The 12 Best Free Speech to Text Software Options in 2026...
Discover the top 12 free speech to text software tools for 2026. Compare features, accuracy, and privacy to find the perfect solution for you.
Praveen
January 12, 2026
From Spoken Words to Digital Text: Your Ultimate Guide to Speech-to-Text Software
Manually transcribing audio and video content is a tedious, time-consuming task. Whether you're a podcaster creating show notes, a marketer repurposing video content for a blog, or a student capturing lecture details, converting spoken words into accurate text is a critical bottleneck. The right free speech to text software can eliminate this friction, saving you hours of effort and unlocking new potential for your content. This guide is designed to help you find the perfect tool for your specific needs, cutting through the noise to compare the best options available today.
Why Speech-to-Text Is a Workflow Upgrade?
Speech-to-text tools don’t just replace typing — they fundamentally improve how information is captured, reused, and distributed. Once audio becomes text, it becomes searchable, editable, and instantly reusable across blogs, emails, reports, and social media.
We've evaluated a wide range of solutions, from simple, built-in dictation tools to powerful, AI-driven transcription platforms. For each option, we provide a detailed breakdown covering key features, accuracy levels, privacy considerations, and ideal use cases. You'll find direct links and screenshots to see how each platform works, along with honest assessments of their pros and cons. We’ll explore everything from the privacy-focused accuracy of Transcript.LOL to the ubiquitous convenience of Google Docs Voice Typing and the offline power of open-source models like OpenAI's Whisper.
As we explore these solutions, it's important to recognize how these AI-powered tools contribute to the broader trend of how AI is transforming content creation for SMBs. This shift makes sophisticated transcription technology more accessible than ever, allowing creators and professionals to streamline their workflows significantly. This curated list will serve as your definitive resource, helping you select the most effective software to turn your audio into searchable, editable, and shareable text, without the high cost or manual labor.
State-of-the-art AI
Powered by OpenAI's Whisper for industry-leading accuracy. Support for custom vocabularies, up to 10 hours long files, and ultra fast results.

Import from multiple sources
Import audio and video files from various sources including direct upload, Google Drive, Dropbox, URLs, Zoom, and more.
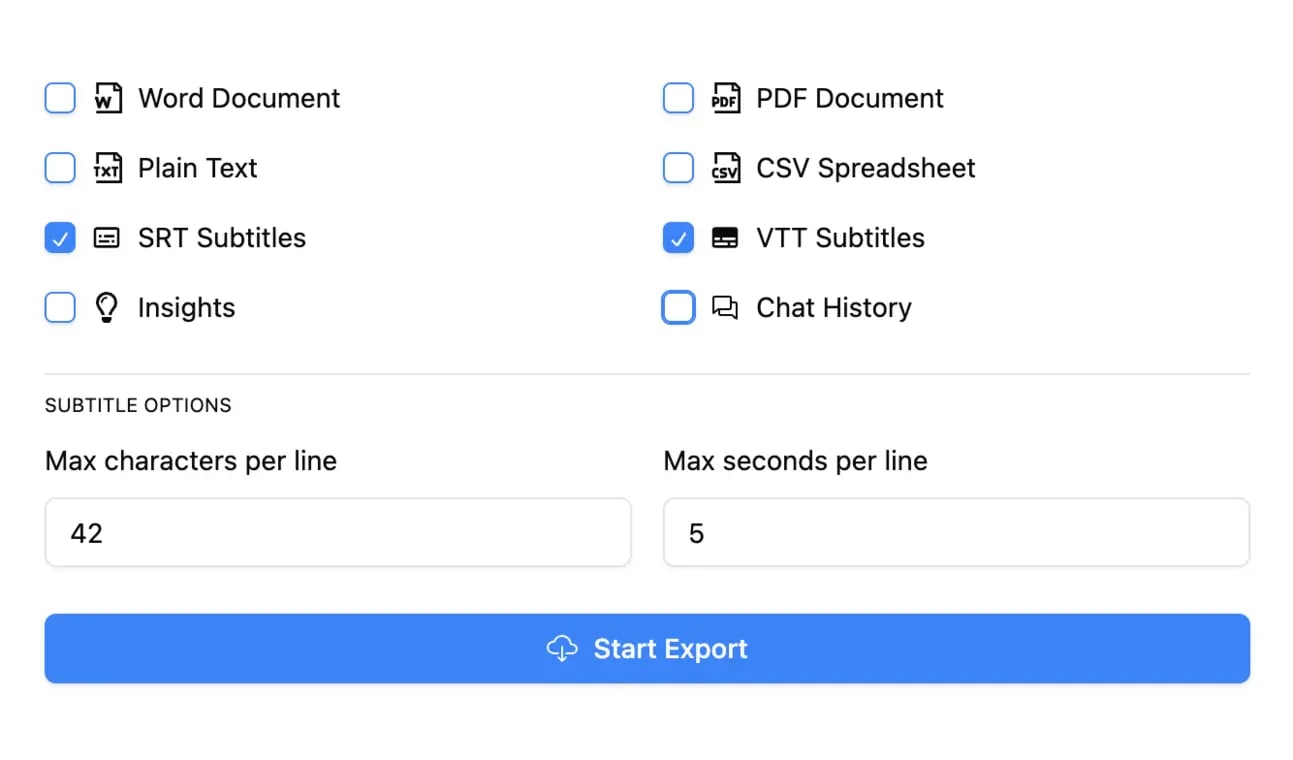
Export in multiple formats
Export your transcripts in multiple formats including TXT, DOCX, PDF, SRT, and VTT with customizable formatting options.
1. Transcript.LOL
Transcript.LOL stands as a premier choice for professionals seeking robust, AI-driven transcription that combines exceptional accuracy with powerful content creation tools. It’s more than just a speech-to-text converter; it’s an integrated workflow platform designed to turn raw audio and video into polished, ready-to-use assets in minutes, making it a top contender for the best free speech to text software available today.
Its core strength lies in leveraging a fine-tuned version of OpenAI's Whisper engine, delivering an advertised accuracy rate of ~99.8%. This precision is enhanced by custom vocabulary support, ensuring specialized terms, names, and industry jargon are captured correctly, a critical feature for users in technical, academic, or medical fields.
Key Differentiators and Use Cases
What truly sets Transcript.LOL apart is its extensive suite of post-transcription features. Beyond providing a verbatim transcript, the platform automatically generates valuable content like summaries, action items, quizzes, and even social media posts. This transforms the tool from a simple utility into a significant time-saver for marketers, educators, and content creators.

Speaker detection
Automatically identify different speakers in your recordings and label them with their names.
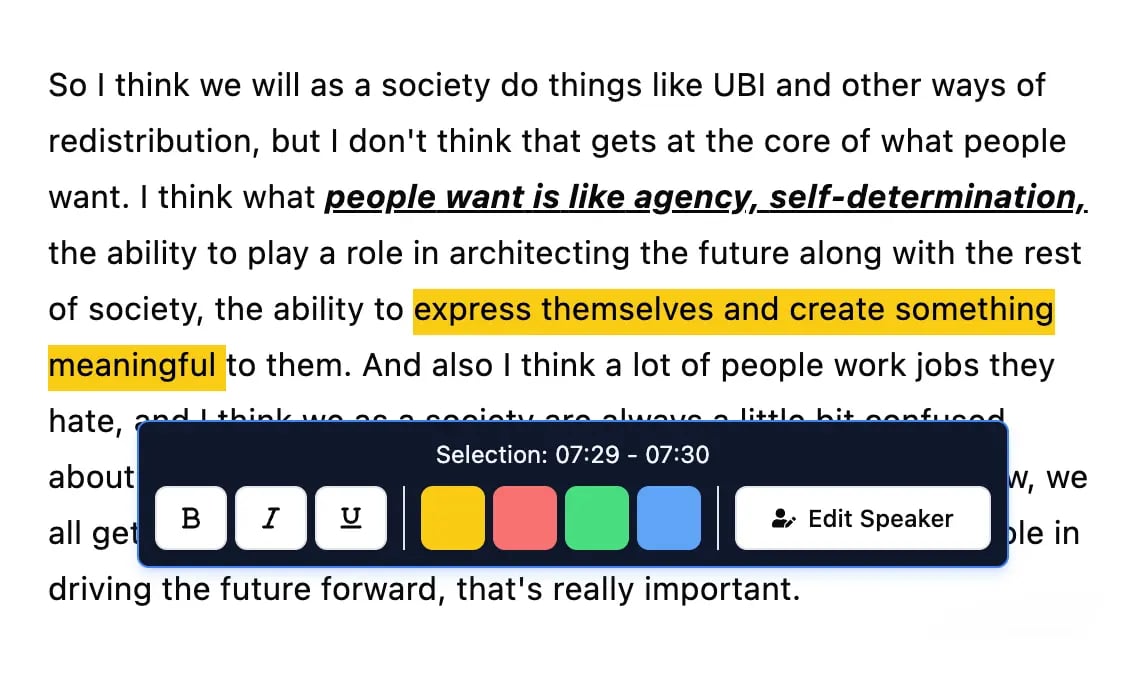
Editing tools
Edit transcripts with powerful tools including find & replace, speaker assignment, rich text formats, and highlighting.
Summaries and Chatbot
Generate summaries & other insights from your transcript, reusable custom prompts and chatbot for your content.
- For Content Creators & Marketers: Quickly turn a podcast or webinar into a blog post, show notes, and a series of social media updates. The ability to handle files up to 10 hours long makes it ideal for long-form content.
- For Teams & Businesses: The platform's shared workspaces, folder organization, and integrations (Zoom, Zapier, Google Drive) streamline collaborative review processes. Transcribing meeting recordings and generating action items becomes an automated, efficient task.
- For Researchers & Students: The high accuracy and support for various import sources (including direct URLs) make it perfect for transcribing lectures, interviews, and research audio with confidence.
Privacy-First Approach: A significant advantage is Transcript.LOL's strict no-training policy. Your data is not used to train AI models, a crucial commitment for users handling sensitive or proprietary information.
Platform Breakdown
| Feature | Details |
|---|---|
| Accuracy & Speed | Utilizes OpenAI Whisper with custom vocabulary for near-real-time, high-precision results. |
| File Handling | Accepts single uploads up to 10 hours / 5 GB. Supports various formats and direct imports from cloud services, Zoom, and URLs. |
| AI Content Tools | Generates summaries, quizzes, mind maps, blog posts, social copy, and more directly from the transcript. |
| Collaboration | Features shared workspaces, robust search, and integrations with Zapier, WhatsApp, Telegram, and major cloud storage providers. |
| Pricing | Free Tier: 2 transcripts/day (20-min max each). Unlimited Plan: $120/year for unlimited use, long uploads, and all AI features. |
| Security | Enforces a strict no-training policy on customer data and works with subprocessors to prevent data reuse. |
Getting Started
- Sign Up: Create a free account on the website.
- Upload: Drag and drop your audio/video file, or import it from Google Drive, Zoom, a URL, or other connected services.
- Transcribe: The AI processes the file, automatically detects speakers, and generates the transcript.
- Refine & Export: Use the rich-text editor to make adjustments. Then, leverage the AI tools to create summaries or other content and export in your desired format (DOCX, SRT, PDF, etc.).
For a more in-depth comparison of its features against other market options, you can explore the analysis provided in this guide to speech-to-text software.
Website: https://transcript.lol
2. Google Docs – Voice Typing
For users already embedded in the Google ecosystem, the most accessible free speech to text software is likely the one built directly into the tools they use daily. Google Docs' Voice Typing feature is a powerhouse of convenience, offering zero-install, browser-based dictation for anyone with a Google account and the Chrome browser. It excels at converting spoken words into text in real-time, making it ideal for drafting documents, taking quick notes, or overcoming writer's block.
What makes Voice Typing so effective is its simplicity and surprising accuracy for clear, single-speaker dictation. It supports a vast number of languages and even recognizes basic formatting commands like "new paragraph" or "bold that." While it lacks the advanced features of dedicated transcription services, such as speaker identification or timestamping, its strength lies in its frictionless integration into a writer's workflow.
Quick Start & Use Case
To start, simply open a Google Doc, navigate to Tools > Voice typing, and click the microphone icon. This is a perfect tool for students drafting essays, content creators outlining scripts, or professionals capturing meeting minutes as they happen. It’s a direct, live dictation tool, not a service for uploading pre-recorded audio files.
| Feature Analysis | Details |
|---|---|
| Primary Function | Live dictation directly into a document |
| Accessibility | Free with a Google account; works in Chrome |
| Key Features | Multi-language support, basic voice commands |
| Limitations | No file uploads, no speaker diarization |
Ultimately, Google's tool is the go-to for immediate, straightforward document creation without any extra software. For a deeper dive into what influences transcription outcomes, you can learn more about the factors affecting speech to text accuracy.
Website: https://docs.google.com
3. Microsoft Windows 11 – Voice Access and Voice Typing
For Windows 11 users, a powerful and privacy-conscious free speech to text software is already built directly into the operating system. Voice Access and Voice Typing in Windows 11 provide robust, on-device dictation that works system-wide, from word processors to web browsers. This integrated solution is excellent for users who prioritize offline functionality and want to keep their data local, as the speech recognition happens on the device itself.
It offers fluid dictation with automatic punctuation and supports voice commands for text editing and system navigation, such as opening applications or clicking buttons. This makes it a formidable tool for both accessibility and general productivity, allowing you to control your PC and author text without touching the keyboard. While its most advanced features are optimized for U.S. English, it provides a seamless experience without needing any installations or third-party accounts.
Quick Start & Use Case
To start Voice Typing, simply press the Windows logo key + H in any active text field. For full system control, enable Voice Access in Settings > Accessibility > Speech. This is an ideal solution for professionals drafting emails directly in Outlook, students taking notes in OneNote, or any user looking to reduce reliance on their keyboard for everyday computer tasks.
| Feature Analysis | Details |
|---|---|
| Primary Function | System-wide live dictation and PC control |
| Accessibility | Free and built into Windows 11 |
| Key Features | On-device processing, offline use, voice commands |
| Limitations | Language support varies; best in U.S. English |
Ultimately, Windows 11's native tools are the top choice for users seeking an integrated, secure, and offline-capable dictation solution that works across all their applications.
Website: https://www.microsoft.com/en-us/windows/tips/voice-access
4. Otter.ai
For those needing more than simple dictation, Otter.ai positions itself as a powerful AI meeting assistant. It stands out as a top-tier free speech to text software designed specifically for transcribing conversations, meetings, and interviews. Its main strength lies in its ability to handle multiple speakers, identifying and labeling who said what in real-time or from an audio file, making it invaluable for collaborative environments.
What makes Otter.ai particularly useful for teams is its integration with platforms like Zoom, Google Meet, and Microsoft Teams. The AI generates searchable notes, action items, and concise summaries from conversations, transforming messy discussions into organized, actionable records. The generous free tier provides a substantial amount of transcription minutes per month, though with some limitations on import length and features compared to its paid plans.
Quick Start & Use Case
To get started, sign up for a free account and connect it to your calendar to have the Otter Assistant automatically join and transcribe your virtual meetings. You can also directly record conversations or upload audio files. It's a perfect tool for project managers capturing team stand-ups, journalists conducting interviews, or students recording lectures for later review. If you're new to this process, understanding how to transcribe audio to text for free can provide a solid foundation.
| Feature Analysis | Details |
|---|---|
| Primary Function | Live meeting transcription and note-taking |
| Accessibility | Freemium model with web and mobile apps |
| Key Features | Speaker identification, AI summaries, meeting integrations |
| Limitations | Free tier has limits on import duration and monthly minutes |
Ultimately, Otter.ai is the ideal choice for anyone who needs to capture, organize, and share insights from multi-speaker conversations, bridging the gap between raw audio and structured notes.
Website: https://otter.ai
5. Descript
Descript moves beyond simple transcription, positioning itself as an all-in-one audio and video editor powered by text. For podcasters, YouTubers, and content creators, it’s a game-changing tool that merges the transcription process directly with media editing. Instead of just providing a transcript, Descript allows you to edit your video or audio by simply editing the text, making it an incredibly intuitive free speech to text software for media production.
What makes Descript unique is its transcript-based workflow. Deleting a word or sentence in the text automatically cuts it from the audio or video file, complete with seamless transitions. It also includes powerful AI features like filler word removal ("um," "uh") with a single click and an "Overdub" feature to create an AI clone of your voice for correcting mistakes. While its free tier is more of a trial with limited transcription hours, it provides a full taste of this powerful editing paradigm.
Quick Start & Use Case
To get started, sign up for a free account, create a new project, and drag-and-drop your audio or video file. Descript will automatically transcribe it, presenting you with the text-based editor. This is ideal for podcasters cleaning up interviews, marketers creating social media clips from long-form videos, or corporate teams editing webinars and training materials without needing complex video editing software.
| Feature Analysis | Details |
|---|---|
| Primary Function | Integrated, text-based audio/video editing |
| Accessibility | Free trial tier with limited hours; requires paid plan for ongoing use |
| Key Features | Filler word removal, AI audio cleanup (Studio Sound), multitrack editing |
| Limitations | No permanent free plan; can have a learning curve for advanced features |
Ultimately, Descript is the best choice for anyone whose transcription needs are directly tied to content creation and media editing, offering a workflow that no traditional transcription service can match.
Website: https://www.descript.com
6. OpenAI Whisper (open source)
For developers and users with technical expertise, OpenAI's Whisper represents the pinnacle of open-source free speech to text software. Instead of a ready-to-use web service, Whisper is a collection of powerful automatic speech recognition (ASR) models that you can run on your own hardware. This approach provides unparalleled control over privacy and eliminates ongoing per-minute transcription costs, as the only expense is the required computing power.
Whisper is renowned for its exceptional accuracy across a wide array of languages and its ability to handle challenging audio with background noise. Its real strength lies in its flexibility; it can be integrated into custom applications, used for batch processing large volumes of audio files, and even perform direct speech-to-English translation. While it demands a technical setup, the trade-off is a professional-grade transcription engine without the recurring fees of commercial services.
Quick Start & Use Case
Getting started involves installing Python and the Whisper library from its GitHub repository. From there, you can run transcriptions via the command line on your local audio files. It’s ideal for researchers analyzing large audio datasets, developers building transcription features into their apps, or podcasters who want to batch-process their entire back catalog privately and cost-effectively.
| Feature Analysis | Details |
|---|---|
| Primary Function | High-accuracy transcription of audio files |
| Accessibility | Free and open-source; requires local setup (Python, GPU) |
| Key Features | Multiple model sizes, multilingual support, translation |
| Limitations | Requires technical setup, no real-time dictation, can hallucinate |
Ultimately, Whisper is the choice for those who prioritize control, privacy, and accuracy over out-of-the-box convenience. You can discover more about how models like this fit into the broader landscape of AI-powered transcription software.
Website: https://github.com/openai/whisper
7. whisper.cpp (C/C++ port of Whisper)
For developers and privacy-conscious users seeking high-performance local transcription, whisper.cpp offers a powerful alternative to cloud-based services. This project is a C/C++ port of OpenAI's Whisper model, optimized for efficient CPU performance, including native support for Apple Silicon. As a command-line tool, it delivers a robust free speech to text software experience entirely offline, ensuring no data ever leaves your machine. It’s the ideal solution for processing sensitive audio without relying on external servers or Python dependencies.
What sets whisper.cpp apart is its sheer efficiency and portability. It runs without a heavy software stack, making it fast and resource-friendly on modern laptops and desktops. By using quantized models, it balances high accuracy with manageable file sizes and processing speeds, making it accessible even without a powerful GPU. While its command-line interface requires some technical comfort, the trade-off is unparalleled control, privacy, and performance for offline audio transcription.
Quick Start & Use Case
Getting started involves cloning the GitHub repository, compiling the code, and downloading a pre-trained Whisper model. From the terminal, you then run a simple command pointing to your audio file. This tool is perfect for journalists transcribing sensitive interviews, researchers processing field recordings without an internet connection, or developers integrating transcription capabilities directly into local applications.
| Feature Analysis | Details |
|---|---|
| Primary Function | Offline, high-performance audio file transcription |
| Accessibility | Free and open-source; requires compilation |
| Key Features | Optimized for Apple Silicon/AVX, no Python needed, model quantization |
| Limitations | Command-line only (no GUI), requires manual model download and setup |
Ultimately, whisper.cpp is the go-to for users who prioritize privacy and performance and are comfortable working within a terminal environment.
Website: https://github.com/ggml-org/whisper.cpp
8. Vosk (open source, offline)
For developers and privacy-conscious users seeking complete control over their data, Vosk stands out as a powerful, offline free speech to text software toolkit. Unlike cloud-based services, Vosk runs entirely on your local machine, from a desktop computer to a Raspberry Pi. This makes it a fantastic choice for embedding voice recognition into applications where internet connectivity is unreliable or data privacy is a primary concern.
Its key advantage lies in its lightweight, efficient models and extensive support for various programming languages. Vosk provides developers with the building blocks to create custom voice-enabled applications, from smart home assistants to in-car command systems, without sending any audio to third-party servers. It offers an exceptional degree of flexibility for projects that require offline processing.
Quick Start & Use Case
Getting started involves integrating the Vosk library into a project using a language like Python or Java. A developer would download a pre-trained language model, then use the Vosk API for real-time streaming recognition. It is ideal for creating voice control interfaces for desktop apps, transcribing audio in a secure environment, or building voice-activated features for embedded systems. Its permissive Apache 2.0 license also makes it suitable for commercial use.
| Feature Analysis | Details |
|---|---|
| Primary Function | Offline speech recognition toolkit for developers |
| Accessibility | Free and open-source (Apache 2.0 license) |
| Key Features | Lightweight offline models, supports 20+ languages, bindings for many programming languages |
| Limitations | Requires coding knowledge, accuracy can be lower than large cloud models, lacks a ready-to-use GUI |
Ultimately, Vosk is the go-to solution for developers who need an offline, customizable, and royalty-free speech recognition engine to integrate directly into their software.
Website: https://github.com/alphacep/vosk-api
9. Amazon Transcribe (AWS)
For developers and businesses needing a powerful, scalable transcription engine, Amazon Transcribe offers a robust solution within the Amazon Web Services (AWS) ecosystem. While not a simple consumer app, it provides a generous free speech to text software tier that allows for extensive testing and small-scale use. Transcribe excels at both real-time streaming and batch processing of pre-recorded audio files, making it highly versatile for technical applications like call center analytics or media content indexing.
What sets it apart is its suite of enterprise-grade features, such as automatic Personally Identifiable Information (PII) redaction, custom vocabulary building to improve accuracy for specific jargon, and speaker diarization. Its free tier, which lasts for 12 months, provides enough processing time to build and deploy a proof-of-concept. It's an API-first service, designed to be integrated into other software rather than used as a standalone tool.
Quick Start & Use Case
Getting started involves creating an AWS account and navigating to the Amazon Transcribe console. You can create a transcription job by uploading an audio file directly from your computer or an S3 bucket. This service is ideal for developers building voice-enabled applications, businesses analyzing customer service calls for quality assurance, or media companies looking to automatically generate subtitles for their video catalogs at scale.
| Feature Analysis | Details |
|---|---|
| Primary Function | API-driven batch and real-time transcription |
| Accessibility | Free tier for 12 months, then pay-as-you-go |
| Key Features | PII redaction, custom vocabularies, speaker diarization |
| Limitations | Requires AWS account; can be complex for non-developers |
Ultimately, Amazon Transcribe is the gateway for users who need industrial-strength, highly customizable speech-to-text capabilities integrated directly into their own products and workflows.
Website: https://aws.amazon.com/transcribe/
10. Google Cloud Speech‑to‑Text (API)
For developers and businesses seeking an enterprise-grade engine, Google Cloud's Speech-to-Text API represents the powerful technology that underpins many commercial applications. While not a user-facing tool, it offers a generous free tier on its v1 API, making it a viable free speech to text software option for technical users piloting a project or handling low-volume transcription tasks. It provides access to highly advanced models optimized for different audio types, including phone calls and video content.
The platform stands out for its powerful features like speaker diarization, keyword boosting, and multi-channel audio support, which are typically found in paid services. This makes it a strong choice for complex transcription needs. However, leveraging its capabilities requires a Google Cloud Platform (GCP) account, billing setup, and some technical know-how to interact with the API. The free minutes are specific to the older v1 API, and costs can accumulate once usage scales or if newer v2 models are required.
Quick Start & Use Case
Getting started involves setting up a GCP project, enabling the Speech-to-Text API, and using a client library (like Python or Node.js) to send audio files for transcription. This is ideal for developers building transcription features into their own applications, data scientists analyzing audio datasets, or businesses needing automated transcription for call center recordings. It excels at both real-time streaming and batch processing of pre-recorded files.
| Feature Analysis | Details |
|---|---|
| Primary Function | API for batch and real-time audio transcription |
| Accessibility | Free tier available; requires GCP account and billing setup |
| Key Features | Speaker diarization, keyword boosting, specialized models |
| Limitations | Technical setup required, costs can rise with scale |
Ultimately, Google Cloud's API is a solution for technical users who need a powerful, scalable, and highly accurate transcription engine for custom projects.
Website: https://cloud.google.com/speech-to-text
11. Live Transcribe (Android)
For Android users seeking an instant, accessibility-focused transcription tool, Google’s Live Transcribe stands out as a powerful piece of free speech to text software. Developed primarily for the deaf and hard-of-hearing community, this app provides real-time captions for live conversations, making it an indispensable tool for face-to-face communication. It turns your phone's microphone into a highly accurate, on-the-go transcription device.

What makes Live Transcribe unique is its focus on immediate environmental awareness. Beyond transcribing spoken words in over 70 languages, it also identifies non-speech sounds like "dog barking" or "applause," providing crucial context. While it’s designed for live interaction and doesn't support file uploads, its on-device processing option offers a layer of privacy not always found in cloud-based services. Continuous use can impact your device’s power, so learning about managing battery-draining apps on Android is a practical step for heavy users.
Quick Start & Use Case
To get started, download Live Transcribe from the Google Play Store or find it pre-installed on Pixel devices. Open the app, grant microphone permissions, and it will immediately start transcribing ambient sound. This is perfect for students in lectures, professionals in impromptu meetings, or anyone needing to understand spoken dialogue in a noisy environment. It’s an exceptional accessibility aid, not a tool for post-production transcription.
| Feature Analysis | Details |
|---|---|
| Primary Function | Live captions for in-person conversations |
| Accessibility | Free on most modern Android devices |
| Key Features | 70+ languages, sound event labels, on-device mode |
| Limitations | Android-only, no file uploads for transcription |
Ultimately, Live Transcribe excels at breaking down communication barriers in real-time, offering a simple yet powerful solution directly on the device you carry every day.
Website: https://www.android.com/accessibility/live-transcribe/
12. Deepgram
For developers and startups looking to integrate powerful transcription capabilities into their own applications, Deepgram offers a highly sophisticated, API-first approach. Unlike end-user tools, Deepgram is an engine designed for building custom solutions, providing a generous $200 in free credits for new users to explore its capabilities. This platform is celebrated for its speed, accuracy, and advanced features like speaker diarization, keyword boosting, and smart formatting, making it a top-tier choice for production-level automated speech recognition (ASR).
What sets Deepgram apart is its focus on modern AI models, such as its Nova series, which deliver high accuracy across various audio qualities and accents. While it requires technical knowledge to implement, the flexibility it offers is unparalleled for those needing to pilot or scale transcription services. It functions as a powerful piece of infrastructure rather than a simple out-of-the-box free speech to text software tool.
Quick Start & Use Case
To begin, developers can sign up for a free API key and use the provided documentation to send pre-recorded audio files or establish a real-time streaming connection. It's an ideal solution for businesses building voice-enabled assistants, media companies automating subtitle generation, or call centers needing to analyze conversational data. The free credits allow for extensive testing before committing to a paid plan.
| Feature Analysis | Details |
|---|---|
| Primary Function | API for pre-recorded and real-time transcription |
| Accessibility | Free to start with $200 in credits; pay-as-you-go |
| Key Features | Speaker diarization, keyword boosting, model choice |
| Limitations | Requires coding knowledge; not an end-user tool |
Ultimately, Deepgram is the go-to for technical users who need a fast, accurate, and scalable transcription engine to power their own software and products.
Website: https://deepgram.com
12 Speech-to-Text Tools Comparison
| Product | Core features ✨ | Accuracy & UX ★ | Price / Value 💰 | Target audience 👥 |
|---|---|---|---|---|
| Transcript.LOL 🏆 | Whisper backbone; 10‑hr uploads; speaker labeling; summaries, exports, integrations ✨ | ★4.8 (~99.8%); fast editor & search | 💰 Free tier; Unlimited $120/yr; Team $240/yr — high value | 👥 Podcasters, marketers, educators, legal teams |
| Google Docs – Voice Typing | Browser dictation; basic voice commands ✨ | ★3–4; best for clear single‑speaker dictation | 💰 Free with Google account | 👥 Students, writers, casual use |
| Microsoft Windows 11 – Voice Access | On‑device dictation & system control; offline support ✨ | ★3–4; strong for accessibility; needs text field | 💰 Included with Windows 11 | 👥 Accessibility users; offline preferers |
| Otter.ai | Live meeting transcription; speaker ID; searchable notes; summaries ✨ | ★4; good meetings UX; multi‑speaker depends on audio | 💰 Freemium; paid tiers for higher volume | 👥 Teams, meeting note takers |
| Descript | Text‑based audio/video editing; filler removal; multitrack tools ✨ | ★4; excellent editor + transcription workflow | 💰 Paid plans (no permanent free) — creator focused | 👥 Podcasters, creators, editors |
| OpenAI Whisper (open source) | Multilingual ASR; translation; Python CLI/library ✨ | ★4; strong accuracy but needs setup & QA | 💰 Free code; compute costs apply | 👥 Developers, researchers, privacy‑savvy users |
| whisper.cpp | CPU‑optimized Whisper port; Apple Silicon & quantized models ✨ | ★4; fast local CPU inference (CLI) | 💰 Free; local resource & storage costs | 👥 Developers, offline/Apple Silicon users |
| Vosk (open source) | Small offline models; multi‑lang; many language bindings ✨ | ★3–4; lightweight, accuracy varies by model | 💰 Free; Apache‑2.0 license | 👥 Embedded apps, low‑resource environments |
| Amazon Transcribe (AWS) | Batch & streaming; PII redaction; custom vocabularies ✨ | ★4; scalable enterprise service | 💰 Pay‑per‑minute; 12‑month limited free tier | 👥 Developers, enterprises on AWS |
| Google Cloud Speech‑to‑Text | Real‑time & batch; diarization; keyword boost; multi‑channel ✨ | ★4–5; strong accuracy & language support | 💰 Pay‑per‑use; limited free minutes | 👥 Enterprises, GCP customers, devs |
| Live Transcribe (Android) | Real‑time captions; sound labels; on‑device privacy ✨ | ★4; reliable for face‑to‑face conversations | 💰 Free | 👥 Deaf/hard‑of‑hearing, everyday users |
| Deepgram | Streaming & pre‑recorded API; diarization; keyword boosting ✨ | ★4; performant API for production use | 💰 $200 free credit; pay‑per‑min pricing | 👥 Startups, developers, production teams |
Making the Right Choice: Our Final Recommendations
🎯 Match the Tool to Your Audio Type
Live dictation, meetings, podcasts, or pre-recorded files — every tool is optimized for specific audio scenarios. Choose based on how and when your audio is created.
🔍 Balance Accuracy with Effort
High accuracy sometimes requires setup or editing. Decide whether you prefer instant convenience or professional-grade results with minor review.
🔐 Decide How Much Privacy Matters
Cloud tools are convenient, but offline or no-training platforms are safer for sensitive meetings, research, or client conversations.
💸 Think Beyond the Free Tier
Free plans are great for testing, but long-term use may require upgrades. Understand limits on minutes, exports, and features before scaling.
Navigating the landscape of free speech-to-text software can feel overwhelming, but as we've explored, the right tool is rarely a one-size-fits-all solution. Your ideal choice hinges directly on your specific needs, from the type of audio you're transcribing to your priorities regarding privacy, workflow integration, and offline access. The journey from spoken word to written text is now more accessible than ever, powered by a diverse array of powerful and often free tools.
Speech-to-Text Is No Longer Just Transcription
Modern tools now extend beyond transcription into summarization, content creation, and collaboration. Choosing the right platform today can future-proof your workflow as AI capabilities continue to expand.
Throughout this guide, we've dissected everything from simple, built-in operating system tools to sophisticated, open-source models and powerful cloud-based APIs. The key takeaway is that the "best" free speech-to-text software is the one that aligns seamlessly with your workflow, not the one with the longest feature list.
Key Takeaways for Selecting Your Tool
To distill our findings, let's revisit the core decision-making factors. Your final choice will likely be a trade-off between convenience, accuracy, cost, and control.
- For Instant, Everyday Use: If your needs are straightforward, like drafting emails, taking quick notes, or basic document creation, the built-in solutions are unbeatable. Google Docs Voice Typing and Windows Voice Access offer incredible convenience with zero setup, making them perfect for spontaneous tasks.
- For Collaborative and Automated Workflows: Teams and professionals who need automated meeting notes, speaker identification, and cloud-based collaboration will find immense value in services like Otter.ai and Descript. Their free tiers offer a generous starting point to streamline complex transcription workflows.
- For Maximum Privacy and Control: When data privacy is non-negotiable or you need to process sensitive information, open-source, offline models are the gold standard. OpenAI Whisper and its efficient counterpart, whisper.cpp, provide state-of-the-art accuracy while ensuring your data never leaves your local machine.
- For Specialized and High-Volume Needs: Developers and businesses requiring scalable, high-accuracy transcription for applications should look towards the powerful APIs offered by Google Cloud Speech-to-Text, Amazon Transcribe, and Deepgram. Their free tiers are designed to let you build and test before committing to a paid plan.
Actionable Next Steps for Implementation
Now that you have a clearer picture of the available options, it’s time to take action. Don't get stuck in analysis paralysis; the best way to find the right fit is to start experimenting.
- Identify Your Primary Use Case: Are you a podcaster needing episode transcripts, a student recording lectures, or a developer building a voice-enabled app? Define your single most important requirement first.
- Test Your Top Two Candidates: Based on your primary need, select two tools from our list that seem most promising. For example, if you're a video creator, you might compare Descript's free tier with a local installation of Whisper.
- Run a Real-World Test: Use a short, representative audio file (5-10 minutes) and process it with both tools. Compare the results based on accuracy, formatting, speed, and the overall user experience. Did one tool handle jargon or multiple speakers better? Was the editing process easier in one over the other?
- Evaluate the Workflow Impact: Consider how each tool fits into your existing process. Does it require extra steps, or does it save you time? The best free speech-to-text software not only produces a great transcript but also makes your entire workflow more efficient.
Ultimately, the power of modern speech-to-text technology lies in its ability to unlock the value trapped in your audio and video content. By transforming spoken words into searchable, editable, and shareable text, you open up new possibilities for content creation, accessibility, research, and productivity. The perfect tool is waiting to be integrated into your workflow, ready to save you time and effort.
Ready to experience a transcription tool that prioritizes privacy, accuracy, and a beautifully simple workflow? While many free tools come with limitations on privacy or features, Transcript.LOL is designed for professionals who need reliable, secure transcriptions without the complexity. Give your audio the high-quality, private transcription it deserves by trying Transcript.LOL today.