Software di trascrizione per la ricerca qualitativa
Scopri il miglior software di trascrizione per la ricerca qualitativa. Questa guida copre accuratezza, integrazione del flusso di lavoro e privacy dei dati per uso accademico.
Praveen
November 20, 2024
Scegliere il software di trascrizione giusto per la ricerca qualitativa è più di un semplice passaggio logistico: è il fondamento della tua intera analisi. Se lo fai bene, avrai un testo strutturato e ricercabile che accelera le tue intuizioni. Se lo fai male, ti troverai ad affrontare ore di noiose correzioni.
Questa scelta influisce direttamente sull'integrità dei tuoi dati e sull'efficienza del tuo flusso di lavoro. Si tratta di bilanciare accuratezza, funzionalità specifiche per la ricerca e una solida sicurezza dei dati.
Scegliere il Software di Trascrizione Giusto per la Tua Ricerca
La ricerca qualitativa vive nelle sfumature. Sono le pause sottili, il dialogo sovrapposto e il gergo specifico che rivelano ciò che sta realmente accadendo. Il tuo software di trascrizione non è solo uno strumento; è un partner nel catturare quella ricchezza. Una scelta sbagliata può introdurre imprecisioni che distorcono i tuoi risultati o, peggio ancora, compromettere la riservatezza dei partecipanti.
Una delle prime cose che dovrai decidere è se optare per un servizio AI puramente automatizzato o per una piattaforma che prevede un intervento umano per la revisione. L'AI ha fatto molta strada, ma può ancora inciampare su gergo accademico, accenti marcati o registrazioni in un caffè rumoroso. È qui che il tocco umano fornisce uno strato vitale di controllo qualità.
Funzionalità Essenziali di Cui Ogni Ricercatore Ha Bisogno
Quando stai valutando il software di trascrizione per la ricerca qualitativa, devi pensare oltre la semplice conversione da voce a testo. Il tuo obiettivo è trovare funzionalità che rendano effettivamente più semplice la fase di analisi.
Ecco i requisiti irrinunciabili:
Capacità di trascrizione essenziali per i ricercatori
IA all'avanguardia
Alimentato da Whisper di OpenAI per una precisione leader nel settore. Supporto per vocabolari personalizzati, file fino a 10 ore e risultati ultra rapidi.

Importa da più fonti
Importa file audio e video da varie fonti tra cui caricamento diretto, Google Drive, Dropbox, URL, Zoom e altro.
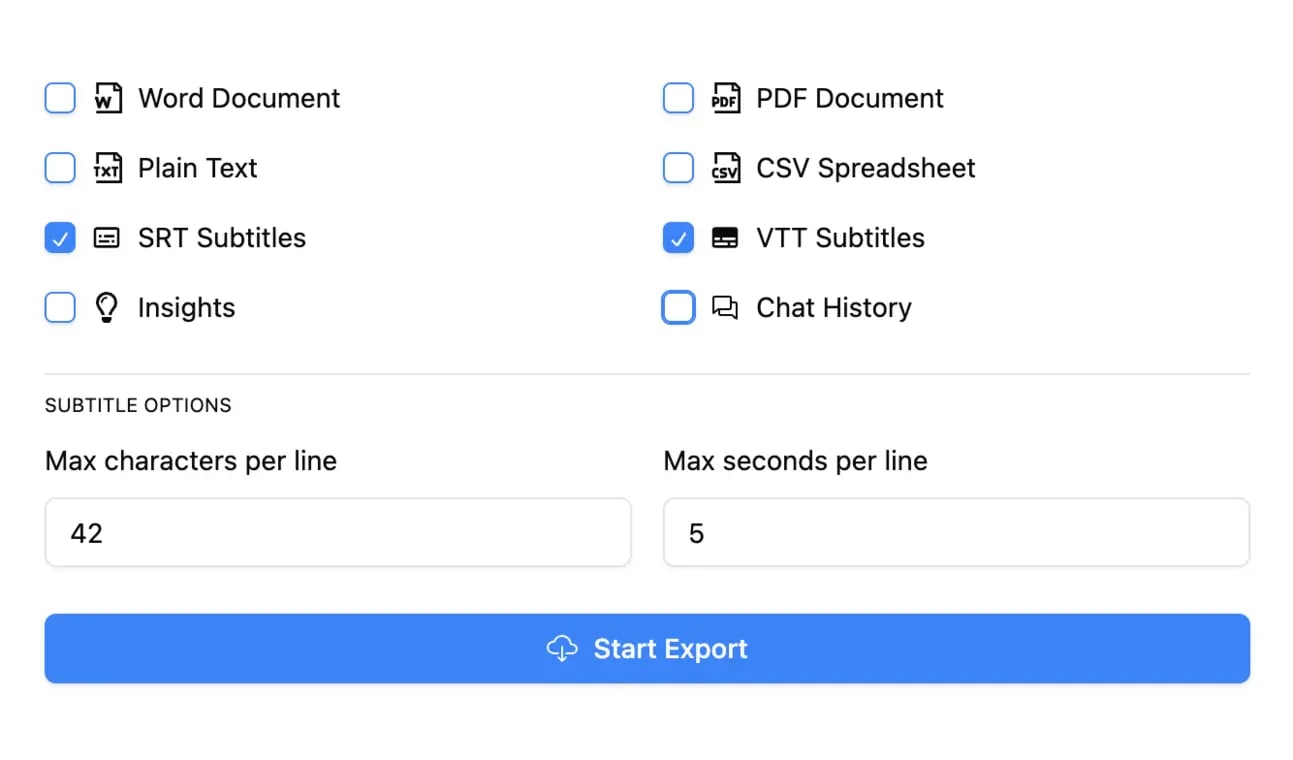
Esporta in più formati
Esporta le tue trascrizioni in più formati tra cui TXT, DOCX, PDF, SRT e VTT con opzioni di formattazione personalizzabili.
- Alta precisión: la transcripción debe ser un registro fiel de la conversación. Asegúrese de que el servicio pueda manejar su tema específico y las condiciones de audio.
- Etiquetado de hablante confiable: Absolutamente debe saber quién dijo qué, especialmente en grupos focales. La detección automática de hablantes ahorra mucho tiempo, pero debe ser fácil de editar cuando la IA se equivoca.
- Marcas de tiempo precisas: Las marcas de tiempo son su salvavidas, conectan el texto con el audio original. Así es como puede revisar rápidamente el tono de un participante o aclarar una frase murmurada directamente desde su software de análisis. Hemos escrito una guía completa sobre la importancia de la transcripción con código de tiempo si desea profundizar.
- Formatos de exportación flexibles: El software tiene que funcionar bien con su software de análisis de datos cualitativos (QDAS). Busque opciones de exportación sencillas como .docx o .txt que pueda cargar directamente en herramientas como NVivo, ATLAS.ti o Dedoose.
El objetivo es obtener una transcripción lista para codificar de inmediato, no una que necesite una reescritura completa. Cada minuto que pasa arreglando el formato o corrigiendo nombres es un minuto que no dedica al análisis.
Perché la formattazione pronta per la ricerca fa risparmiare settimane di lavoro?
Trascrizioni pulite riducono i tempi di configurazione all'interno del software di analisi qualitativa. Etichette dei relatori corrette, timestamp e semplici formati di esportazione consentono una codifica istantanea senza ristrutturare i file. Ciò accelera drasticamente la transizione dalla raccolta dati alla generazione di insight.
Quando sarai pronto a valutare diverse piattaforme, una semplice checklist ti aiuterà a concentrarti su ciò che conta veramente per la ricerca.
Checklist delle Funzionalità Principali per Software di Ricerca Qualitativa
| Funzionalità | Perché è Critica per i Ricercatori | Cosa Cercare |
|---|---|---|
| Alta Precisione | Spazzatura dentro, spazzatura fuori. Trascrizioni imprecise portano ad analisi errate e possono minare l'intero studio. | Tassi di precisione del 98%+; capacità di gestire gergo, accenti e rumori di fondo. |
| Etichettatura degli Oratori | Essenziale per tracciare il dialogo in interviste e focus group. Senza di essa, non puoi attribuire correttamente le citazioni. | Identificazione automatica di più oratori, facilmente modificabile. |
| Timestamp | Collega il testo all'audio originale per la verifica. Cruciale per controllare tono, emozione e contesto. | Timestamp a livello di parola o paragrafo facili da navigare. |
| Formati di Esportazione Multipli | Garantisce la compatibilità con il tuo software di analisi qualitativa preferito (QDAS). | Formati .docx, .txt e .srt che si importano in modo pulito in strumenti come NVivo o ATLAS.ti. |
| Sicurezza e Privacy dei Dati | La tua ricerca spesso coinvolge informazioni sensibili. Proteggere la riservatezza dei partecipanti è un must. | Politiche sulla privacy chiare, crittografia dei dati e conformità a standard come GDPR o HIPAA. |
Questa checklist non è esaustiva, ma copre le funzionalità principali che renderanno il tuo progetto un gioco da ragazzi o un incubo.
Chi trae maggior beneficio dalla trascrizione di livello di ricerca?
Ricercatori accademici
Converti interviste e focus group in set di dati strutturati per la codifica, l'analisi tematica e insight pronti per la pubblicazione.
Studenti di dottorato e master
Trasforma riunioni di supervisione registrate e interviste sul campo in materiali di studio organizzati e ricercabili.
Ricercatori UX e di mercato
Analizza le interviste ai clienti più velocemente con trascrizioni etichettate per relatore e con timestamp, pronte per il journey mapping
Analisti sanitari e politici
Elabora in modo sicuro interviste sensibili mantenendo rigorosa conformità e riservatezza.
Non è sorprendente che il mercato di questi strumenti sia in piena espansione. Il mercato della trascrizione negli Stati Uniti è stato valutato a 30,42 miliardi di dollari nel 2024 e si prevede che raggiungerà i 41,93 miliardi di dollari entro il 2030, con il software basato sull'intelligenza artificiale in testa. Questa crescita significa più opzioni per i ricercatori, ma significa anche che è necessario essere più attenti.
In definitiva, la scelta del software è una decisione strategica. Dando priorità alle funzionalità che supportano il duro lavoro dell'analisi qualitativa, imposti il tuo progetto per il successo fin dal primo giorno.
Decodificare le Dichiarazioni di Accuratezza nella Trascrizione AI
Nella ricerca qualitativa, l'accuratezza non è solo un numero: è la base assoluta della tua analisi. È la differenza tra catturare l'intuizione genuina di un partecipante e interpretare completamente male il suo significato. Si tratta di preservare quella precisa espressione, la pausa esitante o il chiacchiericcio sovrapposto che è ricco di dati preziosi.
Sebbene gli strumenti di trascrizione AI siano diventati incredibilmente potenti, il loro marketing può essere un campo minato per i ricercatori. Un'azienda potrebbe pubblicizzare "95% di accuratezza" sulla sua homepage, ma quel numero si basa quasi sempre su condizioni di laboratorio perfette: un singolo oratore chiaro senza rumori di fondo e senza terminologia complessa.
La ricerca qualitativa non avviene mai in un ambiente incontaminato come questo.
Il Divario di Accuratezza nel Mondo Reale
Siamo onesti, i nostri dati sono disordinati. Focus group, note sul campo etnografiche e persino interviste individuali sono piene di oratori multipli, accenti diversi, momenti emotivi e gergo accademico. In questi scenari reali, le prestazioni di un'IA possono precipitare, mettendo a serio rischio l'integrità dei tuoi dati.
Pensa a queste situazioni comuni in cui l'IA spesso inciampa:
- Interpretare male il sarcasmo: Un'IA trascriverà un commento sarcastico letteralmente, perdendo completamente il tono ironico e distorcendo l'intero significato della risposta del partecipante.
- Unire gli oratori: In un focus group frenetico, un'IA può facilmente confondersi e attribuire una citazione critica alla persona sbagliata.
- Ignorare i segnali non verbali: Un silenzio pensieroso (ad esempio, "[pausa 5s]") o una risata condivisa sono dati contestuali cruciali che i sistemi automatizzati quasi sempre perdono.
- Rovinare il gergo: Termini specializzati in medicina, legge o sociologia vengono spesso trascritti come qualsiasi sciocchezza fonetica che l'IA pensa di aver sentito, costringendoti a passare ore a ripulirli.
Questi non sono solo piccoli errori di battitura; sono eventi di corruzione dei dati. Possono portarti sulla strada sbagliata e direttamente a conclusioni errate. Ecco perché devi guardare oltre i numeri di marketing scintillanti e essere realistico riguardo ai limiti.
Gli errori dell'IA possono invalidare i risultati della ricerca
Anche piccoli errori di trascrizione possono distorcere il significato del partecipante, introdurre codici errati e indebolire la validità della ricerca. Senza revisione umana, le trascrizioni generate dall'IA possono silenziosamente introdurre bias e disinformazione nella tua analisi.
Perché l'86% è un voto insufficiente per la ricerca
Il salto dall'accuratezza della macchina all'accuratezza umana non è un piccolo passo, è un abisso massiccio nella qualità. Gli studi mostrano spesso che la trascrizione AI raggiunge un'accuratezza di circa l'86% in condizioni tipiche, non perfette. Per il lavoro qualitativo dove ogni singola parola conta, questo semplicemente non è abbastanza buono.
Confronta questo con i servizi professionali umani, che possono raggiungere un'accuratezza del 99,9%. Questo divario ha un impatto diretto sulla validità della tua analisi.
Un tasso di accuratezza dell'86% significa che, in media, 14 parole su 100 potrebbero essere sbagliate. In un'intervista di 30 minuti (circa 4.500 parole), ciò si traduce in oltre 600 errori potenziali. Correggere questo volume di errori non è solo noioso; è un'enorme attività di ricerca a sé stante.
L'errore più pericoloso non è quello palesemente ovvio. È l'errore sottile che sfugge, si insinua nel tuo codifica e viene trattato come un fatto.
Un approccio ibrido per proteggere il tuo lavoro
Questo non significa che l'AI sia inutile. Tutt'altro. Una trascrizione automatizzata può essere una fantastica prima bozza, specialmente quando hai un budget o una scadenza stretti. La chiave è trattarla esattamente come tale: una bozza che richiede una rigorosa revisione umana. Questo flusso di lavoro ibrido ti consente di ottenere la velocità dell'AI senza sacrificare l'integrità dei tuoi dati.
Per avere davvero un'idea di ciò che influenza i risultati, è utile comprendere i dettagli di ciò che rende accurata una trascrizione. Per un approfondimento, consulta la nostra guida su come viene misurata e migliorata l'accuratezza del parlato-testo.
Quando valuti software di trascrizione per la ricerca qualitativa, la tua scelta deve basarsi sul tuo progetto specifico. Se il tuo audio è cristallino e l'argomento è generale, l'AI potrebbe portarti la maggior parte della strada. Ma per la stragrande maggioranza dei progetti qualitativi, dove la sfumatura è tutto, allocare tempo per una revisione umana approfondita non è solo una buona pratica. È un obbligo etico nei confronti dei tuoi partecipanti e della tua ricerca.
Integrazione della trascrizione nel tuo flusso di lavoro di ricerca
Siamo onesti, la trascrizione è spesso vista come la parte noiosa della ricerca qualitativa: il compito che devi portare a termine prima che inizi l'analisi vera. Ma pensarla in questo modo è un errore.
Il tuo processo di trascrizione non è solo un compito; è il ponte critico tra l'audio grezzo e le intuizioni significative. Un flusso di lavoro goffo qui non solo spreca tempo, ma può introdurre errori e creare colli di bottiglia che fanno deragliare l'intero progetto. L'obiettivo reale è un flusso senza interruzioni dalla registrazione fino alla codifica.
Tutto questo si riduce a quanto bene il tuo software di trascrizione si integra con il tuo software di analisi dei dati qualitativi (QDAS). I grandi nomi come NVivo, ATLAS.ti e Dedoose sono costruiti per gestire testo strutturato, ma la qualità di quell'importazione dipende interamente dalla trascrizione che fornisci loro.
Oltre la semplice importazione ed esportazione
La vera integrazione è molto più che semplicemente scaricare un file di testo nel tuo QDAS. Si tratta di utilizzare le funzionalità del tuo strumento di trascrizione per rendere il processo di codifica più veloce, più accurato e, francamente, più piacevole.
Ecco cosa conta davvero per un passaggio fluido:
Integrazione del flusso di lavoro e strumenti di analisi

Rilevamento dei parlanti
Identifica automaticamente diversi parlanti nelle tue registrazioni e etichettali con i loro nomi.
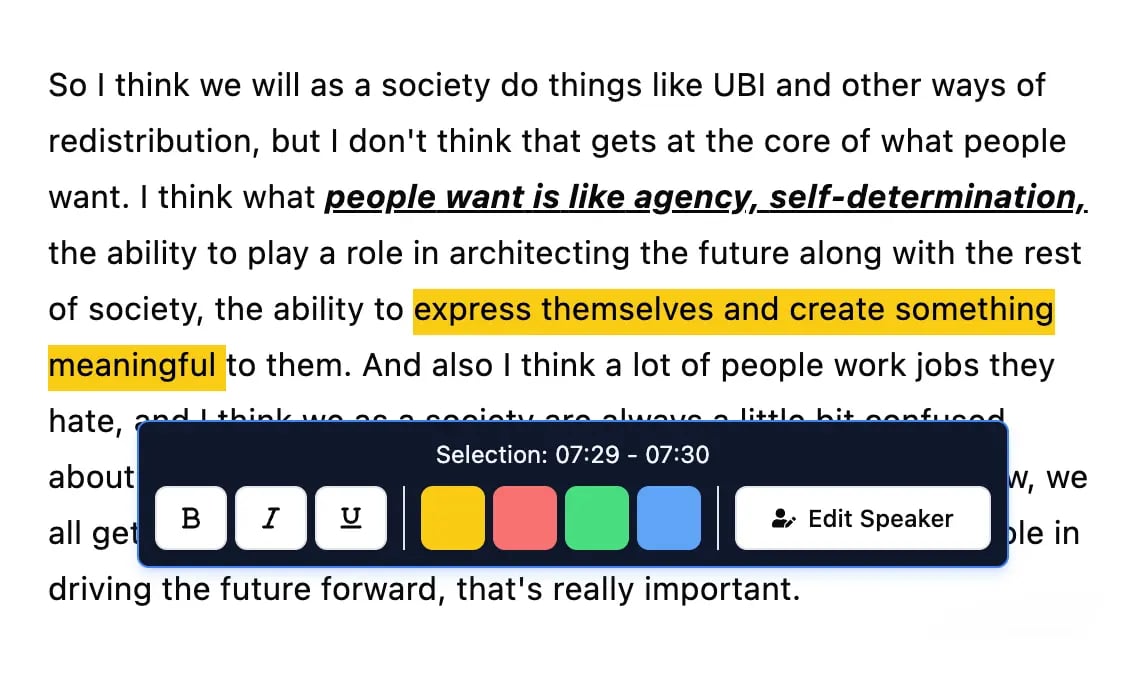
Strumenti di modifica
Modifica le trascrizioni con strumenti potenti tra cui trova e sostituisci, assegnazione dei parlanti, formati di testo arricchito ed evidenziazione.
Riassunti e Chatbot
Genera riassunti e altri approfondimenti dalla tua trascrizione, prompt personalizzati riutilizzabili e chatbot per i tuoi contenuti.
Integrazioni
Collegati con i tuoi strumenti e piattaforme preferiti per ottimizzare il tuo flusso di lavoro di trascrizione.
- Timestamp precisi: Questo è un punto di svolta. Quando i timestamp sono incorporati nella tua trascrizione, puoi fare clic su una citazione nel tuo QDAS e saltare istantaneamente a quel momento esatto nell'audio. È inestimabile per cogliere il tono di un partecipante, chiarire una parola biascicata o rivivere il contesto emotivo di un'affermazione potente.
- Etichette dei relatori pulite: Etichette dei relatori coerenti e accurate (come "Intervistatore", "Partecipante 1", "Dr. Smith") sono assolutamente non negoziabili. Se fai bene questo, il tuo QDAS può ordinare automaticamente le citazioni per relatore, rendendo incredibilmente facile confrontare le risposte o tracciare la storia di una persona attraverso l'intera conversazione.
- Opzioni di esportazione intelligenti: I migliori strumenti offrono esportazioni progettate specificamente per l'analisi. Vuoi formati semplici e puliti come testo normale (.txt) o documenti Word di base (.docx) che non confonderanno i tuoi strumenti di importazione QDAS con formattazione strana.
Pensa alla tua trascrizione come a un set di dati pre-organizzato. Più struttura costruisci durante la trascrizione, con relatori e timestamp chiari, meno lavoro di routine dovrai fare durante l'analisi.
Questo infografica illustra come appare un flusso di lavoro solido e di livello di ricerca.
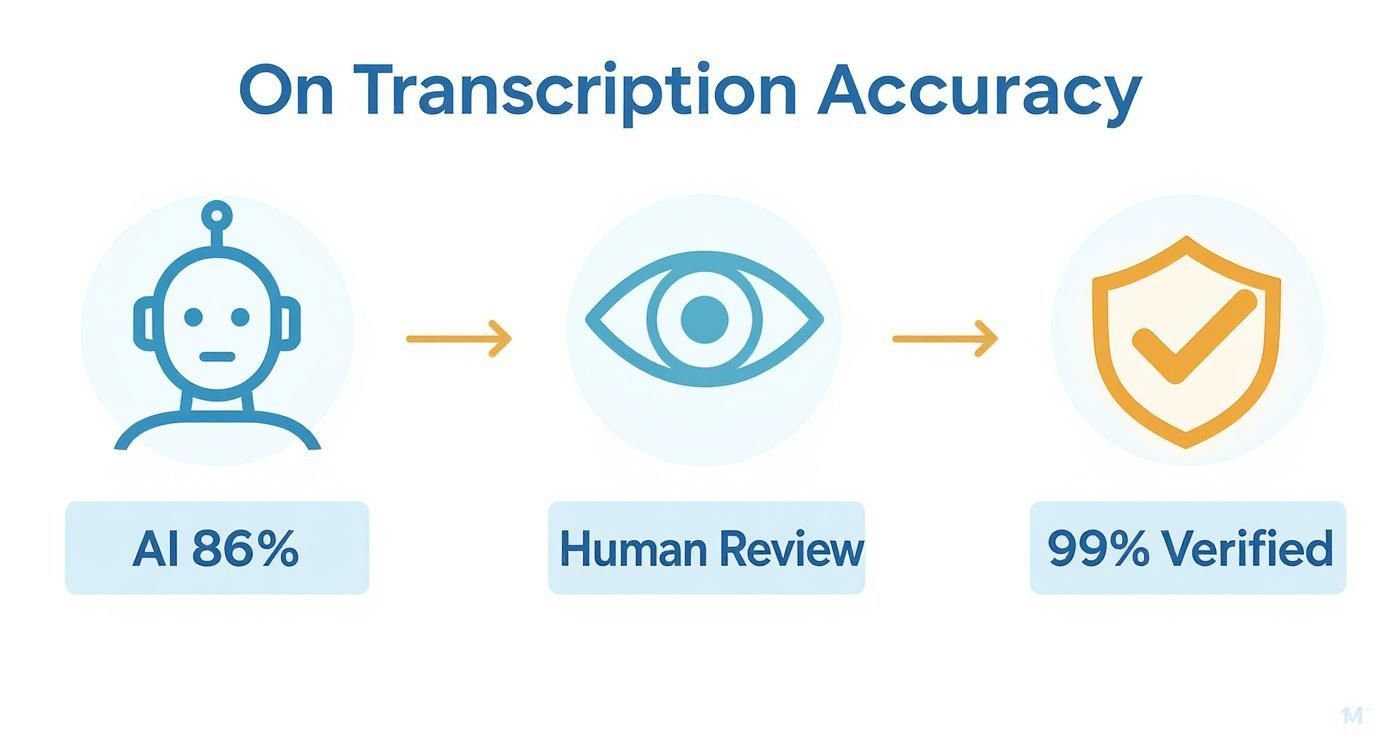
Come puoi vedere, il processo inizia con una buona bozza AI e poi si basa sulla revisione umana per raggiungere quel segno di accuratezza del 99%, lo standard necessario per una ricerca accademica e professionale rigorosa.
L'approccio ibrido IA + revisione umana è il nuovo standard di ricerca
La maggior parte delle università e dei comitati etici raccomanda ora un approccio ibrido: IA per la velocità, revisione umana per l'accuratezza. Ciò garantisce sia la produttività che la piena integrità dei dati nella ricerca qualitativa moderna.
Adattare i flussi di lavoro a diversi scenari di ricerca
Naturalmente, il tuo flusso di lavoro cambierà in base al tuo metodo di ricerca. Un colloquio individuale è un mondo lontano da un focus group caotico.
- Per interviste approfondite: Qui, l'attenzione è sui dettagli ricchi e sfumati di una persona. I timestamp a livello di parola sono di grande aiuto per analizzare pause ed esitazioni. Un'esportazione pulita ti consente di codificare automaticamente l'intero documento nel file del caso di quel partecipante in NVivo in pochi secondi.
- Per focus group: L'identificazione dell'oratore è fondamentale. Prima ancora di pensare all'esportazione, la tua priorità assoluta è assicurarti che ogni singolo oratore sia etichettato correttamente e in modo coerente. Questo lavoro preparatorio consente al tuo QDAS di trattare ogni partecipante come una fonte unica, il che è essenziale per confrontare le prospettive all'interno del gruppo.
- Per note sul campo etnografiche: Se stai dettando appunti al volo, una solida trascrizione AI può trasformare i tuoi pensieri parlati in testo ricercabile quasi istantaneamente. Da lì, puoi importare il testo nel tuo software di analisi e codificarlo insieme ai tuoi altri dati.
Una volta che il tuo testo è pronto, avrai bisogno di strategie efficaci per analizzare i dati delle interviste per estrarre quelle preziose intuizioni. Per un'analisi più approfondita di questa parte del processo, consulta la nostra guida su come analizzare i dati delle interviste.
Connessione con software di analisi dati qualitativi
Non siamo gli unici a concentrarci su una migliore integrazione. Il mercato globale dei software di analisi dati qualitativi è stato valutato a 1,56 miliardi di USD nel 2024 e si prevede che raggiungerà 2,76 miliardi di USD entro il 2033. Questa crescita è dovuta alla crescente domanda di strumenti che funzionino insieme in modo impeccabile. Leggi la ricerca completa sul mercato QDAS.
Costruire un flusso di lavoro di ricerca efficiente significa considerare la trascrizione non come un prodotto finale, ma come un passaggio preparatorio cruciale. Quando scegli uno strumento con una forte integrazione in mente, stai investendo in un processo di ricerca più intelligente, veloce e rigoroso.
Trascrizione per metodo di ricerca
Interviste approfondite
Meglio supportato da timestamp a livello di parola e etichettatura pulita dei relatori per analisi emotive e narrative.
Focus group
Richiede un rilevamento multi-relatore ad alta precisione per confrontare punti di vista e dinamiche di interazione.
Studi etnografici
La trascrizione di note vocali consente una rapida trasformazione delle osservazioni sul campo in dati codificati.
Ricerca politica e legale
Richiede estrema accuratezza, archiviazione dati a lungo termine e rigorosi protocolli di sicurezza.
Protezione dei Dati e della Riservatezza dei Partecipanti

Quando il tuo lavoro coinvolge soggetti umani, la sicurezza dei dati non è solo una casella tecnica da spuntare, ma una pietra angolare etica. Ogni singolo file audio che carichi contiene informazioni sensibili e personali che i tuoi partecipanti ti hanno affidato. Inserire questi file in uno strumento online non verificato può facilmente violare i protocolli del Comitato Etico (IRB), infrangere accordi legali e, soprattutto, tradire quella fiducia.
La responsabilità di proteggere questi dati ricade interamente su di te, in qualità di ricercatore. La comodità di un servizio veloce e gratuito spesso ha un prezzo elevato e nascosto, solitamente sepolto in termini di servizio complessi. Collaborare con un fornitore di trascrizioni che aderisce ai più alti standard di etica della ricerca è assolutamente non negoziabile.
Valutazione delle Politiche sulla Privacy e delle Misure di Sicurezza
Prima di caricare un singolo byte di dati, devi sentirti a tuo agio nel leggere le politiche sulla privacy. Sì, possono essere dense, ma contengono indizi cruciali su come un'azienda gestirà effettivamente i tuoi dati di ricerca. Non limitarti a scorrere, ma cerca attivamente risposte ad alcune domande chiave.
Ecco cosa dovresti cercare:
- Crittografia End-to-End: Questo è il requisito minimo. Assicura che i tuoi dati siano crittografati e illeggibili dal momento in cui lasciano il tuo computer fino al momento in cui vengono elaborati. Cerca termini come crittografia AES-256, uno standard di riferimento per la protezione dei dati.
- Protocolli Chiari di Gestione dei Dati: La politica deve dichiarare esplicitamente chi può accedere ai tuoi dati e perché. Un linguaggio vago è un enorme segnale di allarme.
- Conformità alle Normative: A seconda di dove ti trovi tu e i tuoi partecipanti, dovrai vedere impegni verso standard come il GDPR per i dati europei o l'HIPAA per le informazioni sanitarie.
Il tuo principio guida qui è semplice: se un servizio non riesce a spiegare chiaramente come protegge i tuoi dati, presumilo che non lo faccia. La fiducia si basa sulla trasparenza, non sulla speranza.
Per un solido esempio di come ciò si presenta nella pratica, puoi consultare documentazione come la Politica sulla Privacy di Parakeet-AI. Questo è il tipo di documento di cui hai bisogno per sentirti sicuro dell'impegno di una piattaforma in termini di sicurezza.
I Rischi Nascosti dell'Addestramento dei Modelli AI
Una delle maggiori insidie etiche nell'utilizzo del moderno software di trascrizione per la ricerca qualitativa è il modo in cui vengono addestrati i modelli AI. Molti servizi, specialmente quelli gratuiti, inseriscono una clausola nei loro termini che conferisce loro il diritto di utilizzare i tuoi audio e le tue trascrizioni per migliorare la propria AI.
Questo è un punto critico per la ricerca confidenziale. Significa che le storie, le opinioni e i dati personali dei tuoi partecipanti potrebbero diventare parte di un set di dati permanente e proprietario, utilizzato per scopi commerciali su cui non hai alcun controllo.
L'addestramento dell'IA sui dati di ricerca è una violazione etica
Se il tuo provider di trascrizione utilizza i dati dei partecipanti per l'addestramento dell'IA, potresti violare inconsapevolmente accordi di consenso, condizioni IRB e leggi internazionali sulla privacy. Richiedi sempre una rigorosa politica di addestramento zero.
Devi trovare un servizio con una politica di zero addestramento esplicita. Questa è una promessa ferma che i tuoi dati verranno utilizzati solo per generare la tua trascrizione, nient'altro. Ad esempio, puoi vedere come una rigorosa posizione di non addestramento protegge i tuoi dati in questa politica sulla privacy: https://transcript.lol/legal/privacy. Tale garanzia è lo standard d'oro assoluto per qualsiasi ricerca accademica o professionale seria.
Un altro fattore cruciale è la residenza dei dati, la posizione fisica e geografica in cui vengono archiviati i tuoi dati. Molte sovvenzioni e requisiti IRB impongono che i dati debbano rimanere all'interno di un paese o di una regione specifica (come l'Unione Europea). Un servizio affidabile sarà trasparente su dove si trovano i suoi server, permettendoti di soddisfare i tuoi obblighi istituzionali e di finanziamento senza alcuna congettura.
Il tuo primo progetto con Transcript.LOL
Passiamo alla pratica. La teoria è ottima, ma il modo migliore per vedere quanto un software di trascrizione per la ricerca qualitativa cambi davvero le cose è semplicemente tuffarsi. Ti guiderò attraverso un progetto di ricerca reale dall'inizio alla fine utilizzando Transcript.LOL per mostrarti come risolve i soliti grattacapi.
https://www.youtube.com/embed/eSOssNY9v6A
Immagina questo: hai appena terminato un focus group di 45 minuti. Hai tre partecipanti e un moderatore. Il file audio è sul tuo desktop e devi inserirlo in NVivo per la codifica, senza perdere una settimana in trascrizioni manuali.
Dall'audio grezzo a una bozza di lavoro
Prima di tutto, devi inserire il tuo file audio nel sistema. Con Transcript.LOL, puoi semplicemente trascinare e rilasciare il file dal tuo computer o persino estrarlo dallo spazio di archiviazione cloud come Google Drive. Si mette immediatamente al lavoro, alimentato dal motore Whisper di OpenAI.
In pochi minuti, avrai una prima bozza completa. L'IA individua automaticamente chi sta parlando e assegna loro etichette come "Speaker 1", "Speaker 2" e così via. Questo non è il prodotto finale, ma è una solida base su cui costruire.
L'interfaccia è pulita e semplice. Mette il testo proprio accanto a un lettore audio, in modo da poter ascoltare e leggere contemporaneamente.
Questa visualizzazione è il tuo centro di comando. Puoi vedere chiaramente i turni di parola e avere a portata di mano tutti gli strumenti di editing necessari, rendendo il processo di revisione molto più veloce.
Rifinire la trascrizione per l'analisi
È qui che entra in gioco la tua esperienza di ricercatore. L'IA è un assistente fantastico, ma manca di contesto. Il tuo primo compito è dare un significato a quelle etichette generiche degli speaker. Basta fare clic su "Speaker 1" e rinominarlo in "Moderatore", cambiare "Speaker 2" in "Partecipante A" e così via. La parte migliore? La modifica si applica automaticamente ovunque. Niente più incubi di ricerca e sostituzione.
Successivamente, ci occupiamo di gergo e terminologia. Supponiamo che il tuo focus group stesse discutendo di "fenomenologia ermeneutica", ma l'IA ha sentito "fenomeno ermetico". Facile correzione. Basta fare clic sulla frase e digitare il termine corretto.
Una delle funzionalità più potenti per i ricercatori è la creazione di un vocabolario personalizzato. Se dici al software di riconoscere sempre la "fenomenologia" o il nome del tuo ricercatore principale, vedrai migliorare l'accuratezza in tutte le trascrizioni future per quel progetto. È un piccolo passo che fa risparmiare un sacco di tempo di editing in seguito.
Questa è anche la tua occasione per fare un controllo di qualità finale. Puoi unire paragrafi se il pensiero di qualcuno è stato diviso, correggere la punteggiatura errata e assicurarti che la trascrizione rifletta veramente il flusso della conversazione originale. È un passaggio rapido ma assolutamente essenziale.
Preparare l'esportazione per il tuo QDAS
Una volta che sei soddisfatto della trascrizione, è ora di esportarla per il tuo software di analisi, come ATLAS.ti o Dedoose. È qui che le cose spesso si complicano con altri strumenti, ma una piattaforma creata per i ricercatori la rende indolore.
Invece di produrre semplicemente un file .txt generico, ottieni opzioni personalizzate per l'analisi dei dati qualitativi.
Checklist di esportazione per NVivo o ATLAS.ti:
- Seleziona il formato .docx. Questa è l'opzione più affidabile per un'importazione pulita, preservando il tuo testo senza una formattazione strana che potrebbe ostacolare il tuo QDAS.
- Assicurati che le etichette degli speaker siano attive. La tua esportazione deve includere i nomi corretti ("Moderatore", "Partecipante A") in modo che il tuo software possa riconoscerli come persone diverse.
- Includi i timestamp. Puoi scegliere di aggiungere timestamp a intervalli prestabiliti o solo all'inizio di ogni paragrafo. Questo è ciò che collega il testo nel tuo software di analisi al momento esatto nell'audio.
Con queste impostazioni definite, scarichi semplicemente il file. Quando importi questo documento in NVivo, riconoscerà automaticamente i diversi speaker e sincronizzerà i timestamp. Proprio così, hai una trascrizione pulita e perfettamente formattata pronta per la codifica.
Sei passato da un file audio grezzo all'analisi approfondita in una frazione del tempo che ci sarebbe voluto manualmente, il tutto senza compromettere l'accuratezza che la tua ricerca richiede.
Hai domande? Abbiamo risposte.
Quando sei immerso nella ricerca qualitativa, la trascrizione può sembrare un campo minato di domande pratiche ed etiche. Lo capiamo. Hai bisogno di strumenti che non siano solo accurati, ma che si adattino al tuo flusso di lavoro e rispettino i tuoi dati. Affrontiamo alcune delle domande più comuni che sentiamo dai ricercatori.
Come gestisco le registrazioni audio scadenti?
Ah, la temuta registrazione di scarsa qualità. È probabilmente il più grande grattacapo per qualsiasi trascrizione, sia che tu stia usando un'IA o un essere umano. La mossa migliore è sempre la prevenzione: seriamente, un microfono esterno ti darà risultati drasticamente migliori rispetto al microfono integrato del tuo laptop.
Ma a volte, sei bloccato con quello che hai. Non tutto è perduto.
Prima ancora di pensare di caricarlo, prova a pulirlo con uno strumento gratuito come Audacity. Il suo filtro di riduzione del rumore può fare miracoli sui ronzii di fondo e lo strumento di amplificazione può potenziare le voci troppo basse. Saresti sorpreso da quanto possano aiutare alcune semplici modifiche.
Se l'audio è assolutamente critico ma ancora un disastro, è qui che un trascrittore umano professionista si guadagna davvero il suo compenso. Sono addestrati a decifrare discorsi confusi e spesso possono recuperare intuizioni chiave che un algoritmo contrassegnerebbe semplicemente come [inintelligibile].
Questo software può gestire lingue e accenti diversi?
La maggior parte dei servizi di trascrizione di alto livello gestisce una tonnellata di lingue, ma le prestazioni possono essere un miscuglio. Controlla sempre l'elenco delle lingue supportate dal provider, ma soprattutto, esegui un rapido test con un breve file audio nella tua lingua di destinazione per vedere l'accuratezza nel mondo reale per te stesso.
Gli accenti sono un gioco completamente diverso. Sono una sfida enorme per i sistemi automatizzati.
Mentre molte piattaforme stanno migliorando con l'inglese americano o britannico standard, dialetti regionali pesanti o accenti non nativi possono far precipitare l'accuratezza.
Se la tua ricerca si basa sull'analisi del dialetto, dell'accento o delle sfumature linguistiche, un trascrittore umano specializzato in quel particolare dialetto è quasi sempre la scelta migliore. Un algoritmo può facilmente perdere i dettagli sottili ma significativi che stai cercando.
Qual è il modo migliore per formattare le trascrizioni per la codifica?
Il formato perfetto dipende davvero dal tuo piano di analisi e dal software di analisi dei dati qualitativi (QDAS) che stai utilizzando, come NVivo o ATLAS.ti. Per la maggior parte dei progetti, tuttavia, più semplice è meglio.
Ecco alcune best practice per assicurarti che le tue trascrizioni funzionino bene con il tuo QDAS:
- Etichette degli speaker pulite: La coerenza è tutto. Usa le stesse etichette, come "Intervistatore" e "Partecipante 1", in ogni singolo file.
- Timestamp frequenti: Aggiungere timestamp a intervalli regolari (diciamo, ogni 30-60 secondi) o a ogni cambio di speaker è un toccasana. Ti consente di fare clic su un pezzo di testo e saltare istantaneamente a quel momento esatto nell'audio all'interno del tuo software di analisi.
- Formati di esportazione semplici: Attieniti alle basi. L'esportazione in formato .docx o .txt garantisce un'importazione pulita senza problemi di formattazione strani che potrebbero creare problemi al tuo software.
Quella capacità di sincronizzare testo e audio è oro puro quando devi controllare il tono di un partecipante, verificare il contesto o capire cosa è stato detto in una frase borbottata durante il processo di codifica.
Vale davvero la pena pagare per un software di trascrizione?
La tentazione del "gratuito" è forte, ma per qualsiasi progetto qualitativo serio, un servizio a pagamento è un investimento che ripaga. Gli strumenti gratuiti hanno spesso costi nascosti che possono compromettere seriamente la tua ricerca.
Ecco cosa si incontra spesso con i servizi gratuiti:
- Minore accuratezza: Utilizzano modelli di IA più vecchi e meno sofisticati, il che significa più errori e più tempo dedicato alle correzioni manuali.
- Funzionalità limitate: Probabilmente non troverai l'identificazione dello speaker, limiti di dimensione dei file minuscoli e opzioni di esportazione di base.
- Grandi rischi per la privacy: Questo è il punto cruciale. Molti strumenti gratuiti si finanziano utilizzando i tuoi dati confidenziali per addestrare la loro IA. Per qualsiasi ricerca che coinvolga partecipanti umani, si tratta di una massiccia violazione etica.
Un servizio a pagamento affidabile ti offre maggiore accuratezza e funzionalità indispensabili, ma fornisce anche una solida sicurezza e una chiara politica sulla privacy dei dati. Ti fa risparmiare un'enorme quantità di tempo, protegge l'integrità della tua ricerca e ti aiuta a soddisfare i tuoi obblighi etici.
Pronto a rendere i tuoi dati pronti per l'analisi in pochi minuti, non in giorni? Transcript.LOL è costruito per i ricercatori. Offriamo trascrizioni veloci, accurate e sicure con funzionalità come ID speaker, vocabolario personalizzato ed esportazioni flessibili. Soprattutto, abbiamo una rigorosa politica di non addestramento per proteggere la riservatezza dei tuoi partecipanti.