Las 12 mejores opciones de software gratuito de voz a texto en 2026...
Descubre las 12 mejores herramientas de software gratuito de voz a texto para 2026. Compara características, precisión y privacidad para encontrar la solución perfecta para ti.
Praveen
January 12, 2026
De palabras habladas a texto digital: tu guía definitiva de software de voz a texto
Transcribir manualmente contenido de audio y video es una tarea tediosa y que consume mucho tiempo. Ya sea que seas un podcaster que crea notas del programa, un especialista en marketing que reutiliza contenido de video para un blog o un estudiante que captura detalles de conferencias, convertir palabras habladas en texto preciso es un cuello de botella crítico. El software gratuito de voz a texto adecuado puede eliminar esta fricción, ahorrándote horas de esfuerzo y desbloqueando un nuevo potencial para tu contenido. Esta guía está diseñada para ayudarte a encontrar la herramienta perfecta para tus necesidades específicas, cortando el ruido para comparar las mejores opciones disponibles hoy.
¿Por qué la voz a texto es una mejora del flujo de trabajo?
Las herramientas de voz a texto no solo reemplazan la escritura, sino que mejoran fundamentalmente la forma en que se captura, reutiliza y distribuye la información. Una vez que el audio se convierte en texto, se vuelve buscable, editable y reutilizable al instante en blogs, correos electrónicos, informes y redes sociales.
Hemos evaluado una amplia gama de soluciones, desde herramientas de dictado sencillas y preinstaladas hasta potentes plataformas de transcripción impulsadas por IA. Para cada opción, proporcionamos un desglose detallado que cubre características clave, niveles de precisión, consideraciones de privacidad y casos de uso ideales. Encontrará enlaces directos y capturas de pantalla para ver cómo funciona cada plataforma, junto con evaluaciones honestas de sus pros y contras. Exploraremos todo, desde la precisión centrada en la privacidad de Transcript.LOL hasta la comodidad omnipresente de la escritura por voz de Google Docs y la potencia sin conexión de modelos de código abierto como Whisper de OpenAI.
A medida que exploramos estas soluciones, es importante reconocer cómo estas herramientas impulsadas por IA contribuyen a la tendencia más amplia de cómo la IA está transformando la creación de contenido para las PYMES. Este cambio hace que la tecnología de transcripción sofisticada sea más accesible que nunca, permitiendo a los creadores y profesionales optimizar sus flujos de trabajo de manera significativa. Esta lista curada servirá como su recurso definitivo, ayudándole a seleccionar el software más eficaz para convertir su audio en texto buscable, editable y compartible, sin el alto costo o el trabajo manual.
IA de última generación
Impulsado por Whisper de OpenAI para una precisión líder en la industria. Soporte para vocabularios personalizados, archivos de hasta 10 horas y resultados ultra rápidos.

Importar desde múltiples fuentes
Importa archivos de audio y video desde diversas fuentes, incluyendo carga directa, Google Drive, Dropbox, URLs, Zoom y más.
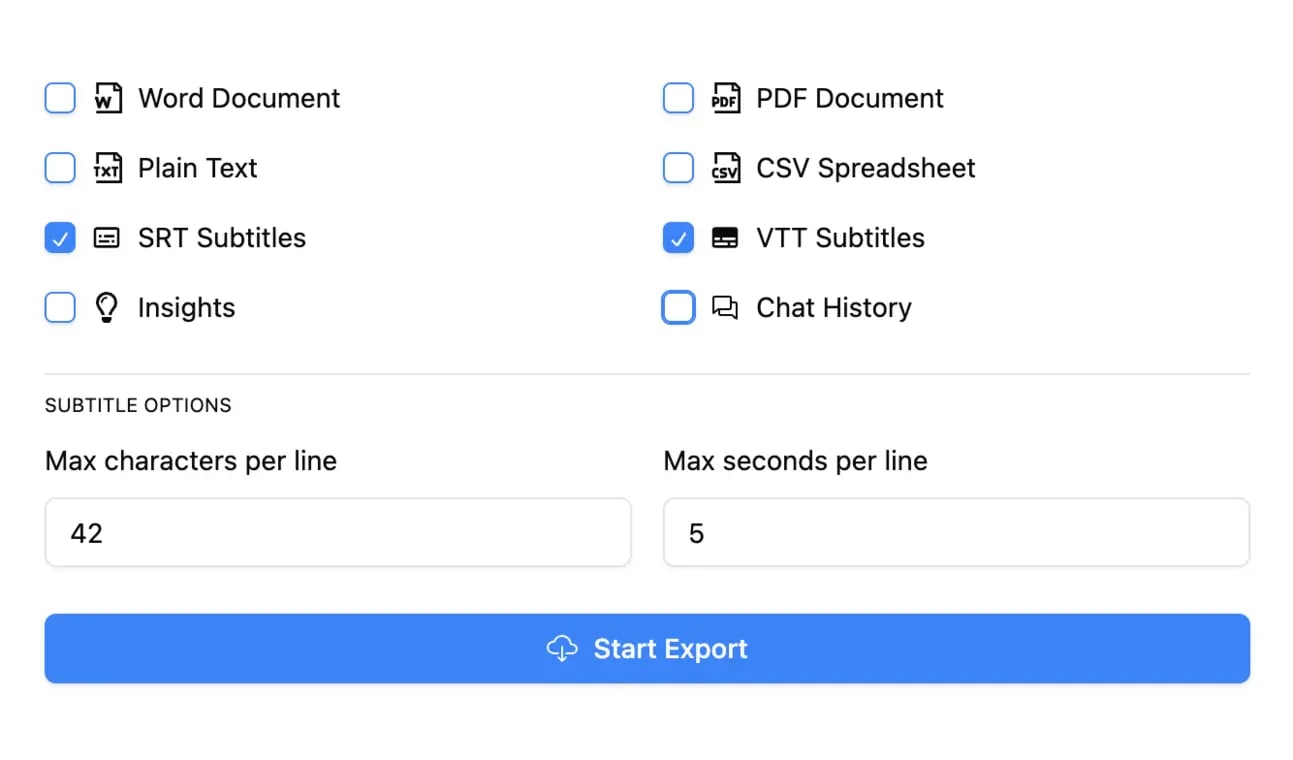
Exportar en múltiples formatos
Exporta tus transcripciones en múltiples formatos incluyendo TXT, DOCX, PDF, SRT y VTT con opciones de formato personalizables.
1. Transcript.LOL
Transcript.LOL se erige como una opción principal para profesionales que buscan transcripciones robustas impulsadas por IA que combinen una precisión excepcional con potentes herramientas de creación de contenido. Es más que un simple convertidor de voz a texto; es una plataforma de flujo de trabajo integrada diseñada para convertir audio y video sin procesar en activos pulidos y listos para usar en minutos, lo que la convierte en una de las principales candidatas para el mejor software gratuito de voz a texto disponible en la actualidad.
Su fortaleza principal radica en el aprovechamiento de una versión afinada del motor Whisper de OpenAI, que ofrece una tasa de precisión anunciada de ~99.8%. Esta precisión se mejora con el soporte de vocabulario personalizado, lo que garantiza que los términos especializados, nombres y jerga de la industria se capturen correctamente, una característica crítica para usuarios en campos técnicos, académicos o médicos.
Diferenciadores Clave y Casos de Uso
Lo que realmente distingue a Transcript.LOL es su extenso conjunto de funciones posteriores a la transcripción. Más allá de proporcionar una transcripción literal, la plataforma genera automáticamente contenido valioso como resúmenes, elementos de acción, cuestionarios e incluso publicaciones en redes sociales. Esto transforma la herramienta de una utilidad simple a un importante ahorro de tiempo para especialistas en marketing, educadores y creadores de contenido.

Detección de hablantes
Identifica automáticamente diferentes hablantes en tus grabaciones y etiquétalos con sus nombres.
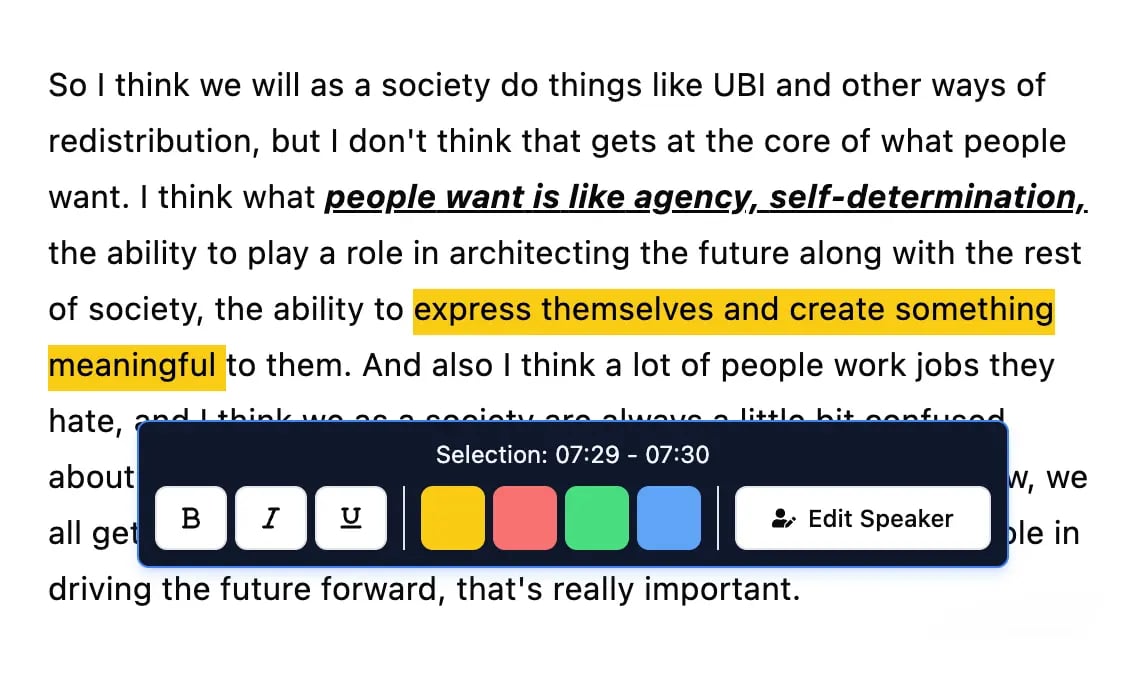
Herramientas de edición
Edita transcripciones con herramientas potentes como buscar y reemplazar, asignación de hablantes, formatos de texto enriquecido y resaltado.
Resúmenes y Chatbot
Genera resúmenes y otros análisis de tu transcripción, prompts personalizados reutilizables y chatbot para tu contenido.
- Para Creadores de Contenido y Profesionales del Marketing: Convierte rápidamente un podcast o webinar en una publicación de blog, notas del programa y una serie de actualizaciones para redes sociales. La capacidad de manejar archivos de hasta 10 horas de duración lo hace ideal para contenido de formato largo.
- Para Equipos y Empresas: Los espacios de trabajo compartidos de la plataforma, la organización de carpetas y las integraciones (Zoom, Zapier, Google Drive) agilizan los procesos de revisión colaborativa. Transcribir grabaciones de reuniones y generar elementos de acción se convierte en una tarea automatizada y eficiente.
- Para Investigadores y Estudiantes: La alta precisión y el soporte para diversas fuentes de importación (incluidas URL directas) lo hacen perfecto para transcribir conferencias, entrevistas y audio de investigación con confianza.
Enfoque centrado en la privacidad: Una ventaja significativa es la estricta política de no entrenamiento de Transcript.LOL. Tus datos no se utilizan para entrenar modelos de IA, un compromiso crucial para los usuarios que manejan información sensible o propietaria.
Desglose de la Plataforma
| Característica | Detalles |
|---|---|
| Precisión y Velocidad | Utiliza OpenAI Whisper con vocabulario personalizado para resultados de alta precisión casi en tiempo real. |
| Manejo de Archivos | Acepta cargas únicas de hasta 10 horas / 5 GB. Soporta varios formatos e importaciones directas desde servicios en la nube, Zoom y URL. |
| Herramientas de Contenido IA | Genera resúmenes, cuestionarios, mapas mentales, publicaciones de blog, copias para redes sociales y más directamente de la transcripción. |
| Colaboración | Presenta espacios de trabajo compartidos, búsqueda robusta e integraciones con Zapier, WhatsApp, Telegram y los principales proveedores de almacenamiento en la nube. |
| Precios | Nivel Gratuito: 2 transcripciones/día (máximo 20 minutos cada una). Plan Ilimitado: $120/año para uso ilimitado, cargas largas y todas las funciones de IA. |
| Seguridad | Aplica una política estricta de no entrenamiento sobre los datos del cliente y trabaja con subprocesadores para evitar la reutilización de datos. |
Cómo Empezar
- Regístrate: Crea una cuenta gratuita en el sitio web.
- Sube: Arrastra y suelta tu archivo de audio/video, o impórtalo desde Google Drive, Zoom, una URL u otros servicios conectados.
- Transcribe: La IA procesa el archivo, detecta automáticamente a los hablantes y genera la transcripción.
- Refina y Exporta: Utiliza el editor de texto enriquecido para realizar ajustes. Luego, aprovecha las herramientas de IA para crear resúmenes u otro contenido y exporta en el formato deseado (DOCX, SRT, PDF, etc.).
Para una comparación más detallada de sus características frente a otras opciones del mercado, puedes explorar el análisis proporcionado en esta guía de software de voz a texto.
Sitio Web: https://transcript.lol
2. Google Docs – Dictado por Voz
Para los usuarios ya integrados en el ecosistema de Google, el software gratuito de voz a texto más accesible es probablemente el que está integrado directamente en las herramientas que utilizan a diario. La función de Dictado por Voz de Google Docs es una potencia de conveniencia, que ofrece dictado basado en navegador y sin instalación para cualquier persona con una cuenta de Google y el navegador Chrome. Sobresale en la conversión de palabras habladas a texto en tiempo real, lo que lo hace ideal para redactar documentos, tomar notas rápidas o superar el bloqueo del escritor.
Lo que hace que el Dictado por Voz sea tan efectivo es su simplicidad y precisión sorprendente para el dictado claro de un solo hablante. Soporta una gran cantidad de idiomas e incluso reconoce comandos de formato básicos como "nuevo párrafo" o "pon eso en negrita". Si bien carece de las funciones avanzadas de los servicios de transcripción dedicados, como la identificación de hablantes o la marca de tiempo, su fortaleza radica en su integración sin fricciones en el flujo de trabajo de un escritor.
Inicio Rápido y Caso de Uso
Para empezar, simplemente abre un Documento de Google, navega a Herramientas > Dictado por voz y haz clic en el icono del micrófono. Esta es una herramienta perfecta para estudiantes que redactan ensayos, creadores de contenido que esbozan guiones o profesionales que capturan actas de reuniones a medida que ocurren. Es una herramienta de dictado directo y en vivo, no un servicio para subir archivos de audio pregrabados.
| Análisis de Características | Detalles |
|---|---|
| Función Principal | Dictado en vivo directamente en un documento |
| Accesibilidad | Gratuito con una cuenta de Google; funciona en Chrome |
| Características Clave | Soporte multilingüe, comandos de voz básicos |
| Limitaciones | Sin cargas de archivos, sin diarización de hablantes |
En última instancia, la herramienta de Google es la opción principal para la creación de documentos inmediata y sencilla sin software adicional. Para una inmersión más profunda en lo que influye en los resultados de la transcripción, puedes obtener más información sobre los factores que afectan la precisión del voz a texto.
Sitio Web: https://docs.google.com
3. Microsoft Windows 11 – Acceso por Voz y Dictado por Voz
Para los usuarios de Windows 11, un software gratuito de voz a texto potente y consciente de la privacidad ya está integrado directamente en el sistema operativo. El Acceso por Voz y el Dictado por Voz en Windows 11 proporcionan un dictado robusto en el dispositivo que funciona en todo el sistema, desde procesadores de texto hasta navegadores web. Esta solución integrada es excelente para los usuarios que priorizan la funcionalidad sin conexión y desean mantener sus datos locales, ya que el reconocimiento de voz se realiza en el propio dispositivo.
Ofrece un dictado fluido con puntuación automática y admite comandos de voz para la edición de texto y la navegación del sistema, como abrir aplicaciones o hacer clic en botones. Esto lo convierte en una herramienta formidable tanto para la accesibilidad como para la productividad general, lo que le permite controlar su PC y redactar texto sin tocar el teclado. Si bien sus funciones más avanzadas están optimizadas para el inglés de EE. UU., proporciona una experiencia fluida sin necesidad de instalaciones ni cuentas de terceros.
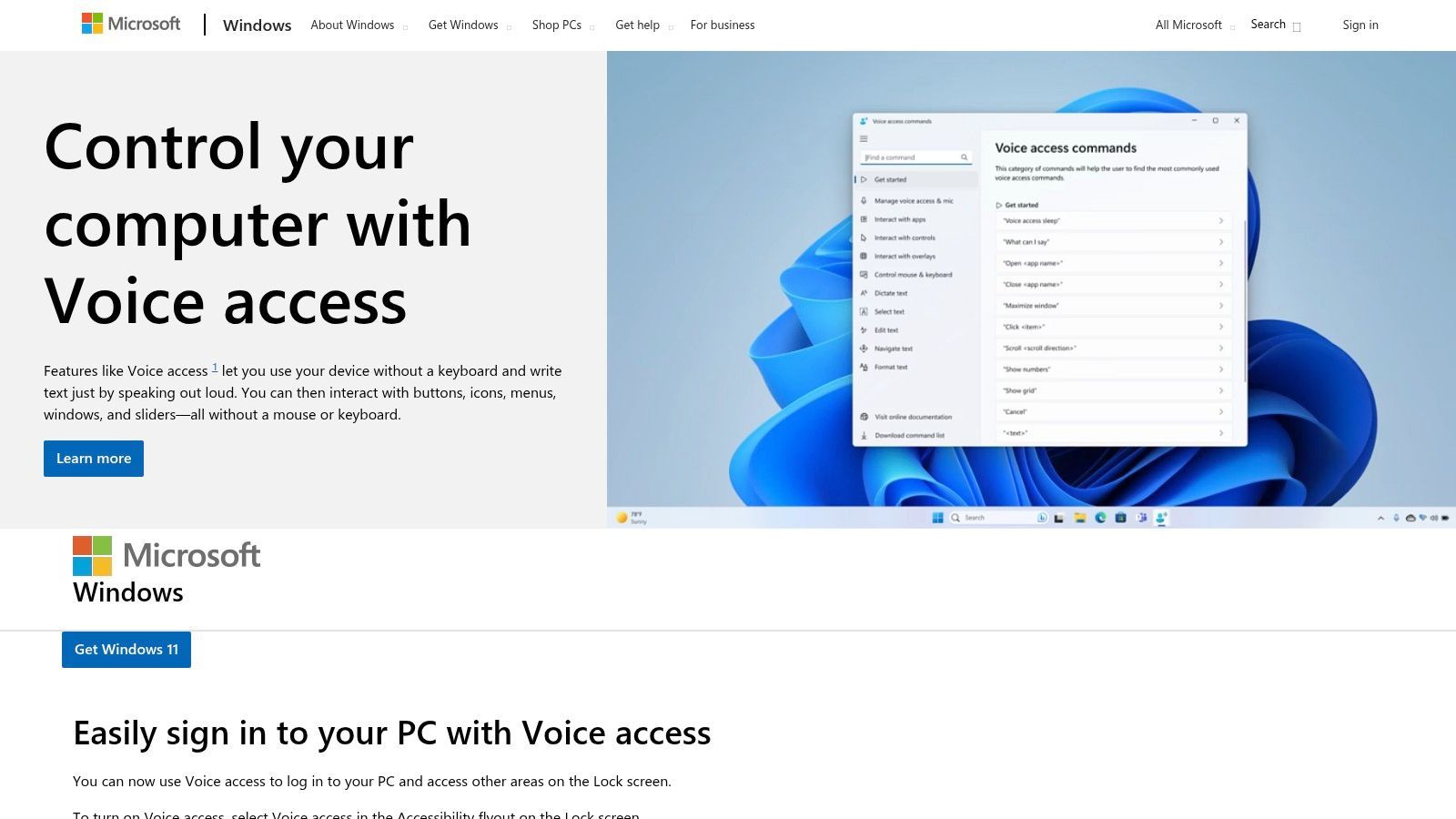
Inicio Rápido y Caso de Uso
Para iniciar el Dictado por Voz, simplemente presiona la tecla del logotipo de Windows + H en cualquier campo de texto activo. Para un control completo del sistema, habilita el Acceso por Voz en Configuración > Accesibilidad > Voz. Esta es una solución ideal para profesionales que redactan correos electrónicos directamente en Outlook, estudiantes que toman notas en OneNote o cualquier usuario que busque reducir la dependencia de su teclado para las tareas informáticas diarias.
| Análisis de Características | Detalles |
|---|---|
| Función Principal | Dictado en vivo en todo el sistema y control de PC |
| Accesibilidad | Gratuito e integrado en Windows 11 |
| Características Clave | Procesamiento en el dispositivo, uso sin conexión, comandos de voz |
| Limitaciones | El soporte de idiomas varía; mejor en inglés de EE. UU. |
En última instancia, las herramientas nativas de Windows 11 son la mejor opción para los usuarios que buscan una solución de dictado integrada, segura y capaz de funcionar sin conexión que funcione en todas sus aplicaciones.
Sitio Web: https://www.microsoft.com/en-us/windows/tips/voice-access
4. Otter.ai
Para aquellos que necesitan más que un simple dictado, Otter.ai se posiciona como un potente asistente de reuniones con IA. Se destaca como un software gratuito de voz a texto de primer nivel diseñado específicamente para transcribir conversaciones, reuniones y entrevistas. Su principal fortaleza radica en su capacidad para manejar múltiples hablantes, identificando y etiquetando quién dijo qué en tiempo real o a partir de un archivo de audio, lo que lo hace invaluable para entornos colaborativos.
Lo que hace que Otter.ai sea particularmente útil para los equipos es su integración con plataformas como Zoom, Google Meet y Microsoft Teams. La IA genera notas buscables, elementos de acción y resúmenes concisos de las conversaciones, transformando discusiones desordenadas en registros organizados y accionables. El generoso nivel gratuito proporciona una cantidad sustancial de minutos de transcripción por mes, aunque con algunas limitaciones en la duración de la importación y las funciones en comparación con sus planes de pago.
Inicio Rápido y Caso de Uso
Para empezar, regístrate para obtener una cuenta gratuita y conéctala a tu calendario para que el Asistente Otter se una y transcriba automáticamente tus reuniones virtuales. También puedes grabar conversaciones directamente o subir archivos de audio. Es una herramienta perfecta para gerentes de proyectos que capturan reuniones de equipo, periodistas que realizan entrevistas o estudiantes que graban conferencias para su revisión posterior. Si eres nuevo en este proceso, comprender cómo transcribir audio a texto de forma gratuita puede proporcionar una base sólida.
| Análisis de Características | Detalles |
|---|---|
| Función Principal | Transcripción de reuniones en vivo y toma de notas |
| Accesibilidad | Modelo Freemium con aplicaciones web y móviles |
| Características Clave | Identificación de hablantes, resúmenes de IA, integraciones de reuniones |
| Limitaciones | El nivel gratuito tiene límites en la duración de la importación y los minutos mensuales |
En última instancia, Otter.ai es la opción ideal para cualquiera que necesite capturar, organizar y compartir información de conversaciones con múltiples hablantes, cerrando la brecha entre el audio crudo y las notas estructuradas.
Sitio Web: https://otter.ai
5. Descript
Descript va más allá del simple dictado, posicionándose como un editor de audio y video todo en uno impulsado por texto. Para podcasters, YouTubers y creadores de contenido, es una herramienta revolucionaria que fusiona el proceso de transcripción directamente con la edición de medios. En lugar de simplemente proporcionar una transcripción, Descript te permite editar tu video o audio simplemente editando el texto, lo que lo convierte en un software gratuito de voz a texto increíblemente intuitivo para la producción de medios.
Lo que hace que Descript sea único es su flujo de trabajo basado en transcripciones. Eliminar una palabra o frase en el texto la corta automáticamente del archivo de audio o video, con transiciones fluidas. También incluye potentes funciones de IA como la eliminación de palabras de relleno ("um", "uh") con un solo clic y una función "Overdub" para crear un clon de IA de tu voz para corregir errores. Si bien su nivel gratuito es más una prueba con horas de transcripción limitadas, ofrece una muestra completa de este potente paradigma de edición.
Inicio Rápido y Caso de Uso
Para empezar, regístrate para obtener una cuenta gratuita, crea un nuevo proyecto y arrastra y suelta tu archivo de audio o video. Descript lo transcribirá automáticamente, presentándote el editor basado en texto. Esto es ideal para podcasters que limpian entrevistas, profesionales del marketing que crean clips para redes sociales a partir de videos de formato largo, o equipos corporativos que editan webinars y materiales de capacitación sin necesidad de software de edición de video complejo.
| Análisis de Características | Detalles |
|---|---|
| Función Principal | Edición de audio/video integrada basada en texto |
| Accesibilidad | Nivel de prueba gratuita con horas limitadas; requiere plan de pago para uso continuo |
| Características Clave | Eliminación de palabras de relleno, limpieza de audio con IA (Studio Sound), edición multipista |
| Limitaciones | No hay plan gratuito permanente; puede tener una curva de aprendizaje para funciones avanzadas |
En última instancia, Descript es la mejor opción para cualquiera cuyas necesidades de transcripción estén directamente relacionadas con la creación de contenido y la edición de medios, ofreciendo un flujo de trabajo que ningún servicio de transcripción tradicional puede igualar.
Sitio Web: https://www.descript.com
6. OpenAI Whisper (código abierto)
Para desarrolladores y usuarios con experiencia técnica, Whisper de OpenAI representa la cúspide del software gratuito de voz a texto de código abierto. En lugar de un servicio web listo para usar, Whisper es una colección de potentes modelos de reconocimiento automático de voz (ASR) que puedes ejecutar en tu propio hardware. Este enfoque proporciona un control sin precedentes sobre la privacidad y elimina los costos continuos de transcripción por minuto, ya que el único gasto es la potencia informática requerida.
Whisper es conocido por su excepcional precisión en una amplia gama de idiomas y su capacidad para manejar audio desafiante con ruido de fondo. Su verdadera fortaleza radica en su flexibilidad; se puede integrar en aplicaciones personalizadas, utilizar para el procesamiento por lotes de grandes volúmenes de archivos de audio e incluso realizar traducciones directas de voz a inglés. Si bien exige una configuración técnica, la compensación es un motor de transcripción de calidad profesional sin las tarifas recurrentes de los servicios comerciales.
Inicio Rápido y Caso de Uso
Comenzar implica instalar Python y la biblioteca Whisper desde su repositorio de GitHub. A partir de ahí, puedes ejecutar transcripciones a través de la línea de comandos en tus archivos de audio locales. Es ideal para investigadores que analizan grandes conjuntos de datos de audio, desarrolladores que integran funciones de transcripción en sus aplicaciones o podcasters que desean procesar por lotes todo su catálogo anterior de forma privada y rentable.
| Análisis de Características | Detalles |
|---|---|
| Función Principal | Transcripción de alta precisión de archivos de audio |
| Accesibilidad | Gratuito y de código abierto; requiere configuración local (Python, GPU) |
| Características Clave | Múltiples tamaños de modelo, soporte multilingüe, traducción |
| Limitaciones | Requiere configuración técnica, sin dictado en tiempo real, puede alucinar |
En última instancia, Whisper es la opción para aquellos que priorizan el control, la privacidad y la precisión sobre la conveniencia lista para usar. Puedes descubrir más sobre cómo modelos como este encajan en el panorama más amplio del software de transcripción impulsado por IA.
Sitio Web: https://github.com/openai/whisper
7. whisper.cpp (puerto C/C++ de Whisper)
Para desarrolladores y usuarios conscientes de la privacidad que buscan transcripción local de alto rendimiento, whisper.cpp ofrece una alternativa potente a los servicios basados en la nube. Este proyecto es un puerto C/C++ del modelo Whisper de OpenAI, optimizado para un rendimiento eficiente de la CPU, incluido el soporte nativo para Apple Silicon. Como herramienta de línea de comandos, ofrece una experiencia robusta de software gratuito de voz a texto completamente sin conexión, lo que garantiza que ningún dato abandone nunca su máquina. Es la solución ideal para procesar audio sensible sin depender de servidores externos o dependencias de Python.
Lo que distingue a whisper.cpp es su pura eficiencia y portabilidad. Se ejecuta sin una pila de software pesada, lo que lo hace rápido y respetuoso con los recursos en portátiles y ordenadores de escritorio modernos. Al utilizar modelos cuantificados, equilibra una alta precisión con tamaños de archivo y velocidades de procesamiento manejables, lo que lo hace accesible incluso sin una GPU potente. Si bien su interfaz de línea de comandos requiere cierta comodidad técnica, la compensación es un control, privacidad y rendimiento sin precedentes para la transcripción de audio sin conexión.
Inicio Rápido y Caso de Uso
Comenzar implica clonar el repositorio de GitHub, compilar el código y descargar un modelo Whisper preentrenado. Desde la terminal, ejecutas un comando simple que apunta a tu archivo de audio. Esta herramienta es perfecta para periodistas que transcriben entrevistas sensibles, investigadores que procesan grabaciones de campo sin conexión a Internet, o desarrolladores que integran capacidades de transcripción directamente en aplicaciones locales.
| Análisis de Características | Detalles |
|---|---|
| Función Principal | Transcripción de archivos de audio sin conexión y de alto rendimiento |
| Accesibilidad | Gratuito y de código abierto; requiere compilación |
| Características Clave | Optimizado para Apple Silicon/AVX, no necesita Python, cuantificación de modelos |
| Limitaciones | Solo línea de comandos (sin GUI), requiere descarga e instalación manual del modelo |
En última instancia, whisper.cpp es la opción para usuarios que priorizan la privacidad y el rendimiento y se sienten cómodos trabajando dentro de un entorno de terminal.
Sitio Web: https://github.com/ggml-org/whisper.cpp
8. Vosk (código abierto, sin conexión)
Para desarrolladores y usuarios conscientes de la privacidad que buscan un control total sobre sus datos, Vosk se destaca como un potente kit de herramientas gratuito de voz a texto sin conexión. A diferencia de los servicios basados en la nube, Vosk se ejecuta completamente en su máquina local, desde un ordenador de escritorio hasta una Raspberry Pi. Esto lo convierte en una opción fantástica para integrar el reconocimiento de voz en aplicaciones donde la conectividad a Internet es poco fiable o la privacidad de los datos es una preocupación principal.
Su ventaja clave radica en sus modelos ligeros y eficientes y su amplio soporte para varios lenguajes de programación. Vosk proporciona a los desarrolladores los bloques de construcción para crear aplicaciones personalizadas habilitadas por voz, desde asistentes domésticos inteligentes hasta sistemas de comandos en el automóvil, sin enviar ningún audio a servidores de terceros. Ofrece un grado excepcional de flexibilidad para proyectos que requieren procesamiento sin conexión.
Inicio Rápido y Caso de Uso
Comenzar implica integrar la biblioteca Vosk en un proyecto utilizando un lenguaje como Python o Java. Un desarrollador descargaría un modelo de lenguaje preentrenado y luego usaría la API de Vosk para el reconocimiento de transmisión en tiempo real. Es ideal para crear interfaces de control de voz para aplicaciones de escritorio, transcribir audio en un entorno seguro o crear funciones activadas por voz para sistemas integrados. Su licencia permisiva Apache 2.0 también lo hace adecuado para uso comercial.
| Análisis de Características | Detalles |
|---|---|
| Función Principal | Kit de herramientas de reconocimiento de voz sin conexión para desarrolladores |
| Accesibilidad | Gratuito y de código abierto (licencia Apache 2.0) |
| Características Clave | Modelos sin conexión ligeros, soporta más de 20 idiomas, enlaces para muchos lenguajes de programación |
| Limitaciones | Requiere conocimientos de codificación, la precisión puede ser menor que la de los grandes modelos en la nube, carece de una GUI lista para usar |
En última instancia, Vosk es la opción principal para los desarrolladores que necesitan un motor de reconocimiento de voz sin conexión, personalizable y libre de regalías para integrarlo directamente en su software.
Sitio Web: https://github.com/alphacep/vosk-api
9. Amazon Transcribe (AWS)
Para desarrolladores y empresas que necesitan un motor de transcripción potente y escalable, Amazon Transcribe ofrece una solución robusta dentro del ecosistema de Amazon Web Services (AWS). Si bien no es una aplicación simple para el consumidor, proporciona un generoso nivel gratuito de software de voz a texto que permite pruebas extensas y uso a pequeña escala. Transcribe sobresale tanto en la transmisión en tiempo real como en el procesamiento por lotes de archivos de audio pregrabados, lo que lo hace muy versátil para aplicaciones técnicas como análisis de centros de llamadas o indexación de contenido multimedia.
Lo que lo distingue es su conjunto de funciones de nivel empresarial, como la redacción automática de Información de Identificación Personal (PII), la creación de vocabularios personalizados para mejorar la precisión de la jerga específica y la diarización de hablantes. Su nivel gratuito, que dura 12 meses, proporciona tiempo de procesamiento suficiente para crear e implementar una prueba de concepto. Es un servicio basado en API, diseñado para integrarse en otro software en lugar de usarse como una herramienta independiente.
Inicio Rápido y Caso de Uso
Para empezar, crea una cuenta de AWS y navega a la consola de Amazon Transcribe. Puedes crear un trabajo de transcripción cargando un archivo de audio directamente desde tu ordenador o un bucket de S3. Este servicio es ideal para desarrolladores que crean aplicaciones habilitadas por voz, empresas que analizan llamadas de atención al cliente para garantizar la calidad o empresas de medios que buscan generar automáticamente subtítulos para sus catálogos de video a escala.
| Análisis de Características | Detalles |
|---|---|
| Función Principal | Transcripción por lotes y en tiempo real impulsada por API |
| Accesibilidad | Nivel gratuito durante 12 meses, luego pago por uso |
| Características Clave | Redacción de PII, vocabularios personalizados, diarización de hablantes |
| Limitaciones | Requiere cuenta de AWS; puede ser complejo para no desarrolladores |
En última instancia, Amazon Transcribe es la puerta de entrada para los usuarios que necesitan capacidades de voz a texto industriales, altamente personalizables e integradas directamente en sus propios productos y flujos de trabajo.
Sitio Web: https://aws.amazon.com/transcribe/
10. Google Cloud Speech‑to‑Text (API)
Para desarrolladores y empresas que buscan un motor de nivel empresarial, la API de Speech-to-Text de Google Cloud representa la potente tecnología que sustenta muchas aplicaciones comerciales. Si bien no es una herramienta orientada al usuario, ofrece un generoso nivel gratuito en su API v1, lo que la convierte en una opción viable de software gratuito de voz a texto para usuarios técnicos que están probando un proyecto o manejando tareas de transcripción de bajo volumen. Proporciona acceso a modelos altamente avanzados optimizados para diferentes tipos de audio, incluidas llamadas telefónicas y contenido de video.
La plataforma se destaca por sus potentes funciones como la diarización de hablantes, el impulso de palabras clave y el soporte de audio multicanal, que generalmente se encuentran en servicios de pago. Esto la convierte en una opción sólida para necesidades de transcripción complejas. Sin embargo, aprovechar sus capacidades requiere una cuenta de Google Cloud Platform (GCP), configuración de facturación y algunos conocimientos técnicos para interactuar con la API. Los minutos gratuitos son específicos de la API v1 más antigua, y los costos pueden acumularse una vez que la escala de uso o si se requieren modelos v2 más nuevos.
Inicio Rápido y Caso de Uso
Para empezar, habilita un proyecto de GCP, activa la API de Speech-to-Text y utiliza una biblioteca cliente (como Python o Node.js) para enviar archivos de audio para su transcripción. Esto es ideal para desarrolladores que crean funciones de transcripción en sus propias aplicaciones, científicos de datos que analizan conjuntos de datos de audio o empresas que necesitan transcripción automatizada para grabaciones de centros de llamadas. Sobresale tanto en la transmisión en tiempo real como en el procesamiento por lotes de archivos pregrabados.
| Análisis de Características | Detalles |
|---|---|
| Función Principal | API para transcripción de audio por lotes y en tiempo real |
| Accesibilidad | Nivel gratuito disponible; requiere cuenta de GCP y configuración de facturación |
| Características Clave | Diarización de hablantes, impulso de palabras clave, modelos especializados |
| Limitaciones | Requiere configuración técnica, los costos pueden aumentar con la escala |
En última instancia, la API de Google Cloud es una solución para usuarios técnicos que necesitan un motor de transcripción potente, escalable y altamente preciso para proyectos personalizados.
Sitio Web: https://cloud.google.com/speech-to-text
11. Transcripción en Vivo (Android)
Para los usuarios de Android que buscan una herramienta de transcripción instantánea centrada en la accesibilidad, Live Transcribe de Google se destaca como una potente pieza de software gratuito de voz a texto. Desarrollada principalmente para la comunidad de personas sordas y con problemas de audición, esta aplicación proporciona subtítulos en tiempo real para conversaciones en vivo, lo que la convierte en una herramienta indispensable para la comunicación cara a cara. Convierte el micrófono de tu teléfono en un dispositivo de transcripción altamente preciso y sobre la marcha.

Lo que hace que Live Transcribe sea único es su enfoque en la conciencia ambiental inmediata. Más allá de transcribir palabras habladas en más de 70 idiomas, también identifica sonidos que no son de habla como "ladrido de perro" o "aplausos", proporcionando un contexto crucial. Si bien está diseñado para la interacción en vivo y no admite la carga de archivos, su opción de procesamiento en el dispositivo ofrece una capa de privacidad que no siempre se encuentra en los servicios basados en la nube. El uso continuo puede afectar la energía de tu dispositivo, por lo que aprender sobre cómo administrar aplicaciones que consumen batería en Android es un paso práctico para los usuarios frecuentes.
Inicio Rápido y Caso de Uso
Para empezar, descarga Live Transcribe de Google Play Store o encuéntralo preinstalado en dispositivos Pixel. Abre la aplicación, otorga permisos de micrófono y comenzará inmediatamente a transcribir el sonido ambiental. Esto es perfecto para estudiantes en conferencias, profesionales en reuniones improvisadas o cualquier persona que necesite comprender el diálogo hablado en un entorno ruidoso. Es una ayuda de accesibilidad excepcional, no una herramienta para la transcripción de postproducción.
| Análisis de Características | Detalles |
|---|---|
| Función Principal | Subtítulos en vivo para conversaciones en persona |
| Accesibilidad | Gratuito en la mayoría de los dispositivos Android modernos |
| Características Clave | Más de 70 idiomas, etiquetas de eventos de sonido, modo en el dispositivo |
| Limitaciones | Solo Android, sin cargas de archivos para transcripción |
En última instancia, Live Transcribe sobresale en la eliminación de barreras de comunicación en tiempo real, ofreciendo una solución simple pero potente directamente en el dispositivo que llevas todos los días.
Sitio Web: https://www.android.com/accessibility/live-transcribe/
12. Deepgram
Para desarrolladores y startups que buscan integrar capacidades de transcripción potentes en sus propias aplicaciones, Deepgram ofrece un enfoque de API primero altamente sofisticado. A diferencia de las herramientas para usuarios finales, Deepgram es un motor diseñado para crear soluciones personalizadas, que proporciona $200 en créditos gratuitos para que los nuevos usuarios exploren sus capacidades. Esta plataforma es celebrada por su velocidad, precisión y funciones avanzadas como la diarización de hablantes, el impulso de palabras clave y el formato inteligente, lo que la convierte en una opción de primer nivel para el reconocimiento automático de voz (ASR) a nivel de producción.
Lo que distingue a Deepgram es su enfoque en modelos de IA modernos, como su serie Nova, que ofrecen alta precisión en diversas calidades de audio y acentos. Si bien requiere conocimientos técnicos para implementarlo, la flexibilidad que ofrece es incomparable para aquellos que necesitan probar o escalar servicios de transcripción. Funciona como una potente pieza de infraestructura en lugar de una simple herramienta gratuita de voz a texto lista para usar.
Inicio Rápido y Caso de Uso
Para comenzar, los desarrolladores pueden registrarse para obtener una clave API gratuita y utilizar la documentación proporcionada para enviar archivos de audio pregrabados o establecer una conexión de transmisión en tiempo real. Es una solución ideal para empresas que crean asistentes habilitados por voz, empresas de medios que automatizan la generación de subtítulos o centros de llamadas que necesitan analizar datos de conversaciones. Los créditos gratuitos permiten pruebas extensas antes de comprometerse con un plan de pago.
| Análisis de Características | Detalles |
|---|---|
| Función Principal | API para transcripción pregrabada y en tiempo real |
| Accesibilidad | Gratuito para empezar con $200 en créditos; pago por uso |
| Características Clave | Diarización de hablantes, impulso de palabras clave, elección de modelo |
| Limitaciones | Requiere conocimientos de codificación; no es una herramienta para usuarios finales |
En última instancia, Deepgram es la opción para usuarios técnicos que necesitan un motor de transcripción rápido, preciso y escalable para potenciar su propio software y productos.
Sitio Web: https://deepgram.com
Comparación de 12 Herramientas de Voz a Texto
| Producto | Características principales ✨ | Precisión y Experiencia de Usuario ★ | Precio / Valor 💰 | Audiencia objetivo 👥 |
|---|---|---|---|---|
| Transcript.LOL 🏆 | Base Whisper; cargas de 10 horas; etiquetado de hablantes; resúmenes, exportaciones, integraciones ✨ | ★4.8 (~99.8%); editor y búsqueda rápidos | 💰 Nivel gratuito; Ilimitado $120/año; Equipo $240/año — alto valor | 👥 Podcasters, profesionales del marketing, educadores, equipos legales |
| Google Docs – Dictado por Voz | Dictado en navegador; comandos de voz básicos ✨ | ★3–4; mejor para dictado claro de un solo hablante | 💰 Gratuito con cuenta de Google | 👥 Estudiantes, escritores, uso casual |
| Microsoft Windows 11 – Acceso por Voz | Dictado en el dispositivo y control del sistema; soporte sin conexión ✨ | ★3–4; fuerte para accesibilidad; necesita campo de texto | 💰 Incluido con Windows 11 | 👥 Usuarios de accesibilidad; preferentes sin conexión |
| Otter.ai | Transcripción de reuniones en vivo; ID de hablante; notas buscables; resúmenes ✨ | ★4; buena experiencia de usuario en reuniones; multihablante depende del audio | 💰 Freemium; niveles de pago para mayor volumen | 👥 Equipos, tomadores de notas de reuniones |
| Descript | Edición de audio/video basada en texto; eliminación de palabras de relleno; herramientas multipista ✨ | ★4; excelente flujo de trabajo de edición + transcripción | 💰 Planes de pago (sin plan gratuito permanente) — enfocado en creadores | 👥 Podcasters, creadores, editores |
| OpenAI Whisper (código abierto) | ASR multilingüe; traducción; CLI/biblioteca Python ✨ | ★4; fuerte precisión pero necesita configuración y control de calidad | 💰 Código gratuito; se aplican costos de cómputo | 👥 Desarrolladores, investigadores, usuarios conscientes de la privacidad |
| whisper.cpp | Puerto Whisper optimizado para CPU; modelos Apple Silicon y cuantificados ✨ | ★4; inferencia rápida de CPU local (CLI) | 💰 Gratuito; costos de recursos y almacenamiento local | 👥 Desarrolladores, usuarios sin conexión/Apple Silicon |
| Vosk (código abierto) | Modelos sin conexión pequeños; multilingüe; muchos enlaces de idiomas ✨ | ★3–4; ligero, la precisión varía según el modelo | 💰 Gratuito; licencia Apache-2.0 | 👥 Aplicaciones integradas, entornos de bajos recursos |
| Amazon Transcribe (AWS) | Por lotes y en streaming; redacción de PII; vocabularios personalizados ✨ | ★4; servicio empresarial escalable | 💰 Pago por minuto; nivel gratuito limitado de 12 meses | 👥 Desarrolladores, empresas en AWS |
| Google Cloud Speech‑to‑Text | En tiempo real y por lotes; diarización; impulso de palabras clave; multicanal ✨ | ★4–5; fuerte precisión y soporte de idiomas | 💰 Pago por uso; minutos gratuitos limitados | 👥 Empresas, clientes de GCP, desarrolladores |
| Transcripción en Vivo (Android) | Subtítulos en tiempo real; etiquetas de sonido; privacidad en el dispositivo ✨ | ★4; confiable para conversaciones cara a cara | 💰 Gratuito | 👥 Sordos/con problemas de audición, usuarios cotidianos |
| Deepgram | API de streaming y pregrabada; diarización; impulso de palabras clave ✨ | ★4; API de alto rendimiento para uso en producción | 💰 Crédito gratuito de $200; precios de pago por minuto | 👥 Startups, desarrolladores, equipos de producción |
Tomando la Decisión Correcta: Nuestras Recomendaciones Finales
🎯 Adapta la herramienta a tu tipo de audio
Dictado en vivo, reuniones, podcasts o archivos pregrabados: cada herramienta está optimizada para escenarios de audio específicos. Elige según cómo y cuándo se crea tu audio.
🔍 Equilibra la precisión con el esfuerzo
La alta precisión a veces requiere configuración o edición. Decide si prefieres comodidad instantánea o resultados de calidad profesional con una revisión menor.
🔐 Decide cuánta privacidad te importa
Las herramientas en la nube son convenientes, pero las plataformas sin conexión o que no requieren entrenamiento son más seguras para reuniones sensibles, investigaciones o conversaciones con clientes.
💸 Piensa más allá del nivel gratuito
Los planes gratuitos son excelentes para probar, pero el uso a largo plazo puede requerir actualizaciones. Comprende los límites de minutos, exportaciones y funciones antes de escalar.
Navegar por el panorama del software gratuito de voz a texto puede resultar abrumador, pero como hemos explorado, la herramienta adecuada rara vez es una solución única para todos. Tu elección ideal depende directamente de tus necesidades específicas, desde el tipo de audio que estás transcribiendo hasta tus prioridades en cuanto a privacidad, integración del flujo de trabajo y acceso sin conexión. El viaje de la palabra hablada al texto escrito es ahora más accesible que nunca, impulsado por una diversa gama de herramientas potentes y a menudo gratuitas.
La voz a texto ya no es solo transcripción
Las herramientas modernas ahora se extienden más allá de la transcripción a la resumen, la creación de contenido y la colaboración. Elegir la plataforma adecuada hoy puede proteger tu flujo de trabajo para el futuro a medida que las capacidades de IA continúan expandiéndose.
A lo largo de esta guía, hemos analizado desde herramientas sencillas integradas en el sistema operativo hasta modelos sofisticados de código abierto y potentes API basadas en la nube. La conclusión clave es que el "mejor" software gratuito de voz a texto es aquel que se alinea perfectamente con tu flujo de trabajo, no el que tiene la lista de funciones más larga.
Conclusiones Clave para Seleccionar tu Herramienta
Para destilar nuestros hallazgos, revisemos los factores centrales de toma de decisiones. Tu elección final probablemente será un compromiso entre conveniencia, precisión, costo y control.
- Para Uso Inmediato y Diario: Si tus necesidades son sencillas, como redactar correos electrónicos, tomar notas rápidas o crear documentos básicos, las soluciones integradas son inmejorables. La Escritura por voz de Google Docs y el Acceso por voz de Windows ofrecen una conveniencia increíble sin configuración, lo que las hace perfectas para tareas espontáneas.
- Para Flujos de Trabajo Colaborativos y Automatizados: Los equipos y profesionales que necesitan notas de reuniones automatizadas, identificación de hablantes y colaboración basada en la nube encontrarán un valor inmenso en servicios como Otter.ai y Descript. Sus niveles gratuitos ofrecen un punto de partida generoso para optimizar flujos de trabajo de transcripción complejos.
- Para Máxima Privacidad y Control: Cuando la privacidad de los datos es innegociable o necesitas procesar información confidencial, los modelos de código abierto sin conexión son el estándar de oro. OpenAI Whisper y su eficiente contraparte, whisper.cpp, proporcionan precisión de vanguardia al tiempo que garantizan que tus datos nunca abandonen tu máquina local.
- Para Necesidades Especializadas y de Alto Volumen: Los desarrolladores y las empresas que requieren transcripción escalable y de alta precisión para aplicaciones deben recurrir a las potentes API ofrecidas por Google Cloud Speech-to-Text, Amazon Transcribe y Deepgram. Sus niveles gratuitos están diseñados para permitirte construir y probar antes de comprometerte con un plan de pago.
Próximos Pasos Accionables para la Implementación
Ahora que tienes una imagen más clara de las opciones disponibles, es hora de tomar medidas. No te quedes atascado en la parálisis por análisis; la mejor manera de encontrar la opción adecuada es empezar a experimentar.
- Identifica tu Caso de Uso Principal: ¿Eres un podcaster que necesita transcripciones de episodios, un estudiante que graba conferencias o un desarrollador que crea una aplicación con voz? Define primero tu requisito más importante.
- Prueba tus Dos Candidatos Principales: Basándote en tu necesidad principal, selecciona dos herramientas de nuestra lista que parezcan más prometedoras. Por ejemplo, si eres un creador de video, podrías comparar el nivel gratuito de Descript con una instalación local de Whisper.
- Realiza una Prueba en el Mundo Real: Utiliza un archivo de audio corto y representativo (5-10 minutos) y procésalo con ambas herramientas. Compara los resultados basándote en la precisión, el formato, la velocidad y la experiencia general del usuario. ¿Una herramienta manejó mejor la jerga o a varios hablantes? ¿El proceso de edición fue más fácil en una que en otra?
- Evalúa el Impacto en el Flujo de Trabajo: Considera cómo cada herramienta encaja en tu proceso existente. ¿Requiere pasos adicionales o te ahorra tiempo? El mejor software gratuito de voz a texto no solo produce una gran transcripción, sino que también hace que todo tu flujo de trabajo sea más eficiente.
En última instancia, el poder de la tecnología moderna de voz a texto radica en su capacidad para desbloquear el valor atrapado en tu contenido de audio y video. Al transformar las palabras habladas en texto buscable, editable y compartible, abres nuevas posibilidades para la creación de contenido, la accesibilidad, la investigación y la productividad. La herramienta perfecta está esperando ser integrada en tu flujo de trabajo, lista para ahorrarte tiempo y esfuerzo.
¿Listo para experimentar una herramienta de transcripción que prioriza la privacidad, la precisión y un flujo de trabajo bellamente simple? Si bien muchas herramientas gratuitas vienen con limitaciones de privacidad o funciones, Transcript.LOL está diseñado para profesionales que necesitan transcripciones fiables y seguras sin la complejidad. Dale a tu audio la transcripción privada y de alta calidad que se merece probando Transcript.LOL hoy mismo.