Les 12 meilleurs logiciels gratuits de synthèse vocale en texte en 2026...
Découvrez les 12 meilleurs logiciels gratuits de reconnaissance vocale en texte pour 2026. Comparez les fonctionnalités, la précision et la confidentialité pour trouver la solution parfaite pour vous.
Praveen
January 12, 2026
Des mots prononcés au texte numérique : votre guide ultime des logiciels de reconnaissance vocale
La transcription manuelle de contenu audio et vidéo est une tâche fastidieuse et chronophage. Que vous soyez un podcasteur créant des notes d'émission, un marketeur réutilisant du contenu vidéo pour un blog, ou un étudiant capturant les détails d'une conférence, la conversion de mots prononcés en texte précis est un goulot d'étranglement critique. Le bon logiciel gratuit de reconnaissance vocale en texte peut éliminer cette friction, vous faisant gagner des heures d'efforts et ouvrant de nouvelles possibilités pour votre contenu. Ce guide est conçu pour vous aider à trouver l'outil parfait pour vos besoins spécifiques, en vous aidant à comparer les meilleures options disponibles aujourd'hui.
Pourquoi la reconnaissance vocale en texte est une amélioration du flux de travail ?
Les outils de reconnaissance vocale en texte ne remplacent pas seulement la saisie au clavier – ils améliorent fondamentalement la manière dont l'information est capturée, réutilisée et distribuée. Une fois que l'audio devient du texte, il devient consultable, modifiable et immédiatement réutilisable sur les blogs, les e-mails, les rapports et les réseaux sociaux.
Nous avons évalué un large éventail de solutions, des outils de dictée simples et intégrés aux plateformes de transcription puissantes basées sur l'IA. Pour chaque option, nous fournissons une analyse détaillée couvrant les caractéristiques clés, les niveaux de précision, les considérations relatives à la confidentialité et les cas d'utilisation idéaux. Vous trouverez des liens directs et des captures d'écran pour voir comment chaque plateforme fonctionne, ainsi que des évaluations honnêtes de leurs avantages et inconvénients. Nous explorerons tout, de la précision axée sur la confidentialité de Transcript.LOL à la commodité omniprésente de la saisie vocale de Google Docs et à la puissance hors ligne des modèles open-source comme Whisper d'OpenAI.
Alors que nous explorons ces solutions, il est important de reconnaître comment ces outils alimentés par l'IA contribuent à la tendance plus large de la manière dont l'IA transforme la création de contenu pour les PME. Ce changement rend la technologie de transcription sophistiquée plus accessible que jamais, permettant aux créateurs et aux professionnels de rationaliser considérablement leurs flux de travail. Cette liste organisée servira de ressource définitive, vous aidant à sélectionner le logiciel le plus efficace pour transformer votre audio en texte consultable, modifiable et partageable, sans les coûts élevés ni le travail manuel.
IA de pointe
Alimenté par Whisper d'OpenAI pour une précision de premier plan. Prise en charge des vocabulaires personnalisés, des fichiers jusqu'à 10 heures et des résultats ultra rapides.

Importer depuis plusieurs sources
Importez des fichiers audio et vidéo depuis diverses sources, y compris le téléchargement direct, Google Drive, Dropbox, les URL, Zoom et plus encore.
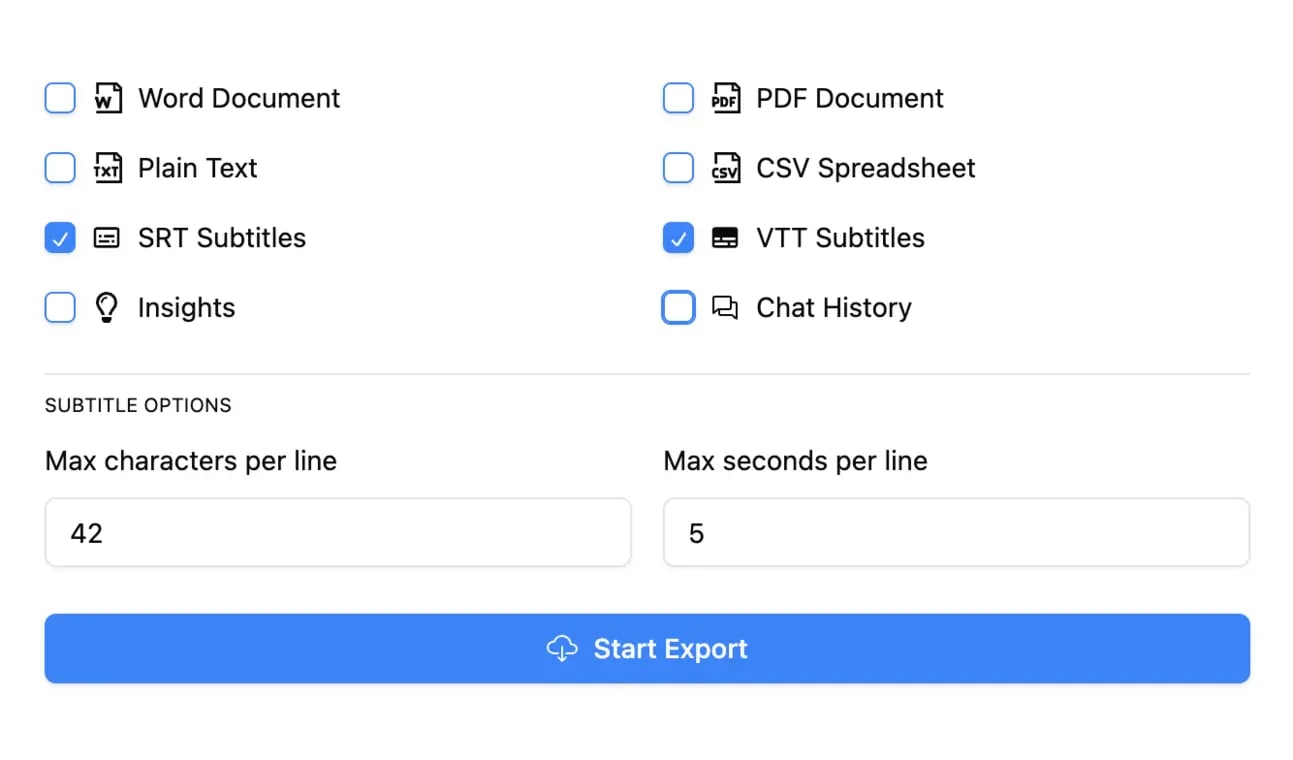
Exporter en plusieurs formats
Exportez vos transcriptions en plusieurs formats dont TXT, DOCX, PDF, SRT et VTT avec des options de formatage personnalisables.
1. Transcript.LOL
Transcript.LOL s'impose comme un choix de premier ordre pour les professionnels recherchant une transcription robuste, pilotée par l'IA, qui combine une précision exceptionnelle avec de puissants outils de création de contenu. C'est plus qu'un simple convertisseur de parole en texte ; c'est une plateforme de flux de travail intégrée conçue pour transformer l'audio et la vidéo bruts en éléments soignés, prêts à l'emploi en quelques minutes, ce qui en fait un concurrent de taille pour le meilleur logiciel gratuit de parole en texte disponible aujourd'hui.
Sa force principale réside dans l'utilisation d'une version finement ajustée du moteur Whisper d'OpenAI, offrant un taux de précision annoncé d'environ 99,8 %. Cette précision est améliorée par la prise en charge d'un vocabulaire personnalisé, garantissant que les termes spécialisés, les noms et le jargon de l'industrie sont capturés correctement, une fonctionnalité essentielle pour les utilisateurs dans les domaines technique, académique ou médical.
Différenciateurs clés et cas d'utilisation
Ce qui distingue vraiment Transcript.LOL, c'est sa suite étendue de fonctionnalités post-transcription. Au-delà de la fourniture d'une transcription mot à mot, la plateforme génère automatiquement du contenu précieux comme des résumés, des éléments d'action, des quiz et même des publications sur les réseaux sociaux. Cela transforme l'outil d'une simple utilité en un gain de temps considérable pour les spécialistes du marketing, les éducateurs et les créateurs de contenu.

Détection des intervenants
Identifiez automatiquement les différents intervenants dans vos enregistrements et étiquetez-les avec leurs noms.
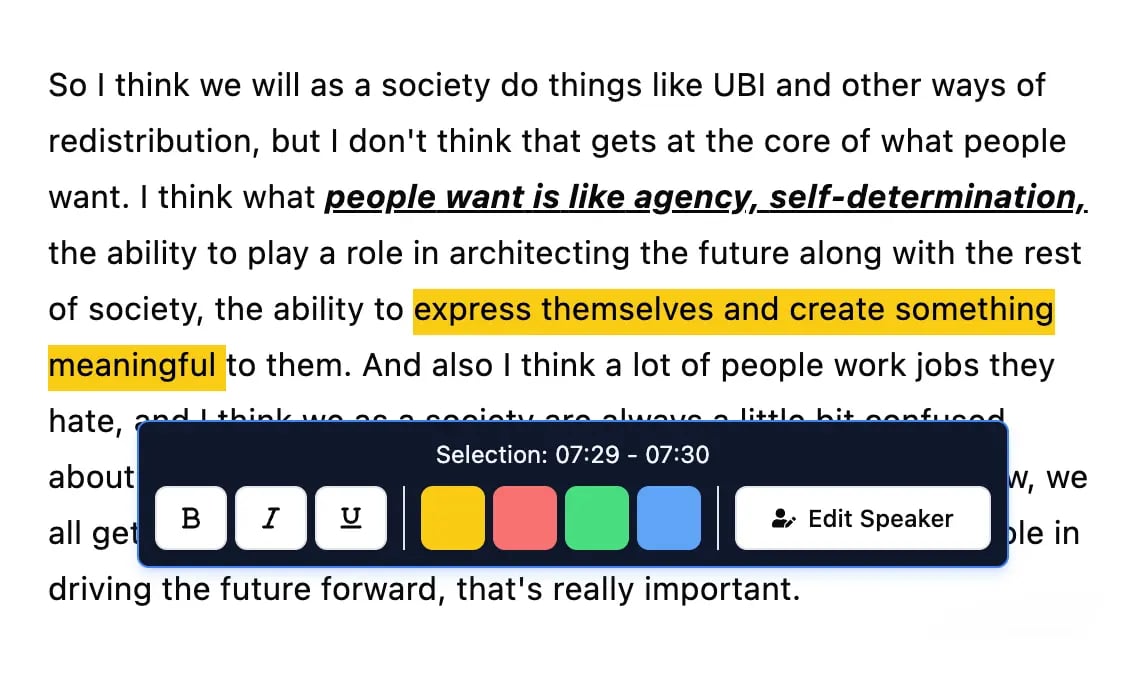
Outils d'édition
Modifiez les transcriptions avec des outils puissants incluant rechercher et remplacer, attribution des intervenants, formats de texte enrichi et surlignage.
Résumés et Chatbot
Générez des résumés et d'autres analyses de votre transcription, des prompts personnalisés réutilisables et un chatbot pour votre contenu.
- Pour les créateurs de contenu et les spécialistes du marketing : Transformez rapidement un podcast ou un webinaire en un article de blog, des notes d'émission et une série de publications sur les réseaux sociaux. La capacité de traiter des fichiers allant jusqu'à 10 heures en fait l'outil idéal pour le contenu de longue durée.
- Pour les équipes et les entreprises : Les espaces de travail partagés de la plateforme, l'organisation par dossiers et les intégrations (Zoom, Zapier, Google Drive) rationalisent les processus d'examen collaboratif. La transcription des enregistrements de réunions et la génération de points d'action deviennent une tâche automatisée et efficace.
- Pour les chercheurs et les étudiants : La haute précision et la prise en charge de diverses sources d'importation (y compris les URL directes) en font l'outil parfait pour transcrire avec confiance des conférences, des interviews et des enregistrements audio de recherche.
Approche axée sur la confidentialité : Un avantage significatif est la politique stricte de non-formation de Transcript.LOL. Vos données ne sont pas utilisées pour entraîner des modèles d'IA, un engagement crucial pour les utilisateurs traitant des informations sensibles ou propriétaires.
Présentation de la plateforme
| Fonctionnalité | Détails |
|---|---|
| Précision et Vitesse | Utilise OpenAI Whisper avec un vocabulaire personnalisé pour des résultats de haute précision, quasi en temps réel. |
| Gestion des fichiers | Accepte des téléchargements uniques jusqu'à 10 heures / 5 Go. Prend en charge divers formats et importations directes depuis des services cloud, Zoom et des URL. |
| Outils de contenu IA | Génère des résumés, des quiz, des cartes mentales, des articles de blog, des textes pour les réseaux sociaux, et plus encore, directement à partir de la transcription. |
| Collaboration | Comprend des espaces de travail partagés, une recherche robuste et des intégrations avec Zapier, WhatsApp, Telegram et les principaux fournisseurs de stockage cloud. |
| Tarification | Niveau gratuit : 2 transcriptions/jour (max 20 min chacune). Plan illimité : 120 $/an pour une utilisation illimitée, des téléchargements longs et toutes les fonctionnalités IA. |
| Sécurité | Applique une politique stricte de non-formation sur les données des clients et travaille avec des sous-traitants pour empêcher la réutilisation des données. |
Démarrage
- Inscription : Créez un compte gratuit sur le site web.
- Téléchargement : Faites glisser et déposez votre fichier audio/vidéo, ou importez-le depuis Google Drive, Zoom, une URL ou d'autres services connectés.
- Transcription : L'IA traite le fichier, détecte automatiquement les intervenants et génère la transcription.
- Affiner et exporter : Utilisez l'éditeur de texte enrichi pour apporter des ajustements. Ensuite, exploitez les outils IA pour créer des résumés ou d'autres contenus et exportez dans le format souhaité (DOCX, SRT, PDF, etc.).
Pour une comparaison plus approfondie de ses fonctionnalités par rapport à d'autres options du marché, vous pouvez consulter l'analyse fournie dans ce guide des logiciels de synthèse vocale.
Site web : https://transcript.lol
2. Google Docs – Saisie vocale
Pour les utilisateurs déjà intégrés dans l'écosystème Google, le logiciel de reconnaissance vocale gratuit le plus accessible est probablement celui intégré directement dans les outils qu'ils utilisent quotidiennement. La fonction de saisie vocale de Google Docs est un outil de commodité puissant, offrant une dictée sans installation, basée sur le navigateur, pour toute personne disposant d'un compte Google et du navigateur Chrome. Il excelle dans la conversion des mots parlés en texte en temps réel, ce qui en fait l'outil idéal pour rédiger des documents, prendre des notes rapides ou surmonter le blocage de l'écrivain.
Ce qui rend la saisie vocale si efficace, c'est sa simplicité et sa précision surprenante pour une dictée claire, avec un seul locuteur. Elle prend en charge un grand nombre de langues et reconnaît même les commandes de formatage de base comme "nouveau paragraphe" ou "mettre en gras". Bien qu'elle manque des fonctionnalités avancées des services de transcription dédiés, tels que l'identification des locuteurs ou l'horodatage, sa force réside dans son intégration fluide dans le flux de travail d'un écrivain.
Démarrage rapide et cas d'utilisation
Pour commencer, ouvrez simplement un document Google Docs, accédez à Outils > Saisie vocale et cliquez sur l'icône du microphone. C'est un outil parfait pour les étudiants qui rédigent des dissertations, les créateurs de contenu qui esquissent des scripts, ou les professionnels qui capturent les minutes de réunion au fur et à mesure. Il s'agit d'un outil de dictée directe et en direct, et non d'un service pour télécharger des fichiers audio préenregistrés.
| Analyse des fonctionnalités | Détails |
|---|---|
| Fonction principale | Dictée en direct directement dans un document |
| Accessibilité | Gratuit avec un compte Google ; fonctionne dans Chrome |
| Fonctionnalités clés | Prise en charge multilingue, commandes vocales de base |
| Limitations | Pas de téléchargement de fichiers, pas de diarisation des locuteurs |
En fin de compte, l'outil de Google est la solution idéale pour la création de documents immédiate et simple, sans logiciel supplémentaire. Pour une analyse plus approfondie de ce qui influence les résultats de transcription, vous pouvez en savoir plus sur les facteurs affectant la précision de la reconnaissance vocale.
Site web : https://docs.google.com
3. Microsoft Windows 11 – Accès vocal et saisie vocale
Pour les utilisateurs de Windows 11, un logiciel de reconnaissance vocale gratuit puissant et respectueux de la vie privée est déjà intégré directement dans le système d'exploitation. L'Accès vocal et la Saisie vocale dans Windows 11 offrent une dictée robuste sur l'appareil qui fonctionne dans tout le système, des traitements de texte aux navigateurs web. Cette solution intégrée est excellente pour les utilisateurs qui privilégient la fonctionnalité hors ligne et souhaitent conserver leurs données localement, car la reconnaissance vocale se fait sur l'appareil lui-même.
Elle offre une dictée fluide avec ponctuation automatique et prend en charge les commandes vocales pour l'édition de texte et la navigation système, comme l'ouverture d'applications ou le clic sur des boutons. Cela en fait un outil redoutable à la fois pour l'accessibilité et la productivité générale, vous permettant de contrôler votre PC et de rédiger du texte sans toucher au clavier. Bien que ses fonctionnalités les plus avancées soient optimisées pour l'anglais américain, elle offre une expérience transparente sans nécessiter d'installations ni de comptes tiers.
Démarrage rapide et cas d'utilisation
Pour démarrer la saisie vocale, appuyez simplement sur la touche Logo Windows + H dans n'importe quel champ de texte actif. Pour un contrôle complet du système, activez l'Accès vocal dans Paramètres > Accessibilité > Parole. C'est une solution idéale pour les professionnels qui rédigent des e-mails directement dans Outlook, les étudiants qui prennent des notes dans OneNote, ou tout utilisateur cherchant à réduire sa dépendance au clavier pour les tâches informatiques quotidiennes.
| Analyse des fonctionnalités | Détails |
|---|---|
| Fonction principale | Dictée en direct et contrôle du PC dans tout le système |
| Accessibilité | Gratuit et intégré à Windows 11 |
| Fonctionnalités clés | Traitement sur l'appareil, utilisation hors ligne, commandes vocales |
| Limitations | La prise en charge des langues varie ; meilleure en anglais américain |
En fin de compte, les outils natifs de Windows 11 sont le meilleur choix pour les utilisateurs recherchant une solution de dictée intégrée, sécurisée et capable de fonctionner hors ligne, qui fonctionne sur toutes leurs applications.
Site web : https://www.microsoft.com/en-us/windows/tips/voice-access
4. Otter.ai
Pour ceux qui ont besoin de plus qu'une simple dictée, Otter.ai se positionne comme un assistant de réunion IA puissant. Il se distingue comme un logiciel de reconnaissance vocale gratuit de premier plan, spécialement conçu pour transcrire des conversations, des réunions et des interviews. Sa principale force réside dans sa capacité à gérer plusieurs intervenants, en identifiant et en étiquetant qui a dit quoi en temps réel ou à partir d'un fichier audio, ce qui le rend inestimable pour les environnements collaboratifs.
Ce qui rend Otter.ai particulièrement utile pour les équipes, c'est son intégration avec des plateformes comme Zoom, Google Meet et Microsoft Teams. L'IA génère des notes consultables, des points d'action et des résumés concis à partir des conversations, transformant des discussions désordonnées en enregistrements organisés et exploitables. Le généreux niveau gratuit offre une quantité substantielle de minutes de transcription par mois, bien qu'avec certaines limitations sur la durée d'importation et les fonctionnalités par rapport à ses plans payants.
Démarrage rapide et cas d'utilisation
Pour commencer, inscrivez-vous pour un compte gratuit et connectez-le à votre calendrier pour que l'assistant Otter rejoigne et transcrive automatiquement vos réunions virtuelles. Vous pouvez également enregistrer directement des conversations ou télécharger des fichiers audio. C'est un outil parfait pour les chefs de projet qui capturent les réunions d'équipe, les journalistes qui mènent des interviews, ou les étudiants qui enregistrent des conférences pour une révision ultérieure. Si vous débutez dans ce processus, comprendre comment transcrire gratuitement de l'audio en texte peut fournir une base solide.
| Analyse des fonctionnalités | Détails |
|---|---|
| Fonction principale | Transcription de réunions en direct et prise de notes |
| Accessibilité | Modèle Freemium avec applications web et mobiles |
| Fonctionnalités clés | Identification des intervenants, résumés IA, intégrations de réunions |
| Limitations | Le niveau gratuit a des limites sur la durée d'importation et les minutes mensuelles |
En fin de compte, Otter.ai est le choix idéal pour quiconque a besoin de capturer, d'organiser et de partager des informations à partir de conversations multi-intervenants, comblant ainsi le fossé entre l'audio brut et les notes structurées.
Site web : https://otter.ai
5. Descript
Descript va au-delà de la simple transcription, se positionnant comme un éditeur audio et vidéo tout-en-un alimenté par le texte. Pour les podcasteurs, les YouTubers et les créateurs de contenu, c'est un outil révolutionnaire qui fusionne le processus de transcription directement avec l'édition multimédia. Au lieu de simplement fournir une transcription, Descript vous permet d'éditer votre vidéo ou votre audio en éditant simplement le texte, ce qui en fait un logiciel de reconnaissance vocale gratuit incroyablement intuitif pour la production multimédia.
Ce qui rend Descript unique, c'est son flux de travail basé sur la transcription. Supprimer un mot ou une phrase dans le texte le coupe automatiquement du fichier audio ou vidéo, avec des transitions fluides. Il comprend également de puissantes fonctionnalités IA comme la suppression des mots de remplissage ("euh", "hmm") en un seul clic et une fonction "Overdub" pour créer un clone IA de votre voix afin de corriger les erreurs. Bien que son niveau gratuit soit plutôt un essai avec des heures de transcription limitées, il offre un aperçu complet de ce puissant paradigme d'édition.
Démarrage rapide et cas d'utilisation
Pour commencer, inscrivez-vous pour un compte gratuit, créez un nouveau projet et faites glisser votre fichier audio ou vidéo. Descript le transcrira automatiquement, vous présentant l'éditeur basé sur le texte. C'est idéal pour les podcasteurs qui nettoient des interviews, les spécialistes du marketing qui créent des clips pour les réseaux sociaux à partir de vidéos longues, ou les équipes d'entreprise qui éditent des webinaires et du matériel de formation sans avoir besoin d'un logiciel de montage vidéo complexe.
| Analyse des fonctionnalités | Détails |
|---|---|
| Fonction principale | Montage audio/vidéo intégré basé sur le texte |
| Accessibilité | Niveau d'essai gratuit avec heures limitées ; nécessite un plan payant pour une utilisation continue |
| Fonctionnalités clés | Suppression des mots de remplissage, nettoyage audio IA (Studio Sound), montage multipiste |
| Limitations | Pas de plan gratuit permanent ; peut avoir une courbe d'apprentissage pour les fonctionnalités avancées |
En fin de compte, Descript est le meilleur choix pour quiconque a des besoins de transcription directement liés à la création de contenu et au montage multimédia, offrant un flux de travail qu'aucun service de transcription traditionnel ne peut égaler.
Site web : https://www.descript.com
6. OpenAI Whisper (open source)
Pour les développeurs et les utilisateurs ayant une expertise technique, Whisper d'OpenAI représente le summum des logiciels de reconnaissance vocale gratuits open source. Au lieu d'un service web prêt à l'emploi, Whisper est une collection de puissants modèles de reconnaissance vocale automatique (ASR) que vous pouvez exécuter sur votre propre matériel. Cette approche offre un contrôle inégalé sur la confidentialité et élimine les coûts de transcription récurrents par minute, car la seule dépense est la puissance de calcul requise.
Whisper est réputé pour sa précision exceptionnelle dans un large éventail de langues et sa capacité à gérer des audios difficiles avec du bruit de fond. Sa véritable force réside dans sa flexibilité ; il peut être intégré dans des applications personnalisées, utilisé pour le traitement par lots de grands volumes de fichiers audio, et même effectuer une traduction directe de la parole vers l'anglais. Bien qu'il nécessite une configuration technique, le compromis est un moteur de transcription de qualité professionnelle sans les frais récurrents des services commerciaux.
Démarrage rapide et cas d'utilisation
Pour commencer, il faut installer Python et la bibliothèque Whisper depuis son dépôt GitHub. À partir de là, vous pouvez exécuter des transcriptions via la ligne de commande sur vos fichiers audio locaux. C'est idéal pour les chercheurs qui analysent de grands ensembles de données audio, les développeurs qui intègrent des fonctionnalités de transcription dans leurs applications, ou les podcasteurs qui souhaitent traiter par lots l'ensemble de leur catalogue existant de manière privée et rentable.
| Analyse des fonctionnalités | Détails |
|---|---|
| Fonction principale | Transcription audio de haute précision |
| Accessibilité | Gratuit et open source ; nécessite une configuration locale (Python, GPU) |
| Fonctionnalités clés | Plusieurs tailles de modèles, prise en charge multilingue, traduction |
| Limitations | Nécessite une configuration technique, pas de dictée en temps réel, peut halluciner |
En fin de compte, Whisper est le choix pour ceux qui privilégient le contrôle, la confidentialité et la précision par rapport à la commodité prête à l'emploi. Vous pouvez en savoir plus sur la façon dont des modèles comme celui-ci s'intègrent dans le paysage plus large des logiciels de transcription alimentés par l'IA.
Site web : https://github.com/openai/whisper
7. whisper.cpp (port C/C++ de Whisper)
Pour les développeurs et les utilisateurs soucieux de la confidentialité à la recherche d'une transcription locale haute performance, whisper.cpp offre une alternative puissante aux services basés sur le cloud. Ce projet est un port C/C++ du modèle Whisper d'OpenAI, optimisé pour des performances CPU efficaces, y compris la prise en charge native d'Apple Silicon. En tant qu'outil en ligne de commande, il offre une expérience logicielle de reconnaissance vocale gratuite robuste entièrement hors ligne, garantissant qu'aucune donnée ne quitte jamais votre machine. C'est la solution idéale pour traiter des audios sensibles sans dépendre de serveurs externes ou de dépendances Python.
Ce qui distingue whisper.cpp, c'est son efficacité et sa portabilité pures. Il fonctionne sans pile logicielle lourde, ce qui le rend rapide et économe en ressources sur les ordinateurs portables et de bureau modernes. En utilisant des modèles quantifiés, il équilibre une haute précision avec des tailles de fichiers et des vitesses de traitement gérables, ce qui le rend accessible même sans GPU puissant. Bien que son interface en ligne de commande nécessite un certain confort technique, le compromis est un contrôle, une confidentialité et des performances inégalés pour la transcription audio hors ligne.
Démarrage rapide et cas d'utilisation
Pour commencer, il faut cloner le dépôt GitHub, compiler le code et télécharger un modèle Whisper pré-entraîné. Depuis le terminal, vous exécutez ensuite une commande simple pointant vers votre fichier audio. Cet outil est parfait pour les journalistes qui transcrivent des interviews sensibles, les chercheurs qui traitent des enregistrements de terrain sans connexion Internet, ou les développeurs qui intègrent des capacités de transcription directement dans des applications locales.
| Analyse des fonctionnalités | Détails |
|---|---|
| Fonction principale | Transcription de fichiers audio hors ligne et haute performance |
| Accessibilité | Gratuit et open source ; nécessite une compilation |
| Fonctionnalités clés | Optimisé pour Apple Silicon/AVX, pas besoin de Python, quantification des modèles |
| Limitations | Ligne de commande uniquement (pas d'interface graphique), nécessite le téléchargement et la configuration manuels du modèle |
En fin de compte, whisper.cpp est la solution pour les utilisateurs qui privilégient la confidentialité et la performance et qui sont à l'aise pour travailler dans un environnement de terminal.
Site web : https://github.com/ggml-org/whisper.cpp
8. Vosk (open source, hors ligne)
Pour les développeurs et les utilisateurs soucieux de la confidentialité à la recherche d'un contrôle total sur leurs données, Vosk se distingue comme une puissante boîte à outils logicielle de reconnaissance vocale gratuite hors ligne. Contrairement aux services basés sur le cloud, Vosk s'exécute entièrement sur votre machine locale, d'un ordinateur de bureau à un Raspberry Pi. Cela en fait un excellent choix pour intégrer la reconnaissance vocale dans des applications où la connectivité Internet est peu fiable ou où la confidentialité des données est une préoccupation majeure.
Son principal avantage réside dans ses modèles légers et efficaces et son large support pour divers langages de programmation. Vosk fournit aux développeurs les éléments de base pour créer des applications personnalisées activées par la voix, des assistants domotiques aux systèmes de commande embarqués dans les voitures, sans envoyer d'audio à des serveurs tiers. Il offre un degré de flexibilité exceptionnel pour les projets qui nécessitent un traitement hors ligne.
Démarrage rapide et cas d'utilisation
Pour commencer, il faut intégrer la bibliothèque Vosk dans un projet en utilisant un langage comme Python ou Java. Un développeur téléchargerait un modèle linguistique pré-entraîné, puis utiliserait l'API Vosk pour la reconnaissance en streaming en temps réel. Il est idéal pour créer des interfaces de contrôle vocal pour des applications de bureau, transcrire de l'audio dans un environnement sécurisé, ou créer des fonctionnalités activées par la voix pour des systèmes embarqués. Sa licence permissive Apache 2.0 le rend également adapté à un usage commercial.
| Analyse des fonctionnalités | Détails |
|---|---|
| Fonction principale | Boîte à outils de reconnaissance vocale hors ligne pour les développeurs |
| Accessibilité | Gratuit et open source (licence Apache 2.0) |
| Fonctionnalités clés | Modèles hors ligne légers, prend en charge plus de 20 langues, liaisons pour de nombreux langages de programmation |
| Limitations | Nécessite des connaissances en codage, la précision peut être inférieure à celle des grands modèles cloud, manque d'une interface graphique prête à l'emploi |
En fin de compte, Vosk est la solution idéale pour les développeurs qui ont besoin d'un moteur de reconnaissance vocale hors ligne, personnalisable et libre de droits à intégrer directement dans leurs logiciels.
Site web : https://github.com/alphacep/vosk-api
9. Amazon Transcribe (AWS)
Pour les développeurs et les entreprises ayant besoin d'un moteur de transcription puissant et évolutif, Amazon Transcribe offre une solution robuste au sein de l'écosystème Amazon Web Services (AWS). Bien qu'il ne s'agisse pas d'une simple application grand public, il offre un niveau de logiciel de reconnaissance vocale gratuit généreux qui permet des tests approfondis et une utilisation à petite échelle. Transcribe excelle à la fois dans le streaming en temps réel et le traitement par lots de fichiers audio préenregistrés, ce qui le rend très polyvalent pour les applications techniques telles que l'analyse des centres d'appels ou l'indexation de contenu multimédia.
Ce qui le distingue, c'est sa suite de fonctionnalités de niveau entreprise, telles que la suppression automatique des informations personnellement identifiables (PII), la création de vocabulaires personnalisés pour améliorer la précision du jargon spécifique, et la diarisation des locuteurs. Son niveau gratuit, qui dure 12 mois, fournit suffisamment de temps de traitement pour construire et déployer une preuve de concept. Il s'agit d'un service axé sur l'API, conçu pour être intégré à d'autres logiciels plutôt que d'être utilisé comme un outil autonome.
Démarrage rapide et cas d'utilisation
Pour commencer, il faut créer un compte AWS et naviguer dans la console Amazon Transcribe. Vous pouvez créer un travail de transcription en téléchargeant un fichier audio directement depuis votre ordinateur ou un bucket S3. Ce service est idéal pour les développeurs qui créent des applications activées par la voix, les entreprises qui analysent les appels de service client pour l'assurance qualité, ou les sociétés de médias qui cherchent à générer automatiquement des sous-titres pour leurs catalogues vidéo à grande échelle.
| Analyse des fonctionnalités | Détails |
|---|---|
| Fonction principale | Transcription par lot et en temps réel pilotée par API |
| Accessibilité | Niveau gratuit pendant 12 mois, puis paiement à l'utilisation |
| Fonctionnalités clés | Suppression des PII, vocabulaires personnalisés, diarisation des locuteurs |
| Limitations | Nécessite un compte AWS ; peut être complexe pour les non-développeurs |
En fin de compte, Amazon Transcribe est la passerelle pour les utilisateurs qui ont besoin de capacités de reconnaissance vocale industrielles, hautement personnalisables, intégrées directement dans leurs propres produits et flux de travail.
Site web : https://aws.amazon.com/transcribe/
10. Google Cloud Speech‑to‑Text (API)
Pour les développeurs et les entreprises à la recherche d'un moteur de niveau entreprise, l'API Speech-to-Text de Google Cloud représente la technologie puissante qui sous-tend de nombreuses applications commerciales. Bien qu'il ne s'agisse pas d'un outil destiné au grand public, elle offre un niveau gratuit généreux sur son API v1, ce qui en fait une option viable de logiciel de reconnaissance vocale gratuit pour les utilisateurs techniques qui pilotent un projet ou gèrent des tâches de transcription à faible volume. Elle donne accès à des modèles très avancés optimisés pour différents types d'audio, y compris les appels téléphoniques et le contenu vidéo.
La plateforme se distingue par ses fonctionnalités puissantes comme la diarisation des locuteurs, l'amplification des mots-clés et la prise en charge de l'audio multi-canal, que l'on retrouve généralement dans les services payants. Cela en fait un choix solide pour les besoins de transcription complexes. Cependant, pour exploiter ses capacités, il faut un compte Google Cloud Platform (GCP), une configuration de facturation et une certaine expertise technique pour interagir avec l'API. Les minutes gratuites sont spécifiques à l'ancienne API v1, et les coûts peuvent s'accumuler une fois l'utilisation augmentée ou si les nouveaux modèles v2 sont requis.
Démarrage rapide et cas d'utilisation
Pour commencer, il faut configurer un projet GCP, activer l'API Speech-to-Text et utiliser une bibliothèque cliente (comme Python ou Node.js) pour envoyer des fichiers audio en vue de leur transcription. C'est idéal pour les développeurs qui créent des fonctionnalités de transcription dans leurs propres applications, les scientifiques des données qui analysent des ensembles de données audio, ou les entreprises qui ont besoin d'une transcription automatisée pour les enregistrements de centres d'appels. Elle excelle à la fois dans le streaming en temps réel et le traitement par lots de fichiers préenregistrés.
| Analyse des fonctionnalités | Détails |
|---|---|
| Fonction principale | API pour la transcription audio par lot et en temps réel |
| Accessibilité | Niveau gratuit disponible ; nécessite un compte GCP et une configuration de facturation |
| Fonctionnalités clés | Diarisation des locuteurs, amplification des mots-clés, modèles spécialisés |
| Limitations | Configuration technique requise, les coûts peuvent augmenter avec l'échelle |
En fin de compte, l'API de Google Cloud est une solution pour les utilisateurs techniques qui ont besoin d'un moteur de transcription puissant, évolutif et très précis pour des projets personnalisés.
Site web : https://cloud.google.com/speech-to-text
11. Live Transcribe (Android)
Pour les utilisateurs Android à la recherche d'un outil de transcription instantané axé sur l'accessibilité, Live Transcribe de Google se distingue comme un puissant logiciel de reconnaissance vocale gratuit. Développée principalement pour la communauté sourde et malentendante, cette application fournit des légendes en temps réel pour les conversations en direct, ce qui en fait un outil indispensable pour la communication en face à face. Elle transforme le microphone de votre téléphone en un appareil de transcription très précis, en déplacement.

Ce qui rend Live Transcribe unique, c'est son accent sur la conscience environnementale immédiate. Au-delà de la transcription de mots parlés dans plus de 70 langues, elle identifie également les sons non vocaux comme "aboiement de chien" ou "applaudissements", fournissant un contexte crucial. Bien qu'elle soit conçue pour l'interaction en direct et ne prenne pas en charge le téléchargement de fichiers, son option de traitement sur l'appareil offre une couche de confidentialité que l'on ne trouve pas toujours dans les services basés sur le cloud. Une utilisation continue peut affecter la batterie de votre appareil, il est donc utile d'apprendre à gérer les applications qui consomment de la batterie sur Android pour les utilisateurs intensifs.
Démarrage rapide et cas d'utilisation
Pour commencer, téléchargez Live Transcribe depuis le Google Play Store ou trouvez-le préinstallé sur les appareils Pixel. Ouvrez l'application, accordez les autorisations du microphone, et elle commencera immédiatement à transcrire le son ambiant. C'est parfait pour les étudiants en conférence, les professionnels en réunion impromptue, ou toute personne ayant besoin de comprendre le dialogue parlé dans un environnement bruyant. C'est une aide à l'accessibilité exceptionnelle, pas un outil pour la transcription post-production.
| Analyse des fonctionnalités | Détails |
|---|---|
| Fonction principale | Légendes en direct pour les conversations en personne |
| Accessibilité | Gratuit sur la plupart des appareils Android modernes |
| Fonctionnalités clés | Plus de 70 langues, étiquettes d'événements sonores, mode sur appareil |
| Limitations | Uniquement sur Android, pas de téléchargement de fichiers pour la transcription |
En fin de compte, Live Transcribe excelle à briser les barrières de communication en temps réel, offrant une solution simple mais puissante directement sur l'appareil que vous transportez tous les jours.
Site web : https://www.android.com/accessibility/live-transcribe/
12. Deepgram
Pour les développeurs et les startups cherchant à intégrer de puissantes capacités de transcription dans leurs propres applications, Deepgram offre une approche API-first très sophistiquée. Contrairement aux outils destinés aux utilisateurs finaux, Deepgram est un moteur conçu pour créer des solutions personnalisées, offrant 200 $ de crédits gratuits pour les nouveaux utilisateurs afin d'explorer ses capacités. Cette plateforme est reconnue pour sa vitesse, sa précision et ses fonctionnalités avancées comme la diarisation des locuteurs, l'amplification des mots-clés et la mise en forme intelligente, ce qui en fait un choix de premier ordre pour la reconnaissance vocale automatique (ASR) de niveau production.
Ce qui distingue Deepgram, c'est son orientation vers les modèles d'IA modernes, tels que sa série Nova, qui offrent une grande précision sur diverses qualités audio et accents. Bien qu'elle nécessite des connaissances techniques pour être mise en œuvre, la flexibilité qu'elle offre est inégalée pour ceux qui ont besoin de piloter ou de faire évoluer des services de transcription. Elle fonctionne comme une infrastructure puissante plutôt qu'un simple outil logiciel de reconnaissance vocale gratuit prêt à l'emploi.
Démarrage rapide et cas d'utilisation
Pour commencer, les développeurs peuvent s'inscrire pour obtenir une clé API gratuite et utiliser la documentation fournie pour envoyer des fichiers audio préenregistrés ou établir une connexion de streaming en temps réel. C'est une solution idéale pour les entreprises qui créent des assistants vocaux, les sociétés de médias qui automatisent la génération de sous-titres, ou les centres d'appels qui ont besoin d'analyser des données conversationnelles. Les crédits gratuits permettent des tests approfondis avant de s'engager dans un plan payant.
| Analyse des fonctionnalités | Détails |
|---|---|
| Fonction principale | API pour la transcription préenregistrée et en temps réel |
| Accessibilité | Gratuit pour commencer avec 200 $ de crédits ; paiement à l'utilisation |
| Fonctionnalités clés | Diarisation des locuteurs, amplification des mots-clés, choix du modèle |
| Limitations | Nécessite des connaissances en codage ; pas un outil pour les utilisateurs finaux |
En fin de compte, Deepgram est la solution pour les utilisateurs techniques qui ont besoin d'un moteur de transcription rapide, précis et évolutif pour alimenter leurs propres logiciels et produits.
Site web : https://deepgram.com
Comparaison de 12 outils de synthèse vocale
| Produit | Fonctionnalités principales ✨ | Précision et UX ★ | Prix / Valeur 💰 | Public cible 👥 |
|---|---|---|---|---|
| Transcript.LOL 🏆 | Base Whisper ; téléchargements de 10h ; étiquetage des locuteurs ; résumés, exportations, intégrations ✨ | ★4.8 (~99.8%) ; éditeur et recherche rapides | 💰 Niveau gratuit ; Illimité 120 $/an ; Équipe 240 $/an — haute valeur | 👥 Podcasteurs, spécialistes du marketing, éducateurs, équipes juridiques |
| Google Docs – Saisie vocale | Dictée dans le navigateur ; commandes vocales de base ✨ | ★3–4 ; idéal pour une dictée claire avec un seul locuteur | 💰 Gratuit avec un compte Google | 👥 Étudiants, écrivains, usage occasionnel |
| Microsoft Windows 11 – Accès vocal | Dictée sur l'appareil et contrôle du système ; prise en charge hors ligne ✨ | ★3–4 ; solide pour l'accessibilité ; nécessite un champ de texte | 💰 Inclus avec Windows 11 | 👥 Utilisateurs d'accessibilité ; partisans du hors ligne |
| Otter.ai | Transcription de réunions en direct ; identification des locuteurs ; notes consultables ; résumés ✨ | ★4 ; bonne expérience utilisateur pour les réunions ; multi-locuteurs dépend de l'audio | 💰 Freemium ; niveaux payants pour un volume plus élevé | 👥 Équipes, preneurs de notes de réunion |
| Descript | Montage audio/vidéo basé sur le texte ; suppression des mots de remplissage ; outils multipistes ✨ | ★4 ; excellent flux de travail éditeur + transcription | 💰 Plans payants (pas de gratuité permanente) — axé sur les créateurs | 👥 Podcasteurs, créateurs, éditeurs |
| OpenAI Whisper (open source) | ASR multilingue ; traduction ; CLI/bibliothèque Python ✨ | ★4 ; forte précision mais nécessite une configuration et une assurance qualité | 💰 Code gratuit ; les coûts de calcul s'appliquent | 👥 Développeurs, chercheurs, utilisateurs soucieux de la confidentialité |
| whisper.cpp | Port Whisper optimisé pour CPU ; modèles Apple Silicon et quantifiés ✨ | ★4 ; inférence CPU locale rapide (CLI) | 💰 Gratuit ; coûts de ressources locales et de stockage | 👥 Développeurs, utilisateurs hors ligne / Apple Silicon |
| Vosk (open source) | Petits modèles hors ligne ; multilingue ; nombreuses liaisons linguistiques ✨ | ★3–4 ; léger, la précision varie selon le modèle | 💰 Gratuit ; licence Apache-2.0 | 👥 Applications embarquées, environnements à faibles ressources |
| Amazon Transcribe (AWS) | Par lot et en streaming ; suppression des PII ; vocabulaires personnalisés ✨ | ★4 ; service d'entreprise évolutif | 💰 Paiement à la minute ; niveau gratuit limité de 12 mois | 👥 Développeurs, entreprises sur AWS |
| Google Cloud Speech‑to‑Text | Temps réel et par lot ; diarisation ; amplification des mots-clés ; multi-canal ✨ | ★4–5 ; forte précision et prise en charge linguistique | 💰 Paiement à l'utilisation ; minutes gratuites limitées | 👥 Entreprises, clients GCP, développeurs |
| Live Transcribe (Android) | Légendes en temps réel ; étiquettes sonores ; confidentialité sur l'appareil ✨ | ★4 ; fiable pour les conversations en face à face | 💰 Gratuit | 👥 Sourds/malentendants, utilisateurs quotidiens |
| Deepgram | API en streaming et préenregistrée ; diarisation ; amplification des mots-clés ✨ | ★4 ; API performante pour une utilisation en production | 💰 Crédits gratuits de 200 $ ; tarification à l'utilisation | 👥 Startups, développeurs, équipes de production |
Faire le bon choix : nos recommandations finales
🎯 Adaptez l'outil à votre type d'audio
Dictée en direct, réunions, podcasts ou fichiers pré-enregistrés – chaque outil est optimisé pour des scénarios audio spécifiques. Choisissez en fonction de la façon et du moment où votre audio est créé.
🔍 Équilibrez précision et effort
Une grande précision nécessite parfois une configuration ou une édition. Décidez si vous préférez une commodité instantanée ou des résultats de qualité professionnelle avec une révision mineure.
🔐 Décidez de l'importance de la confidentialité
Les outils cloud sont pratiques, mais les plateformes hors ligne ou sans apprentissage sont plus sûres pour les réunions sensibles, la recherche ou les conversations avec les clients.
💸 Pensez au-delà du niveau gratuit
Les plans gratuits sont parfaits pour tester, mais une utilisation à long terme peut nécessiter des mises à niveau. Comprenez les limites de minutes, d'exportations et de fonctionnalités avant de passer à l'échelle.
Naviguer dans le paysage des logiciels gratuits de reconnaissance vocale en texte peut sembler écrasant, mais comme nous l'avons exploré, le bon outil est rarement une solution universelle. Votre choix idéal dépend directement de vos besoins spécifiques, du type d'audio que vous transcrivez à vos priorités en matière de confidentialité, d'intégration de flux de travail et d'accès hors ligne. Le voyage de la parole à l'écrit est maintenant plus accessible que jamais, alimenté par une gamme variée d'outils puissants et souvent gratuits.
La reconnaissance vocale en texte n'est plus seulement de la transcription
Les outils modernes vont désormais au-delà de la transcription pour inclure la synthèse, la création de contenu et la collaboration. Choisir la bonne plateforme aujourd'hui peut pérenniser votre flux de travail à mesure que les capacités de l'IA continuent de s'étendre.
Tout au long de ce guide, nous avons disséqué tout, des outils simples intégrés au système d'exploitation aux modèles sophistiqués open-source et aux puissantes API basées sur le cloud. L'essentiel à retenir est que le "meilleur" logiciel de reconnaissance vocale est celui qui s'intègre parfaitement à votre flux de travail, et non celui qui possède la plus longue liste de fonctionnalités.
Points clés pour sélectionner votre outil
Pour synthétiser nos conclusions, revenons sur les facteurs de décision fondamentaux. Votre choix final sera probablement un compromis entre la commodité, la précision, le coût et le contrôle.
- Pour une utilisation quotidienne et instantanée : Si vos besoins sont simples, comme la rédaction d'e-mails, la prise de notes rapides ou la création de documents basiques, les solutions intégrées sont imbattables. La Saisie vocale de Google Docs et l'Accès vocal de Windows offrent une commodité incroyable sans aucune configuration, ce qui les rend parfaits pour les tâches spontanées.
- Pour les flux de travail collaboratifs et automatisés : Les équipes et les professionnels qui ont besoin de notes de réunion automatisées, d'identification des intervenants et de collaboration basée sur le cloud trouveront une immense valeur dans des services tels que Otter.ai et Descript. Leurs niveaux gratuits offrent un point de départ généreux pour rationaliser les flux de travail de transcription complexes.
- Pour une confidentialité et un contrôle maximum : Lorsque la confidentialité des données est non négociable ou que vous devez traiter des informations sensibles, les modèles open-source hors ligne sont la référence. OpenAI Whisper et son homologue efficace, whisper.cpp, offrent une précision de pointe tout en garantissant que vos données ne quittent jamais votre machine locale.
- Pour les besoins spécialisés et à haut volume : Les développeurs et les entreprises qui exigent une transcription évolutive et de haute précision pour leurs applications devraient se tourner vers les puissantes API proposées par Google Cloud Speech-to-Text, Amazon Transcribe et Deepgram. Leurs niveaux gratuits sont conçus pour vous permettre de construire et de tester avant de vous engager dans un plan payant.
Prochaines étapes concrètes pour la mise en œuvre
Maintenant que vous avez une vision plus claire des options disponibles, il est temps de passer à l'action. Ne vous laissez pas paralyser par l'analyse ; la meilleure façon de trouver la solution idéale est de commencer à expérimenter.
- Identifiez votre cas d'utilisation principal : Êtes-vous un podcasteur ayant besoin de transcriptions d'épisodes, un étudiant enregistrant des cours, ou un développeur créant une application à commande vocale ? Définissez d'abord votre exigence la plus importante.
- Testez vos deux principaux candidats : En fonction de votre besoin principal, sélectionnez deux outils de notre liste qui semblent les plus prometteurs. Par exemple, si vous êtes un créateur de vidéos, vous pourriez comparer le niveau gratuit de Descript avec une installation locale de Whisper.
- Effectuez un test en conditions réelles : Utilisez un fichier audio court et représentatif (5 à 10 minutes) et traitez-le avec les deux outils. Comparez les résultats en fonction de la précision, de la mise en forme, de la vitesse et de l'expérience utilisateur globale. Un outil a-t-il mieux géré le jargon ou plusieurs intervenants ? Le processus d'édition était-il plus facile avec l'un qu'avec l'autre ?
- Évaluez l'impact sur le flux de travail : Considérez comment chaque outil s'intègre dans votre processus existant. Nécessite-t-il des étapes supplémentaires, ou vous fait-il gagner du temps ? Le meilleur logiciel de reconnaissance vocale ne produit pas seulement une excellente transcription, mais rend également l'ensemble de votre flux de travail plus efficace.
En fin de compte, la puissance de la technologie moderne de reconnaissance vocale réside dans sa capacité à libérer la valeur enfermée dans votre contenu audio et vidéo. En transformant les mots prononcés en texte consultable, modifiable et partageable, vous ouvrez de nouvelles possibilités pour la création de contenu, l'accessibilité, la recherche et la productivité. L'outil parfait attend d'être intégré à votre flux de travail, prêt à vous faire gagner du temps et des efforts.
Prêt à découvrir un outil de transcription qui privilégie la confidentialité, la précision et un flux de travail magnifiquement simple ? Bien que de nombreux outils gratuits présentent des limitations en matière de confidentialité ou de fonctionnalités, Transcript.LOL est conçu pour les professionnels qui ont besoin de transcriptions fiables et sécurisées sans la complexité. Offrez à votre audio la transcription privée et de haute qualité qu'il mérite en essayant Transcript.LOL dès aujourd'hui.