronisés. Nous approfondissons l'importance de l'obtention de transcriptions avec des timecodes dans notre guide dédié.
Enfin, une fois votre transcription peaufinée et perfectionnée, vous êtes prêt à l'utiliser. Vous pouvez l'exporter dans une multitude de formats différents en fonction de vos besoins :
- Texte brut (TXT) : Simple et parfait pour l'intégrer dans des articles de blog, des articles ou des notes d'émission.
- Sous-titres (SRT/VTT) : Les fichiers standards avec horodatage dont vous avez besoin pour YouTube, Vimeo et les plateformes de médias sociaux.
- Documents (DOCX/PDF) : Idéal pour le partage avec votre équipe, l'archivage ou la création de dossiers officiels.
Moyens Pratiques de Maximiser la Précision de la Transcription
Obtenir une transcription quasi parfaite n'est pas seulement une question de logiciel ; c'est le résultat direct de la qualité de votre audio. Pensez-y comme un photographe travaillant avec la lumière — meilleure est la lumière, plus l'image finale est claire. Pour la reconnaissance vocale pour la vidéo, un bon audio est votre lumière.
Bien que les modèles d'IA actuels soient incroyablement puissants, ce ne sont pas des miracles. Ils ont besoin d'un signal propre pour donner le meilleur d'eux-mêmes. Quelques ajustements simples avant d'appuyer sur enregistrer peuvent faire une énorme différence dans la qualité de votre transcription finale, vous faisant gagner beaucoup de temps d'édition par la suite.
C'est le parcours de base de votre vidéo pour devenir une transcription peaufinée.
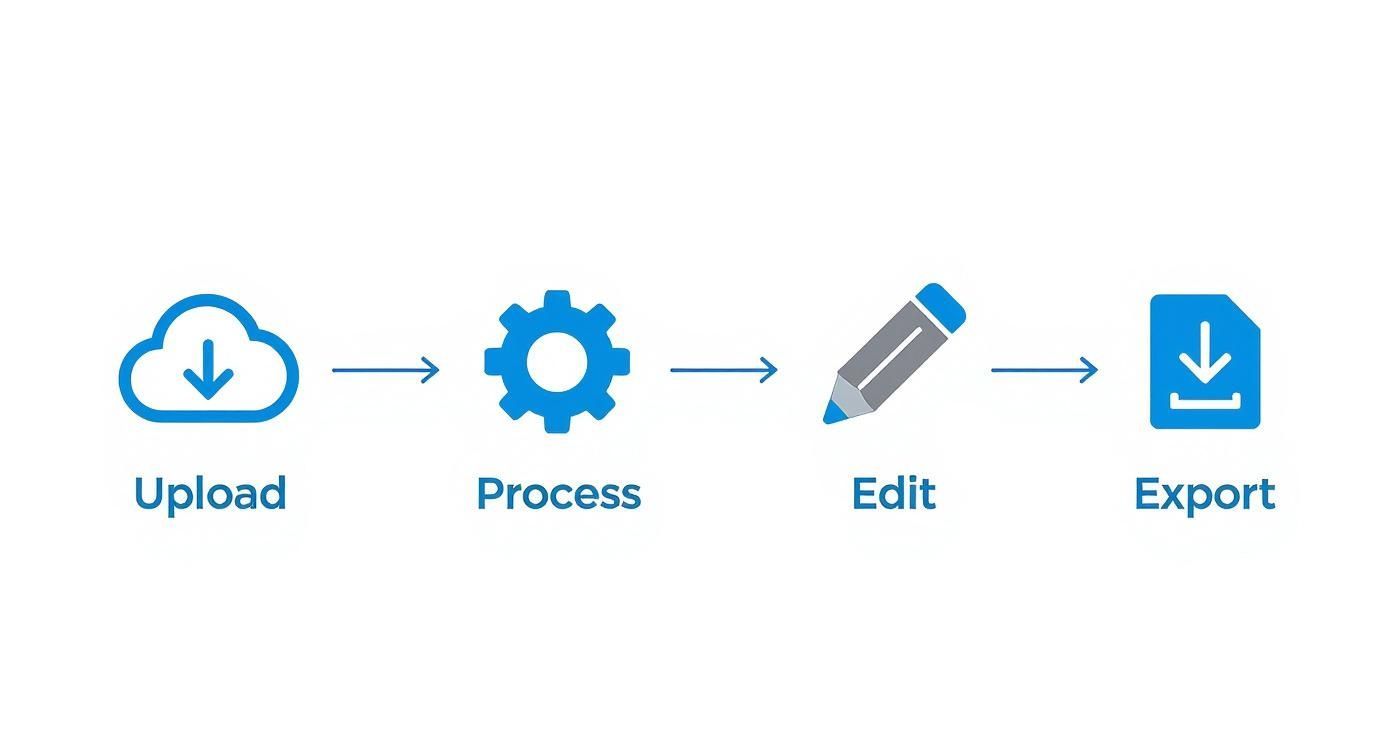
Ce qu'il faut retenir, c'est que l'étape de 'Traitement' n'est aussi bonne que l'étape de 'Téléchargement' qui la alimente. Prendre quelques mesures proactives garantit que l'IA dispose du meilleur matériel possible dès le départ.
Contrôlez Votre Environnement d'Enregistrement
Votre première priorité est d'éliminer le bruit de fond. Ce climatiseur qui ronronne, une conversation dans la pièce voisine, ou même l'écho dans un grand espace vide peuvent brouiller l'audio. Lorsque cela se produit, l'IA doit travailler plus dur pour séparer les voix du bruit, c'est là que les erreurs se glissent.
Essayez ces conseils simples pour lutter contre cela :
- Choisissez un endroit calme : Enregistrez dans une petite pièce remplie de surfaces douces comme des tapis, des rideaux ou des meubles. Ces éléments absorbent le son et réduisent l'écho.
- Éteignez les distractions : Mettez votre téléphone en silence et éteignez tous les appareils qui créent un bourdonnement faible, comme les ventilateurs ou les réfrigérateurs.
- Vérifiez votre distance : Rapprochez le microphone de la bouche du locuteur — idéalement à une distance de six à douze pouces. Cela vous donne un signal clair et fort, facile à transcrire.
Investissez dans un Microphone Décent
Le microphone intégré de votre ordinateur portable ou de votre appareil photo est conçu pour capter le son de toutes les directions. C'est idéal pour capter l'ambiance d'une pièce, mais terrible pour enregistrer un dialogue clair. Il captera toujours plus de bruit de fond qu'un microphone dédié.
Vous n'avez pas besoin de vous ruiner pour constater une amélioration considérable. Un microphone-cravate (lavalier) abordable ou un simple microphone USB peut considérablement améliorer la clarté en se concentrant directement sur la voix du locuteur. Cette seule mise à niveau est souvent le changement le plus impactant que vous puissiez faire. Vous pouvez en savoir plus sur la façon dont différents facteurs affectent les résultats en lisant notre guide sur l'amélioration de la précision de la reconnaissance vocale.
Impact réel : Une transcription d'un microphone d'ordinateur portable dans un café bruyant pourrait n'atteindre que 70-80 % de précision, vous laissant un travail d'édition conséquent. La même conversation enregistrée avec un microphone-cravate de 20 $ pourrait facilement atteindre 95 % de précision ou plus, vous donnant un brouillon quasi parfait dès le départ.
La qualité audio est importante
Une mauvaise qualité audio — écho, bruits de fond, vent, locuteurs qui se chevauchent — réduira considérablement la précision de la transcription. Même les meilleurs systèmes ASR ont du mal avec une entrée peu claire. Privilégiez toujours un audio propre et direct pour éviter des corrections manuelles importantes par la suite.
Faites attention à vos habitudes de parole
La façon dont vous parlez est aussi importante que votre équipement. Marmonner, parler trop vite ou se couper la parole sont des causes fréquentes de mauvaises transcriptions. L'IA se perd lorsque les voix se chevauchent, rendant presque impossible de séparer correctement les dialogues.
Encouragez les intervenants à s'exprimer clairement et, surtout, à parler à tour de rôle. Une petite discipline pendant la session d'enregistrement est très rentable lors de la génération de la transcription. En vous concentrant sur la capture d'un audio propre, vous donnez à l'IA la meilleure chance possible d'obtenir un résultat impeccable.
Flux de travail concrets pour les créateurs et les équipes
La vraie magie de la reconnaissance vocale pour la vidéo n'est pas la technologie elle-même, c'est ce que vous pouvez en faire. Les professionnels de tous les domaines construisent des moyens de travail plus intelligents et plus rapides en transformant les mots prononcés en données qu'ils peuvent réellement utiliser. Dépassons la théorie et voyons comment de vraies équipes utilisent les transcriptions pour accomplir des tâches.
Ce n'est pas juste une tendance de niche ; cela devient central dans la façon dont le contenu moderne est créé. Le marché mondial de la reconnaissance vocale et de la parole était évalué à 15,46 milliards USD en 2024 et est en passe d'atteindre l'incroyable somme de 81,59 milliards USD d'ici 2032. Cette explosion montre à quel point nous dépendons de la transcription pour tout, de la création de contenu accessible au maintien de l'engagement du public. Vous pouvez découvrir plus d'informations sur cette tendance du marché et ce qui la motive.
Les spécialistes du marketing de contenu réutilisent à grande échelle
Pour tout spécialiste du marketing de contenu, un seul webinaire vidéo est une mine d'or. Mais y creuser manuellement pour trouver les bonnes informations est un travail lent et pénible. Une fois que vous avez une transcription précise, tout change.
Un webinaire d'une heure peut être instantanément transformé en un article de blog optimisé pour le SEO, déjà rempli de titres et de citations riches en mots-clés. Les spécialistes du marketing peuvent ensuite sélectionner les meilleures citations et les transformer en des dizaines de publications sur les réseaux sociaux, des extraits de newsletters par e-mail, ou même le script d'une courte vidéo promotionnelle. Il s'agit de multiplier le retour sur investissement de chaque vidéo que vous créez.
Les chercheurs UX découvrent des informations plus rapidement
Les chercheurs en expérience utilisateur (UX) vivent des entretiens avec les clients, essayant de trouver ces moments "aha !" qui mènent à de meilleurs produits. Le plus grand goulot d'étranglement ? Passer au crible des heures d'enregistrements juste pour trouver cette citation qui change la donne.
Les transcriptions de la reconnaissance vocale rendent tout ce processus incroyablement efficace. Les chercheurs peuvent rechercher dans un entretien entier des mots-clés comme "frustrant" ou "confus" pour trouver les points de douleur en quelques secondes. Ils peuvent copier-coller des citations clients puissantes directement dans leurs rapports, donnant à leurs conclusions le poids de preuves authentiques et convaincantes. Cela raccourcit le cycle de recherche et aide les équipes à construire des produits basés sur ce que les utilisateurs disent réellement.
Les moteurs de transcription de nouvelle génération incluent désormais des capacités de recherche sémantique, permettant aux équipes de rechercher non seulement des mots-clés, mais aussi des idées et des thèmes dans les transcriptions. Cette mise à jour améliore considérablement la rapidité avec laquelle les informations peuvent être extraites de longues sessions d'interview.
Transformation du flux de travail : Au lieu de passer des heures à éplucher des vidéos, les chercheurs peuvent trouver les thèmes clés en quelques minutes. Un processus qui prenait autrefois des jours peut maintenant être réalisé en un seul après-midi.
Éducateurs et formateurs créant des cours accessibles
Dans l'éducation et la formation en entreprise, l'accessibilité n'est pas seulement un avantage, c'est souvent une exigence légale. Fournir des sous-titres précis pour les cours vidéo est crucial pour les apprenants sourds ou malentendants, et cela aide franchement tout le monde en améliorant la concentration et la rétention.
La génération de transcriptions avec un outil comme Transcript.LOL permet aux éducateurs de créer des fichiers de sous-titres SRT ou VTT parfaitement synchronisés avec un minimum d'effort. Cela garantit que leur contenu est inclusif et respecte les normes d'accessibilité. De plus, une transcription consultable devient un puissant outil d'étude, permettant aux apprenants de sauter à des sujets spécifiques dans une longue conférence sans avoir à la revoir entièrement.
Des questions ? Nous avons des réponses.
Même après avoir maîtrisé le flux de travail, il est normal d'avoir quelques questions sur le fonctionnement réel de la reconnaissance vocale pour la vidéo. C'est un outil puissant, mais comprendre les détails vous permet d'en tirer le meilleur parti. Voici quelques réponses claires aux questions que nous posent le plus souvent les créateurs et les équipes.
Celles-ci couvrent l'essentiel, de ce à quoi s'attendre en termes de performances aux différences pratiques entre une transcription et un fichier de sous-titres. Bien comprendre cela est essentiel pour construire un flux de travail vidéo efficace.
Quelle est la précision de tout cela, vraiment ?
La transcription IA moderne peut atteindre plus de 95 % de précision sur un audio de haute qualité. Mais "haute qualité" est la phrase clé. Le résultat final dépend toujours de la clarté de votre audio source.
Quelques éléments peuvent perturber l'IA :
- Clarté audio : Un son net, propre et sans distorsion est primordial.
- Bruit de fond : Les cafés bruyants, la musique de fond ou les personnes qui parlent en même temps peuvent brouiller les pistes.
- Accents prononcés : Bien que les modèles actuels soient impressionnants avec les accents, les dialectes très forts ou uniques peuvent encore causer quelques ratés.
- Jargon spécifique : Les termes spécifiques à une industrie ou les noms de produits uniques peuvent être mal orthographiés si l'IA ne les a jamais rencontrés auparavant.
Pour un podcast bien enregistré, la transcription que vous obtenez est souvent presque parfaite. Pour quelque chose de plus chaotique, comme un appel de conférence avec des personnes qui parlent en même temps, l'IA vous donne une première ébauche fantastique que vous pouvez peaufiner en quelques minutes à l'aide d'un éditeur interactif.
Peut-il identifier qui parle dans une vidéo ?
Oui, absolument. Cette fonctionnalité change complètement la donne pour les interviews, les réunions et les tables rondes. Le terme technique est la diarisation des locuteurs.
Les plateformes avancées peuvent détecter automatiquement quand une nouvelle personne commence à parler et l'étiqueter en conséquence, comme "Locuteur 1", "Locuteur 2", etc.
C'est essentiel pour tout contenu comportant plus d'une voix, y compris :
- Interviews
- Tables rondes
- Réunions d'équipe
- Appels de support client
Une fois la transcription générée, vous pouvez accéder à l'éditeur et remplacer ces étiquettes génériques par les noms réels des locuteurs. Le résultat est un script propre et parfaitement formaté qui indique clairement qui a dit quoi.
Quelle est la différence entre les transcriptions et les sous-titres ?
Cela confond les gens tout le temps. Bien qu'ils proviennent tous deux du même audio, les transcriptions et les sous-titres sont conçus pour des tâches complètement différentes. Vous devez savoir lequel utiliser pour votre objectif spécifique.
Une transcription est le texte intégral de tout ce qui a été dit, généralement dans un seul document avec des étiquettes de locuteurs. C'est parfait pour le SEO, pour transformer une vidéo en article de blog, ou pour effectuer des recherches approfondies sur le contenu.
Les sous-titres (ou légendes) sont des fichiers texte, comme SRT ou VTT, qui sont horodatés pour apparaître à l'écran en synchronisation avec la vidéo. Leur objectif principal est l'accessibilité pour les spectateurs sourds, malentendants, ou qui regardent simplement sans le son – ce qui représente la plupart des gens sur les réseaux sociaux aujourd'hui.
Distinction clé : Pensez-y ainsi : une transcription sert à lire et rechercher le contenu après coup. Les sous-titres servent à le regarder et le comprendre en temps réel. Tout bon service vous permettra d'exporter les deux.
Quelle est la sécurité de mon contenu ?
Tout service réputé donne la priorité à la sécurité et à la confidentialité des données. Point final. Ils devraient utiliser des connexions cryptées (comme SSL/TLS) pour tous les téléchargements de fichiers et stocker vos données dans des environnements cloud sécurisés, conformes aux normes de l'industrie.
Avant de vous inscrire, vérifiez toujours une politique de confidentialité transparente qui explique exactement comment vos données sont traitées, qui peut les consulter et combien de temps elles sont conservées. Si vous traitez du contenu sensible d'ordre professionnel, juridique ou personnel, recherchez des services conformes à des normes telles que le RGPD ou le SOC 2. Cela garantit qu'ils respectent les normes de sécurité les plus élevées. Votre contenu ne devrait jamais être utilisé pour entraîner des modèles d'IA sans votre permission explicite.
Prêt à transformer vos vidéos en contenu précis, consultable et réutilisable en quelques secondes ? Transcript.LOL propose une plateforme alimentée par l'IA avec détection des locuteurs, un éditeur interactif et plusieurs options d'exportation pour rationaliser votre flux de travail. Essayez-le gratuitement dès aujourd'hui sur https://transcript.lol.