Spracherkennung für Videos: Schnelle, genaue Transkripte
Entdecken Sie, wie Spracherkennung für Videos die Zugänglichkeit verbessert, Zeit spart und die Reichweite mit praktischen Schritten für Ersteller erweitert.
Praveen
October 30, 2024
Haben Sie jemals versucht, ein bestimmtes Zitat irgendwo in einem zweistündigen Webinar zu finden? Es ist ein Albtraum. Speech-to-Text für Videos löst dieses Problem vollständig, indem jedes gesprochene Wort in ein durchsuchbares, nutzbares Transkript umgewandelt wird. Es ist, als würde man seiner gesamten Videobibliothek eine eigene leistungsstarke Suchmaschine geben.
Verwandeln Sie Ihre Video-Dialoge in durchsuchbare Inhalte

Ohne ein Transkript bleiben alle wertvollen Informationen, die in Ihren Videos gesprochen werden, verschlossen. Stellen Sie es sich wie eine Bibliothek voller ungeschriebener Bücher vor – das Wissen ist da, aber viel Glück beim Finden eines bestimmten Satzes. Diese Technologie dreht dieses Skript komplett um und verwandelt Dialoge in Daten, die Sie tatsächlich nutzen können.
Diese einfache Umstellung macht Ihre Inhalte auffindbarer, zugänglicher und wertvoller. Sie spart unzählige Stunden für Content-Ersteller, Forscher und Marketingteams, die nicht mehr stundenlang manuell durch Aufnahmen wühlen müssen, nur um einen kleinen Clip zu finden.
Wichtige KI-gestützte Funktionen für intelligentere Video-Transkription
Modernste KI
Angetrieben von OpenAIs Whisper für branchenführende Genauigkeit. Unterstützung für benutzerdefinierte Vokabulare, bis zu 10 Stunden lange Dateien und ultraschnelle Ergebnisse.

Aus mehreren Quellen importieren
Importiere Audio- und Videodateien aus verschiedenen Quellen, einschließlich direktem Upload, Google Drive, Dropbox, URLs, Zoom und mehr.
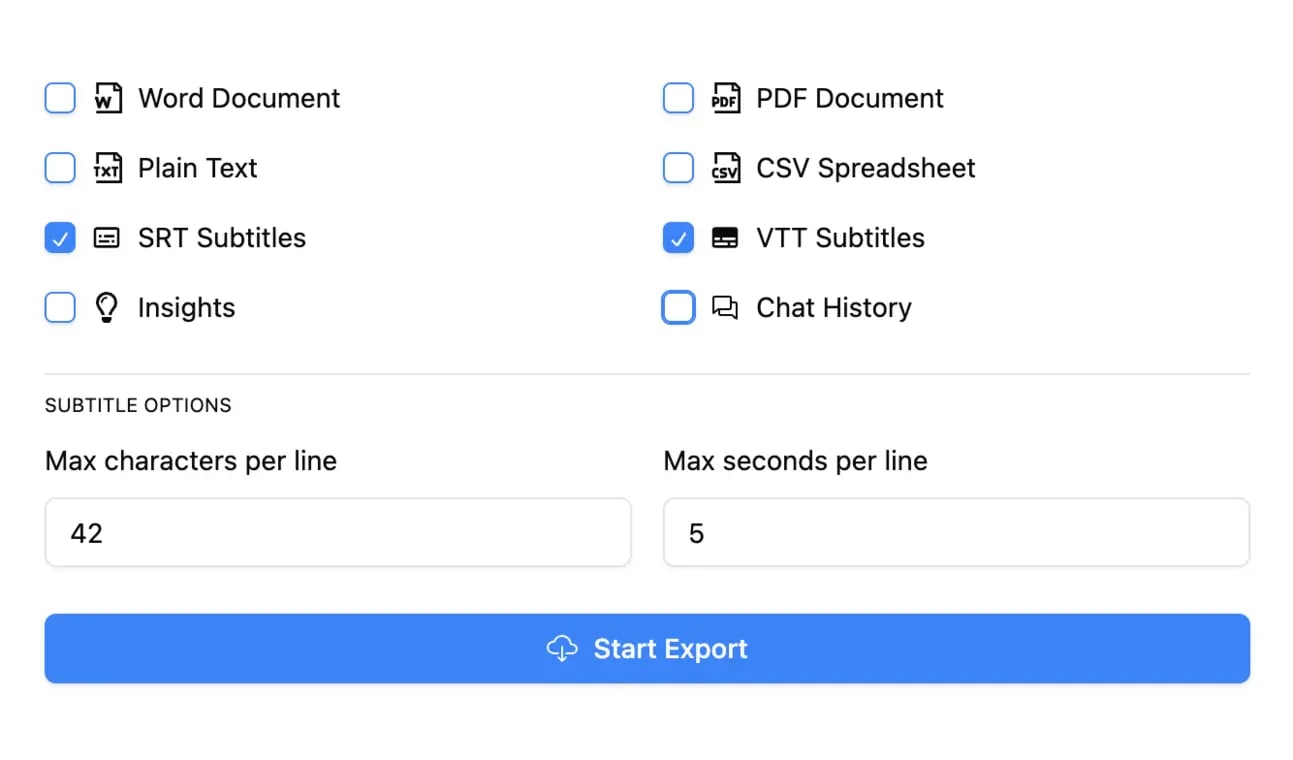
In mehreren Formaten exportieren
Exportiere deine Transkripte in mehreren Formaten, einschließlich TXT, DOCX, PDF, SRT und VTT mit anpassbaren Formatierungsoptionen.
Die wachsende Nachfrage nach transkribierten Videos
Der Bedarf an automatisierter Transkription explodiert. Der globale Markt für Spracherkennungs-APIs, der die treibende Kraft hinter dieser Technologie ist, wurde 2024 auf rund 5 Milliarden US-Dollar geschätzt und wird voraussichtlich bis 2034 21 Milliarden US-Dollar erreichen.
Dieses Wachstum ist kein zufälliger Anstieg; es zeigt einen klaren Wandel in der Art und Weise, wie wir mit Videos umgehen. Anstatt Videos als Blackbox zu behandeln, erschließen moderne Tools ihr volles Potenzial. Indem Sie Ihre Videoinhalte in Text umwandeln, schaffen Sie eine Grundlage für alle Arten neuer Content-Strategien. Wenn Sie tiefer eintauchen möchten, lesen Sie unseren Leitfaden zu den Vorteilen der Umwandlung von Videos in Text.
Videoinhalte wachsen schneller als textbasierte Inhalte, und Unternehmen verlagern sich hin zu durchsuchbaren, strukturierten Videodaten. Spracherkennungstechnologie stellt sicher, dass Sie niemals wertvolle Einblicke verlieren, die in Aufzeichnungen verborgen sind. Sie verbessert auch die Effizienz des Teams, indem sie unstrukturierte Audiodaten in umsetzbare, lesbare Informationen umwandelt.
Wichtigste Erkenntnis: Die Umwandlung von Sprache in Text für Videos dient nicht nur der Erstellung von Untertiteln, sondern auch dazu, Ihre gesamte Videobibliothek so durchsuchbar und nützlich wie ein Textdokument zu machen.
Was bedeutet das also für Sie in der Praxis? Hier ist eine kurze Zusammenfassung der unmittelbaren Vorteile, die Sie durch die Umwandlung der gesprochenen Worte Ihres Videos in Text erzielen.
| Vorteil | Auswirkung auf Ihre Inhalte |
|---|---|
| Verbesserte SEO | Suchmaschinen können keine Videos ansehen, aber sie können Text crawlen. Ein Transkript macht Ihr Video indexierbar und hilft ihm, für relevante Schlüsselwörter zu ranken. |
| Verbesserte Zugänglichkeit | Transkripte und Untertitel machen Ihre Inhalte für gehörlose oder schwerhörige Menschen zugänglich und stellen sicher, dass Sie Standards wie den ADA erfüllen. |
| Mühelose Wiederverwendung von Inhalten | Ein einzelnes Video-Transkript kann mit minimalem Aufwand in Blogbeiträge, Social-Media-Schnipsel, E-Mail-Newsletter und Show Notes umgewandelt werden. |
| Bessere Nutzerbindung | Untertitel und durchsuchbare Transkripte halten die Zuschauer bei der Stange, insbesondere diejenigen, die Videos ohne Ton ansehen (und das sind viele!). |
Dieser Prozess eröffnet zahlreiche enorme Vorteile für jeden, der mit Videos arbeitet. Eine der häufigsten und wirkungsvollsten Anwendungen ist die Verbesserung der Zugänglichkeit und des Engagements Ihrer Inhalte. Um das Beste aus Ihren Dialogen herauszuholen, lohnt es sich, die besten Apps zur Erstellung von Videountertiteln zu erkunden.
Wie KI Ihre Videos wirklich zu verstehen lernt

Die Technologie hinter Sprache-zu-Text für Videos ist keine Magie – es ist ein hochentwickelter Lernprozess, der stark dem Erlernen einer Sprache ähnelt. Denken Sie daran, einem Kind das Lesen beizubringen. Es beginnt mit einzelnen Lauten (Buchstaben), baut sich zu ganzen Wörtern auf und schließlich versteht es ganze Sätze, weil es den Kontext erfasst.
KI folgt einem überraschend ähnlichen Weg. Der gesamte Vorgang wird durch eine Technologie namens Automatische Spracherkennung (ASR) angetrieben. Die erste Aufgabe des ASR-Systems besteht darin, den Ton Ihres Videos abzuhören und ihn in die kleinstmöglichen Lauteinheiten, die sogenannten Phoneme, zu zerlegen. Es lernt im Grunde, den Unterschied zwischen dem "c" in "cat" und dem "ch" in "chat" zu erkennen.
Von Lauten zu Sätzen
Sobald der Ton in diese winzigen Teile zerlegt ist, beginnt das eigentliche Training der KI. Moderne Transkriptionsmodelle, wie Whispers von OpenAI, werden mit einer atemberaubenden Menge an Audiodaten gefüttert – wir sprechen von Hunderttausenden von Stunden, die aus dem Internet gesammelt wurden. Diese riesige Bibliothek lehrt die KI, diese phonetischen Laute wieder geschriebenen Wörtern zuzuordnen.
Diese Trainingsdaten sind unglaublich vielfältig und umfassen unzählige Akzente, Sprechgeschwindigkeiten und Hintergrundgeräusche. So kann die KI jemanden mit einem starken schottischen Akzent genauso gut verstehen wie jemanden, der perfektes Rundfunkenglisch spricht. Hier glänzen die heutigen Werkzeuge wirklich und gehen weit über die einfache Diktierfunktion hinaus, um die wirklichen Nuancen menschlicher Sprache zu erfassen.
Sie können sehen, wie sich all dieses Training auszahlt, indem Sie sich ansehen, wie die führende KI-gestützte Transkriptionssoftware heute eine so hohe Genauigkeit erreicht.
Kontext ist alles: Das wahre Genie der KI liegt in ihrem Gespür für den Kontext. Wenn Sie sagen: "Ich muss zur Bank gehen", verwendet das Modell die Wörter um "zur", um zu wissen, dass es nicht "zu" oder "zwo" meint.
Warum Kontext bei der Transkription wichtig ist
Verständnis der Absicht
KI-Modelle analysieren umgebende Wörter, um zu bestimmen, ob Sie „Bank“ als Gebäude oder „Bank“ als Verb meinten, und bewahren so die Bedeutung über Sätze hinweg.
Umgang mit Akzenten
Kontext hilft dem Modell, genauere Vorhersagen zu treffen, auch wenn Akzente oder Aussprachen zwischen Sprechern stark variieren.
Behebung mehrdeutiger Wörter
Wörter wie „zu“, „zwei“ und „zu“ werden automatisch korrigiert, basierend auf kontextuellen Mustern, die aus riesigen Datensätzen gelernt wurden.
Verbesserung des Satzflusses
Kontextuelles Verständnis hilft bei der Generierung natürlicher Satzzeichen und Strukturen, wodurch Transkripte leichter zu lesen und zu verwenden sind.
Die Macht riesiger Datensätze
Die schiere Menge an Trainingsdaten macht den Unterschied zwischen einer unordentlichen und einer nahezu perfekten Transkription aus. Die KI hat so viel menschliche Sprache gehört, dass sie unglaublich intelligente Vermutungen anstellen kann, selbst wenn die Audioqualität nicht ideal ist.
Sie lernt, ein Husten zu ignorieren, ein entferntes Martinshorn herauszufiltern und sogar Fachjargon, den sie schon einmal gehört hat, korrekt zu identifizieren. Dieser gesamte Prozess ist ein fantastisches Beispiel für intelligente Automatisierung, bei der eine wirklich komplexe Aufgabe mit unglaublicher Geschwindigkeit und Präzision erledigt wird.
Die Reise Ihres Videos vom Upload zum Transkript
Haben Sie sich jemals gefragt, was eigentlich passiert, nachdem Sie auf "Upload" für eine Videodatei geklickt haben? Es ist nicht nur ein einziger magischer Schritt – es ist eher wie eine mehrstufige Montagelinie, die Ihr Rohmaterial in ein poliertes, nutzbares Transkript verwandelt.
Lassen Sie uns den gesamten Prozess Schritt für Schritt durchgehen. Stellen Sie sich vor, wir verfolgen ein Kunden-Testimonial-Video von dem Moment, an dem Sie es hochladen, bis zum endgültigen, perfekt formatierten Export.
Erste Verarbeitung und Audioextraktion
Die Reise beginnt in dem Moment, in dem Sie Ihre Datei übergeben. Egal, ob Sie sie direkt per Drag & Drop ziehen oder von einem Cloud-Laufwerk verlinken, die erste Aufgabe des Systems ist die Triage.
Es beginnt sofort damit, die Audiospur aus dem Video zu isolieren. Stellen Sie es sich wie einen Koch vor, der Eigelb von Eiweiß trennt; die KI benötigt nur das Audio, um ihre Arbeit zu tun. Dieses Audio wird dann standardisiert und in kleinere, besser handhabbare Abschnitte unterteilt, um es für das Hauptereignis vorzubereiten.
Der KI-Transkriptionskern
Mit dem vorbereiteten und einsatzbereiten Audio wird es an die zentrale ASR (Automatic Speech Recognition)-Engine gesendet. Hier findet die eigentliche Schwerstarbeit statt.
Die KI "hört" sich die Audioabschnitte an und gleicht die phonetischen Laute schnell mit Wörtern ab, die sie aus ihrer riesigen Trainingsbibliothek erkennt. Sie gibt eine rohe, unformatierte Textdatei aus – den ersten Entwurf. Diese anfängliche Ausgabe ist oft überraschend genau, aber es fehlen noch wichtige Details wie Sprecherbeschriftungen und perfekte Satzzeichen. Hier kommen die nächsten Schritte ins Spiel.

Sprechererkennung
Identifiziere automatisch verschiedene Sprecher in deinen Aufnahmen und beschrifte sie mit ihren Namen.
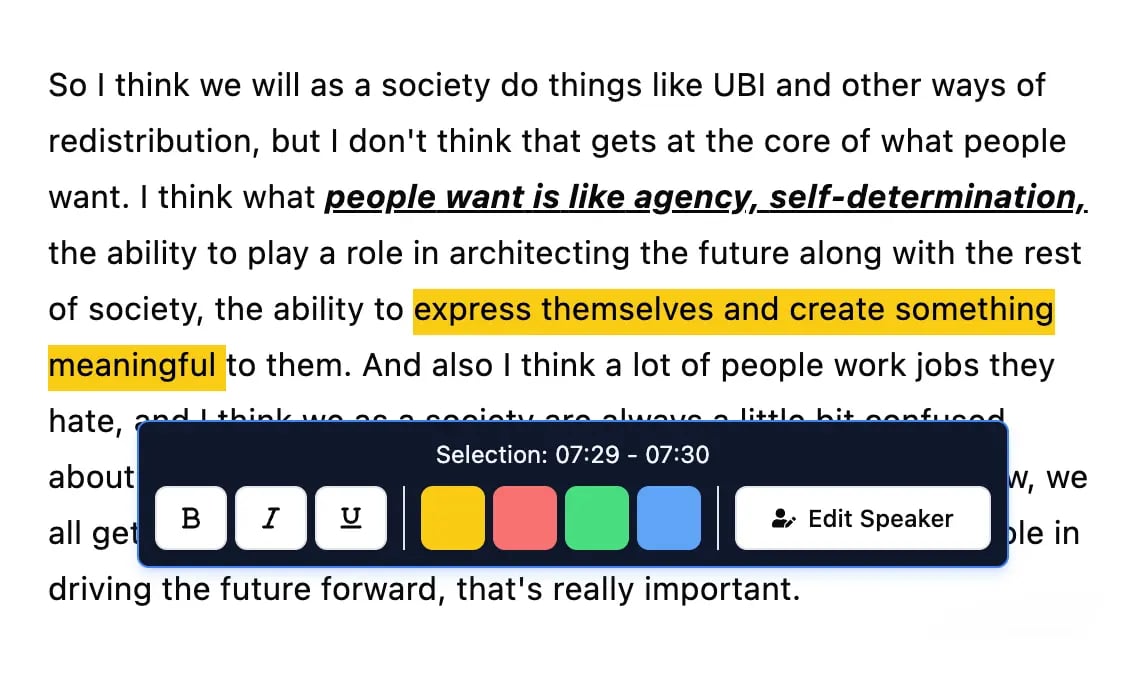
Bearbeitungswerkzeuge
Bearbeite Transkripte mit leistungsstarken Werkzeugen wie Suchen und Ersetzen, Sprecherzuordnung, Rich-Text-Formate und Hervorhebungen.
Zusammenfassungen und Chatbot
Erstelle Zusammenfassungen und andere Erkenntnisse aus deinem Transkript, wiederverwendbare benutzerdefinierte Prompts und Chatbot für deine Inhalte.
Die Nachfrage nach dieser Technologie explodiert. Der Markt für KI-Transkriptionen wird voraussichtlich bis 2034 19,2 Milliarden US-Dollar erreichen, was zeigt, wie unverzichtbar diese Werkzeuge geworden sind, um Videoinhalte zugänglich und durchsuchbar zu machen. Mehr zu diesem Trend erfahren Sie bei Sonix.ai.
Intelligente Sprechererkennung und -kennzeichnung
Bei Videos mit mehr als einer Person – wie Interviews, Podcasts oder Podiumsdiskussionen – ist es unerlässlich zu wissen, wer was gesagt hat. Hier kommt eine clevere Technologie namens Sprecher-Diarisierung ins Spiel.
Die KI analysiert die einzigartigen Stimmabdrücke im Audio – Tonhöhe, Klangfarbe und Rhythmus –, um herauszufinden, wer spricht. Anschließend weist sie den richtigen Dialogzeilen automatisch generische Bezeichnungen wie "Sprecher 1" und "Sprecher 2" zu. In einem Tool wie Transcript.LOL können Sie diese Bezeichnungen dann einfach in die tatsächlichen Namen der Teilnehmer umbenennen und so einen verwirrenden Textblock in ein sauberes, professionell aussehendes Skript verwandeln.
Profi-Tipp: Je klarer Ihr Audio ist, desto besser ist die Sprechererkennung. Wenn möglich, geben Sie jeder Person ein eigenes Mikrofon. Das macht einen riesigen Unterschied bei der Genauigkeit.
Die interaktive Bearbeitungsphase
Seien wir ehrlich: Keine KI ist perfekt. Sie kann einen einzigartigen Firmennamen falsch verstehen, über einen starken Akzent stolpern oder Fachbegriffe falsch wiedergeben. Deshalb ist die Bearbeitungsphase so wichtig – sie gibt Ihnen die Kontrolle zurück.
Ein guter interaktiver Editor ermöglicht es Ihnen, auf jedes Wort in der Transkription zu klicken und sofort zu diesem genauen Zeitpunkt im Video zu springen. Das macht die Korrektur von Fehlern zum Kinderspiel. Sie können Namen korrigieren, Satzzeichen anpassen und Fachbegriffe in Sekunden statt Stunden verbessern. Außerdem ist die korrekte Zeitstempelung entscheidend für perfekt synchronisierte Untertitel. In unserem Leitfaden vertiefen wir die Bedeutung von Transkriptionen mit Zeitstempeln.
Schließlich, wenn Ihre Transkription poliert und perfektioniert ist, sind Sie bereit, sie zu nutzen. Sie können sie in verschiedenen Formaten exportieren, je nach Bedarf:
- Klartext (TXT): Einfach und perfekt zum Einfügen in Blogbeiträge, Artikel oder Shownotes.
- Untertitel (SRT/VTT): Die standardmäßigen, zeitgestempelten Dateien, die Sie für YouTube, Vimeo und Social-Media-Plattformen benötigen.
- Dokumente (DOCX/PDF): Ideal zum Teilen mit Ihrem Team, zur Archivierung oder zur Erstellung offizieller Aufzeichnungen.
Praktische Wege zur Maximierung der Transkriptionsgenauigkeit
Eine nahezu perfekte Transkription ist nicht nur eine Frage der Software; sie ist ein direktes Ergebnis Ihrer Audioqualität. Stellen Sie es sich wie einen Fotografen vor, der mit Licht arbeitet – je besser die Beleuchtung, desto klarer das Endergebnis. Für die Spracherkennung für Videos ist gutes Audio Ihr Licht.
Obwohl die heutigen KI-Modelle unglaublich leistungsfähig sind, sind sie keine Wunderwerke. Sie benötigen ein sauberes Signal, um ihre beste Arbeit zu leisten. Ein paar einfache Anpassungen vor der Aufnahme können die Qualität Ihrer endgültigen Transkription erheblich verbessern und Ihnen später viel Bearbeitungszeit ersparen.
Dies ist der grundlegende Weg, den Ihr Video durchläuft, um zu einer polierten Transkription zu werden.
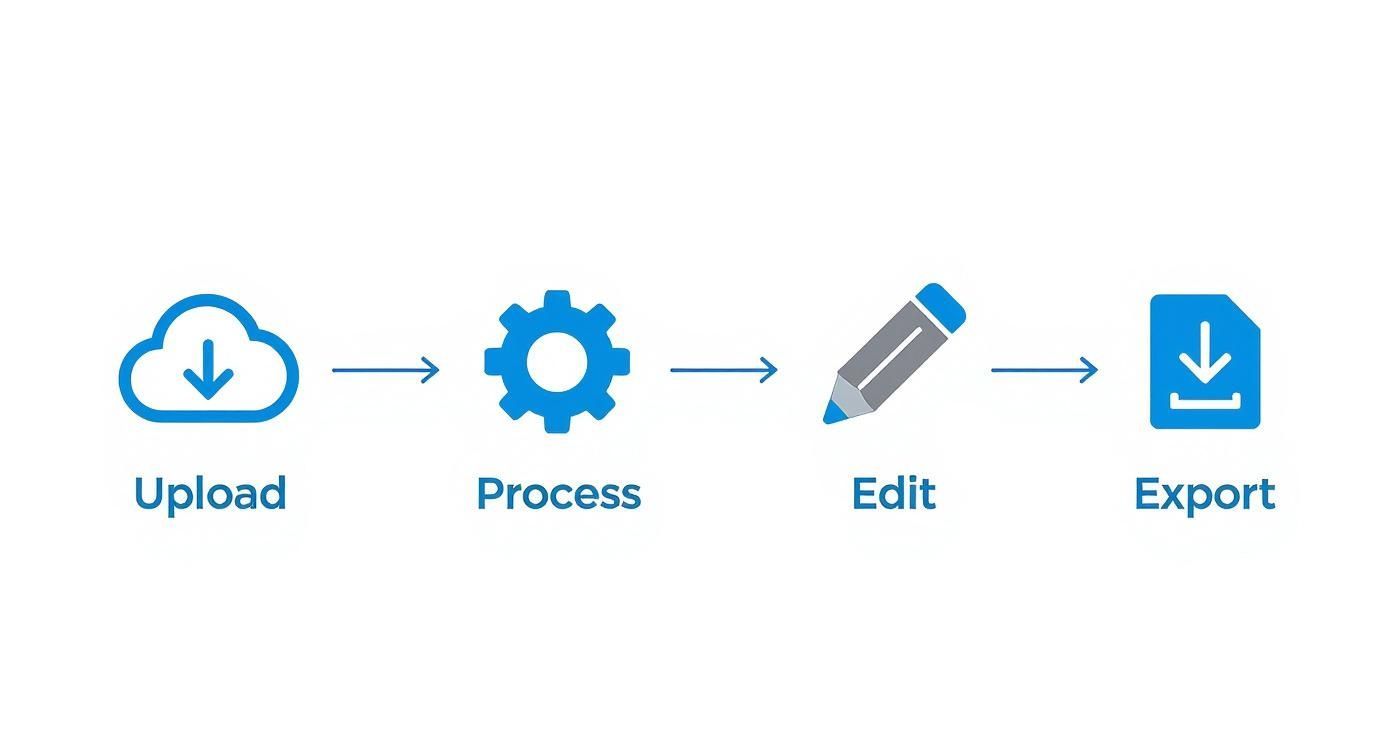
Die Erkenntnis hier ist, dass die "Verarbeitungs"-Phase nur so gut ist wie die "Upload"-Phase, die sie speist. Wenn Sie proaktiv einige Schritte unternehmen, stellen Sie sicher, dass die KI von Anfang an das bestmögliche Material zur Verfügung hat.
Kontrollieren Sie Ihre Aufnahmeumgebung
Ihre erste Priorität ist es, Hintergrundgeräusche zu eliminieren. Die brummende Klimaanlage, ein Gespräch im Nebenzimmer oder sogar das Echo in einem großen, leeren Raum können das Audio verfälschen. Wenn das passiert, muss die KI Überstunden machen, um Stimmen vom Rauschen zu trennen, und hier schleichen sich Fehler ein.
Probieren Sie diese einfachen Tipps aus, um dem entgegenzuwirken:
- Wählen Sie einen ruhigen Ort: Nehmen Sie in einem kleineren Raum mit weichen Oberflächen wie Teppichen, Vorhängen oder Möbeln auf. Diese absorbieren Schall und reduzieren das Echo.
- Schalten Sie Ablenkungen aus: Schalten Sie Ihr Telefon stumm und schalten Sie Geräte aus, die ein leises Summen erzeugen, wie Ventilatoren oder Kühlschränke.
- Achten Sie auf den Abstand: Bringen Sie das Mikrofon nahe an den Mund des Sprechers – idealerweise sechs bis zwölf Zoll entfernt. Dies liefert ein klares, starkes Signal, das leicht zu transkribieren ist.
Investieren Sie in ein ordentliches Mikrofon
Das eingebaute Mikrofon Ihres Laptops oder Ihrer Kamera ist darauf ausgelegt, Schall aus allen Richtungen aufzunehmen. Das ist großartig, um die Atmosphäre eines Raumes einzufangen, aber schlecht für die Aufnahme klarer Dialoge. Es fängt immer mehr Hintergrundgeräusche ein als ein dediziertes Mikrofon.
Sie müssen keine Unsummen ausgeben, um eine deutliche Verbesserung zu erzielen. Ein erschwingliches Ansteckmikrofon (Lavaliermikrofon) oder ein einfaches USB-Mikrofon kann die Klarheit dramatisch verbessern, indem es sich direkt auf die Stimme des Sprechers konzentriert. Diese eine Verbesserung ist oft die wirkungsvollste Änderung, die Sie vornehmen können. Mehr darüber, wie verschiedene Faktoren die Ergebnisse beeinflussen, erfahren Sie in unserem Leitfaden zur Verbesserung der Spracherkennungsgenauigkeit.
Reale Auswirkungen: Eine Transkription von einem Laptop-Mikrofon in einem lauten Café erreicht möglicherweise nur eine Genauigkeit von 70-80 %, was Ihnen eine Menge Bearbeitungsaufwand hinterlässt. Das gleiche Gespräch, aufgenommen mit einem 20-Dollar-Lavaliermikrofon, könnte leicht eine Genauigkeit von 95 % oder höher erreichen und Ihnen sofort einen nahezu perfekten Entwurf liefern.
Audioqualität ist wichtig
Schlechtes Audio – Echo, Hintergrundgeräusche, Windgeräusche, überlappende Sprecher – reduziert die Transkriptionsgenauigkeit drastisch. Selbst die besten ASR-Systeme haben Schwierigkeiten mit unklaren Eingaben. Priorisieren Sie immer sauberes, direktes Audio, um später aufwändige manuelle Korrekturen zu vermeiden.
Achten Sie auf Ihre Sprechgewohnheiten
Wie Sie sprechen, ist genauso wichtig wie Ihre Ausrüstung. Nuscheln, zu schnelles Sprechen oder sich gegenseitig ins Wort zu fallen sind häufige Ursachen für schlechte Transkripte. Die KI wird verwirrt, wenn Stimmen sich überschneiden, was es fast unmöglich macht, den Dialog korrekt zu trennen.
Ermutigen Sie die Sprecher, klar zu artikulieren und vor allem abwechselnd zu sprechen. Ein wenig Disziplin während der Aufnahmesitzung zahlt sich aus, wenn Sie das Transkript erstellen. Wenn Sie sich darauf konzentrieren, saubere Audiodaten zu erfassen, geben Sie der KI die bestmögliche Chance, ein fehlerfreies Ergebnis zu liefern.
Reale Arbeitsabläufe für Kreative und Teams
Die wahre Magie von Spracherkennung für Videos ist nicht die Technologie selbst – es ist das, was Sie damit tun können. Fachleute in jedem Bereich entwickeln intelligentere, schnellere Arbeitsweisen, indem sie gesprochene Worte in Daten umwandeln, die sie tatsächlich nutzen können. Lassen Sie uns die Theorie hinter uns lassen und sehen, wie reale Teams Transkripte nutzen, um Dinge zu erledigen.
Dies ist kein Nischen-Trend; es wird zentral für die Art und Weise, wie moderne Inhalte erstellt werden. Der globale Markt für Sprach- und Spracherkennung wurde 2024 auf 15,46 Milliarden US-Dollar bewertet und wird voraussichtlich bis 2032 unglaubliche 81,59 Milliarden US-Dollar erreichen. Diese Explosion zeigt, wie sehr wir uns auf Transkription verlassen, um Inhalte zugänglich zu machen und das Publikum zu fesseln. Sie können weitere Einblicke in diesen Markttrend und seine Treiber entdecken.
Content-Marketer skalieren die Wiederverwendung
Für jeden Content-Marketer ist ein einzelnes Video-Webinar eine Goldgrube. Aber manuell darin nach den guten Stellen zu graben, ist langwierige, schmerzhafte Arbeit. Sobald Sie ein genaues Transkript haben, ändert sich das gesamte Spiel.
Ein einstündiges Webinar kann sofort in einen SEO-freundlichen Blogbeitrag umgewandelt werden, der bereits mit schlagwortreichen Überschriften und Zitaten gefüllt ist. Marketer können dann die besten Ausschnitte auswählen und sie in Dutzende von Social-Media-Posts, E-Mail-Newsletter-Auszüge oder sogar das Skript für ein kurzes Werbevideo verwandeln. Es geht darum, den ROI jedes einzelnen Videos, das Sie erstellen, zu vervielfachen.
UX-Forscher decken schneller Erkenntnisse auf
User Experience (UX)-Forscher leben von Kundeninterviews und versuchen, diese "Aha!"-Momente zu finden, die zu besseren Produkten führen. Die größte Engstelle? Stundenlange Aufnahmen durchsuchen, nur um dieses eine spielverändernde Zitat zu finden.
Spracherkennungs-Transkripte machen diesen gesamten Prozess unglaublich effizient. Forscher können ein ganzes Interview nach Schlüsselwörtern wie "frustrierend" oder "verwirrend" durchsuchen, um Schmerzpunkte in Sekundenschnelle zu finden. Sie können aussagekräftige Kundenstimmen direkt in ihre Berichte kopieren und einfügen und ihren Erkenntnissen das Gewicht authentischer, überzeugender Beweise verleihen. Es verkürzt den Forschungszyklus und hilft Teams, Produkte auf der Grundlage dessen zu entwickeln, was die Benutzer tatsächlich sagen.
Transkriptions-Engines der neuen Generation verfügen jetzt über semantische Suchfunktionen, die es Teams ermöglichen, nicht nur nach Schlüsselwörtern, sondern auch nach Ideen und Themen innerhalb von Transkripten zu suchen. Dieses Update verbessert dramatisch, wie schnell Erkenntnisse aus langen Interviews gewonnen werden können.
Workflow-Transformation: Anstatt stundenlang Videos zu durchforsten, können Forscher in wenigen Minuten Schlüsselthemen finden. Ein Prozess, der einst Tage dauerte, kann nun an einem einzigen Nachmittag erledigt werden.
Lehrende und Trainer erstellen barrierefreie Kurse
In der Bildung und im Unternehmensschulungswesen ist Barrierefreiheit nicht nur ein nettes Extra, sondern oft eine gesetzliche Anforderung. Die Bereitstellung genauer Untertitel für Videokurse ist entscheidend für Lernende, die gehörlos oder schwerhörig sind, und hilft ehrlich gesagt jedem, indem sie die Konzentration und das Behalten verbessert.
Das Erstellen von Transkripten mit einem Tool wie Transcript.LOL ermöglicht es Pädagogen, perfekt synchronisierte SRT- oder VTT-Untertiteldateien mit fast keinem Aufwand zu erstellen. Dies stellt sicher, dass ihre Inhalte inklusiv sind und die Zugänglichkeitsstandards erfüllen. Darüber hinaus wird ein durchsuchbares Transkript zu einem leistungsstarken Lernwerkzeug, mit dem Lernende zu bestimmten Themen in einer langen Vorlesung springen können, ohne die gesamte Vorlesung erneut ansehen zu müssen.
Fragen? Wir haben Antworten.
Auch nachdem Sie den Workflow gemeistert haben, ist es normal, ein paar Fragen dazu zu haben, wie Sprache-zu-Text für Videos wirklich funktioniert. Es ist ein mächtiges Werkzeug, aber das Verständnis der Details hilft Ihnen, das Beste daraus zu machen. Hier sind einige klare Antworten auf die Fragen, die wir am häufigsten von Erstellern und Teams hören.
Diese decken die Grundlagen ab – von dem, was Sie in Bezug auf die Leistung erwarten können, bis hin zu den praktischen Unterschieden zwischen einem Transkript und einer Untertiteldatei. Das richtige Verständnis ist der Schlüssel zum Aufbau eines effizienten Video-Content-Workflows.
Wie genau ist das Zeug wirklich?
Moderne KI-Transkription kann bei hochwertigem Audio eine Genauigkeit von über 95 % erreichen. Aber "hochwertig" ist hier der Schlüsselbegriff. Das Endergebnis hängt immer davon ab, wie sauber Ihr Quellmaterial ist.
Einige Dinge können die KI aus dem Tritt bringen:
- Audioqualität: Klare, saubere Audioaufnahmen ohne Verzerrungen sind entscheidend.
- Hintergrundgeräusche: Laute Cafés, Hintergrundmusik oder sich überlagernde Stimmen können die Sache verkomplizieren.
- Starke Akzente: Obwohl heutige Modelle beeindruckend gut mit Akzenten umgehen können, können sehr starke oder einzigartige Dialekte immer noch zu einigen Schwierigkeiten führen.
- Nischen-Jargon: Branchenspezifische Begriffe oder einzigartige Produktnamen können falsch geschrieben werden, wenn die KI sie noch nicht gesehen hat.
Für einen gut aufgenommenen Podcast ist das zurückgegebene Transkript oft nahezu perfekt. Für etwas chaotischeres, wie eine Konferenzschaltung mit gleichzeitig sprechenden Personen, liefert die KI einen fantastischen ersten Entwurf, den Sie mit einem interaktiven Editor in wenigen Minuten polieren können.
Kann es erkennen, wer in einem Video spricht?
Ja, absolut. Diese Funktion ist ein absoluter Game-Changer für Interviews, Besprechungen und Podiumsdiskussionen. Der Fachbegriff dafür ist Sprecher-Diarisierung.
Fortgeschrittene Plattformen können automatisch erkennen, wenn eine neue Person zu sprechen beginnt, und sie entsprechend kennzeichnen, z. B. "Sprecher 1", "Sprecher 2" usw.
Dies ist unerlässlich für alle Inhalte mit mehr als einer Stimme, einschließlich:
- Interviews
- Podiumsdiskussionen
- Team-Meetings
- Kundensupport-Anrufe
Sobald das Transkript generiert ist, können Sie in den Editor springen und diese generischen Bezeichnungen durch die tatsächlichen Namen der Sprecher ersetzen. Das Ergebnis ist ein sauberes, perfekt formatiertes Skript, das klar und deutlich macht, wer was gesagt hat.
Was ist der Unterschied zwischen Transkripten und Untertiteln?
Das verwirrt die Leute ständig. Obwohl sie beide aus demselben Audio stammen, sind Transkripte und Untertitel für völlig unterschiedliche Aufgaben konzipiert. Sie müssen wissen, welches Sie für Ihr spezifisches Ziel verwenden müssen.
Ein Transkript ist der vollständige Text von allem Gesagten, typischerweise in einem einzigen Dokument mit Sprecherkennzeichnungen. Es ist perfekt für SEO, die Umwandlung eines Videos in einen Blogbeitrag oder die eingehende Recherche des Inhalts.
Untertitel (oder Captions) sind Textdateien, wie SRT oder VTT, die zeitcodiert sind, um auf dem Bildschirm synchron mit dem Video zu erscheinen. Ihr Hauptzweck ist die Barrierefreiheit für Zuschauer, die gehörlos, schwerhörig sind oder einfach nur ohne Ton zuschauen – was heutzutage die meisten Leute in den sozialen Medien sind.
Wesentlicher Unterschied: Denken Sie daran: Ein Transkript dient zum Lesen und Suchen des Inhalts im Nachhinein. Untertitel dienen zum Ansehen und Verstehen in Echtzeit. Jeder gute Dienst ermöglicht Ihnen den Export beider.
Wie sicher sind meine Inhalte?
Jeder seriöse Dienst stellt Datensicherheit und Datenschutz an erste Stelle. Punkt. Sie sollten verschlüsselte Verbindungen (wie SSL/TLS) für alle Datei-Uploads verwenden und Ihre Daten in sicheren Cloud-Umgebungen nach Industriestandard speichern.
Überprüfen Sie vor der Anmeldung immer eine transparente Datenschutzrichtlinie, die genau erklärt, wie Ihre Daten behandelt werden, wer sie sehen kann und wie lange sie gespeichert werden. Wenn Sie mit sensiblen geschäftlichen, rechtlichen oder persönlichen Inhalten zu tun haben, suchen Sie nach Diensten, die mit Standards wie DSGVO oder SOC 2 konform sind. Dies stellt sicher, dass sie den höchsten Sicherheitsstandards entsprechen. Ihre Inhalte sollten niemals ohne Ihre ausdrückliche Zustimmung zum Trainieren von KI-Modellen verwendet werden.
Sind Sie bereit, Ihre Videos in Sekunden in genaue, durchsuchbare und wiederverwendbare Inhalte zu verwandeln? Transcript.LOL bietet eine KI-gestützte Plattform mit Sprechererkennung, einem interaktiven Editor und mehreren Exportoptionen, um Ihren Workflow zu optimieren. Probieren Sie es noch heute kostenlos unter https://transcript.lol aus.