The 12 Best Free Speech to Text Software Options in 2026...
Discover the top 12 free speech to text software tools for 2026. Compare features, accuracy, and privacy to find the perfect solution for you.
Praveen
January 12, 2026
From Spoken Words to Digital Text: Your Ultimate Guide to Speech-to-Text Software
Manually transcribing audio and video content is a tedious, time-consuming task. Whether you're a podcaster creating show notes, a marketer repurposing video content for a blog, or a student capturing lecture details, converting spoken words into accurate text is a critical bottleneck. The right free speech to text software can eliminate this friction, saving you hours of effort and unlocking new potential for your content. This guide is designed to help you find the perfect tool for your specific needs, cutting through the noise to compare the best options available today.
Why Speech-to-Text Is a Workflow Upgrade?
Speech-to-text tools don’t just replace typing — they fundamentally improve how information is captured, reused, and distributed. Once audio becomes text, it becomes searchable, editable, and instantly reusable across blogs, emails, reports, and social media.
Abbiamo valutato una vasta gamma di soluzioni, dai semplici strumenti di dettatura integrati alle potenti piattaforme di trascrizione basate sull'intelligenza artificiale. Per ogni opzione, forniamo un'analisi dettagliata che copre le funzionalità chiave, i livelli di accuratezza, le considerazioni sulla privacy e i casi d'uso ideali. Troverai collegamenti diretti e screenshot per vedere come funziona ogni piattaforma, insieme a valutazioni oneste dei loro pro e contro. Esploreremo tutto, dall'accuratezza incentrata sulla privacy di Transcript.LOL alla convenienza onnipresente di Google Docs Voice Typing e alla potenza offline di modelli open-source come Whisper di OpenAI.
Mentre esploriamo queste soluzioni, è importante riconoscere come questi strumenti basati sull'intelligenza artificiale contribuiscano alla tendenza più ampia di come l'IA sta trasformando la creazione di contenuti per le PMI. Questo cambiamento rende la tecnologia di trascrizione sofisticata più accessibile che mai, consentendo a creatori e professionisti di semplificare significativamente i loro flussi di lavoro. Questo elenco curato servirà come tua risorsa definitiva, aiutandoti a selezionare il software più efficace per trasformare il tuo audio in testo ricercabile, modificabile e condivisibile, senza costi elevati o lavoro manuale.
IA all'avanguardia
Alimentato da Whisper di OpenAI per una precisione leader nel settore. Supporto per vocabolari personalizzati, file fino a 10 ore e risultati ultra rapidi.

Importa da più fonti
Importa file audio e video da varie fonti tra cui caricamento diretto, Google Drive, Dropbox, URL, Zoom e altro.
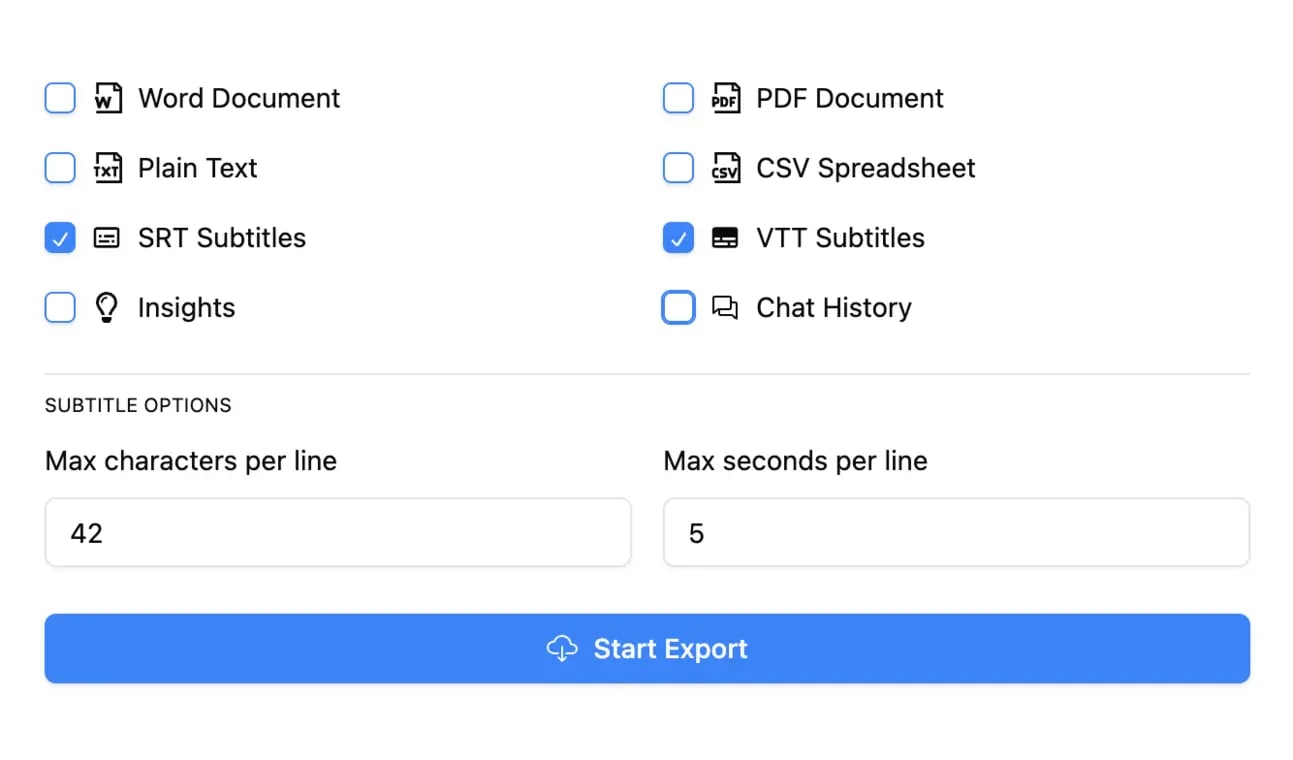
Esporta in più formati
Esporta le tue trascrizioni in più formati tra cui TXT, DOCX, PDF, SRT e VTT con opzioni di formattazione personalizzabili.
1. Transcript.LOL
Transcript.LOL si posiziona come una scelta di prim'ordine per i professionisti che cercano una trascrizione robusta e basata sull'IA, che combini un'eccezionale accuratezza con potenti strumenti di creazione di contenuti. È più di un semplice convertitore da voce a testo; è una piattaforma di flusso di lavoro integrata progettata per trasformare audio e video grezzi in risorse curate e pronte all'uso in pochi minuti, rendendolo un forte contendente per il miglior software gratuito da voce a testo disponibile oggi.
La sua forza principale risiede nell'utilizzo di una versione ottimizzata del motore Whisper di OpenAI, che offre un tasso di accuratezza pubblicizzato di circa il 99,8%. Questa precisione è migliorata dal supporto per vocabolari personalizzati, garantendo che termini specializzati, nomi e gergo di settore vengano catturati correttamente, una funzionalità fondamentale per gli utenti nei campi tecnici, accademici o medici.
Principali elementi distintivi e casi d'uso
Ciò che distingue veramente Transcript.LOL è la sua vasta suite di funzionalità post-trascrizione. Oltre a fornire una trascrizione parola per parola, la piattaforma genera automaticamente contenuti di valore come riassunti, elementi d'azione, quiz e persino post sui social media. Questo trasforma lo strumento da una semplice utilità a un significativo risparmio di tempo per marketer, educatori e creatori di contenuti.

Rilevamento dei parlanti
Identifica automaticamente diversi parlanti nelle tue registrazioni e etichettali con i loro nomi.
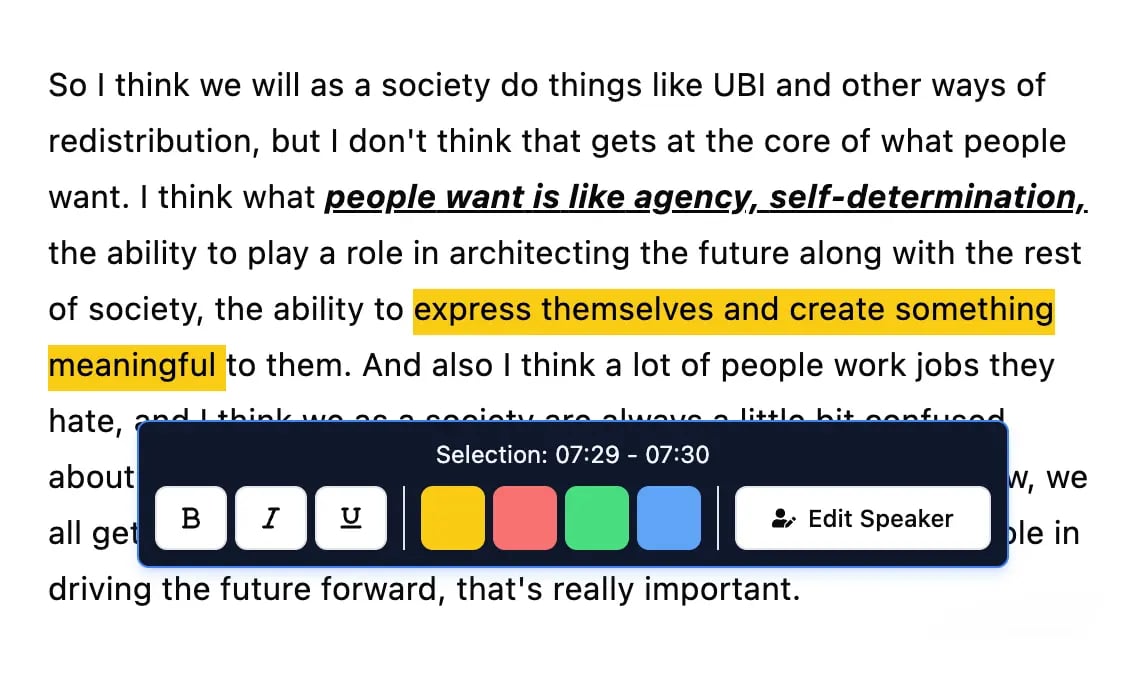
Strumenti di modifica
Modifica le trascrizioni con strumenti potenti tra cui trova e sostituisci, assegnazione dei parlanti, formati di testo arricchito ed evidenziazione.
Riassunti e Chatbot
Genera riassunti e altri approfondimenti dalla tua trascrizione, prompt personalizzati riutilizzabili e chatbot per i tuoi contenuti.
- Per i creatori di contenuti e i professionisti del marketing: Trasforma rapidamente un podcast o un webinar in un post di blog, note dello spettacolo e una serie di aggiornamenti sui social media. La capacità di gestire file fino a 10 ore lo rende ideale per contenuti di lunga durata.
- Per team e aziende: Gli spazi di lavoro condivisi della piattaforma, l'organizzazione delle cartelle e le integrazioni (Zoom, Zapier, Google Drive) semplificano i processi di revisione collaborativa. La trascrizione delle registrazioni delle riunioni e la generazione di elementi d'azione diventano un'attività automatizzata ed efficiente.
- Per ricercatori e studenti: L'elevata precisione e il supporto per varie origini di importazione (inclusi URL diretti) lo rendono perfetto per trascrivere lezioni, interviste e audio di ricerca con sicurezza.
Approccio incentrato sulla privacy: Un vantaggio significativo è la rigorosa politica di non addestramento di Transcript.LOL. I tuoi dati non vengono utilizzati per addestrare modelli di intelligenza artificiale, un impegno cruciale per gli utenti che gestiscono informazioni sensibili o proprietarie.
Panoramica della piattaforma
| Funzionalità | Dettagli |
|---|---|
| Precisione e velocità | Utilizza OpenAI Whisper con vocabolario personalizzato per risultati quasi in tempo reale e ad alta precisione. |
| Gestione dei file | Accetta caricamenti singoli fino a 10 ore / 5 GB. Supporta vari formati e importazioni dirette da servizi cloud, Zoom e URL. |
| Strumenti di contenuto AI | Genera riassunti, quiz, mappe mentali, post di blog, copie social e altro direttamente dalla trascrizione. |
| Collaborazione | Dispone di spazi di lavoro condivisi, ricerca robusta e integrazioni con Zapier, WhatsApp, Telegram e i principali provider di archiviazione cloud. |
| Prezzi | Livello gratuito: 2 trascrizioni/giorno (massimo 20 minuti ciascuna). Piano illimitato: $120/anno per uso illimitato, caricamenti lunghi e tutte le funzionalità AI. |
| Sicurezza | Applica una rigorosa politica di non addestramento sui dati dei clienti e collabora con sub-processori per prevenire il riutilizzo dei dati. |
Inizia
- Registrati: Crea un account gratuito sul sito web.
- Carica: Trascina e rilascia il tuo file audio/video, oppure importalo da Google Drive, Zoom, un URL o altri servizi connessi.
- Trascrivi: L'IA elabora il file, rileva automaticamente gli altoparlanti e genera la trascrizione.
- Affina ed esporta: Utilizza l'editor di testo ricco per apportare modifiche. Quindi, sfrutta gli strumenti AI per creare riassunti o altri contenuti ed esporta nel formato desiderato (DOCX, SRT, PDF, ecc.).
Per un confronto più approfondito delle sue funzionalità rispetto ad altre opzioni di mercato, puoi esplorare l'analisi fornita in questa guida al software speech-to-text.
Sito web: https://transcript.lol
2. Google Documenti – Digitazione vocale
Per gli utenti già integrati nell'ecosistema Google, il software gratuito speech-to-text più accessibile è probabilmente quello integrato direttamente negli strumenti che utilizzano quotidianamente. La funzione di digitazione vocale di Google Documenti è un concentrato di comodità, che offre dettatura basata su browser, senza installazione, per chiunque abbia un account Google e il browser Chrome. Eccelle nella conversione di parole pronunciate in testo in tempo reale, rendendolo ideale per la stesura di documenti, la presa di appunti rapidi o il superamento del blocco dello scrittore.
Ciò che rende efficace la digitazione vocale è la sua semplicità e la sorprendente accuratezza per la dettatura chiara e a singolo altoparlante. Supporta un vasto numero di lingue e riconosce persino comandi di formattazione di base come "nuovo paragrafo" o "grassetto". Sebbene manchino le funzionalità avanzate dei servizi di trascrizione dedicati, come l'identificazione dell'altoparlante o la marcatura temporale, il suo punto di forza risiede nella sua integrazione fluida nel flusso di lavoro di uno scrittore.
Avvio rapido e caso d'uso
Per iniziare, apri semplicemente un Documento Google, vai su Strumenti > Digitazione vocale e fai clic sull'icona del microfono. Questo è uno strumento perfetto per gli studenti che redigono saggi, i creatori di contenuti che delineano script o i professionisti che catturano verbali di riunioni mentre accadono. È uno strumento di dettatura diretto e live, non un servizio per caricare file audio preregistrati.
| Analisi delle funzionalità | Dettagli |
|---|---|
| Funzione principale | Dettatura live direttamente in un documento |
| Accessibilità | Gratuito con un account Google; funziona in Chrome |
| Funzionalità chiave | Supporto multilingue, comandi vocali di base |
| Limitazioni | Nessun caricamento di file, nessuna diarizzazione dell'altoparlante |
In definitiva, lo strumento di Google è la scelta ideale per la creazione immediata e diretta di documenti senza software aggiuntivi. Per approfondire cosa influenza i risultati della trascrizione, puoi saperne di più su i fattori che influenzano l'accuratezza speech-to-text.
Sito web: https://docs.google.com
3. Microsoft Windows 11 – Accesso vocale e digitazione vocale
Per gli utenti di Windows 11, un potente software gratuito speech-to-text attento alla privacy è già integrato nel sistema operativo. L'accesso vocale e la digitazione vocale in Windows 11 forniscono una dettatura robusta sul dispositivo che funziona a livello di sistema, dall'elaborazione di testi ai browser web. Questa soluzione integrata è eccellente per gli utenti che danno priorità alla funzionalità offline e desiderano mantenere i propri dati locali, poiché il riconoscimento vocale avviene sul dispositivo stesso.
Offre una dettatura fluida con punteggiatura automatica e supporta comandi vocali per l'editing del testo e la navigazione del sistema, come l'apertura di applicazioni o il clic sui pulsanti. Ciò lo rende uno strumento formidabile sia per l'accessibilità che per la produttività generale, consentendo di controllare il PC e creare testo senza toccare la tastiera. Sebbene le sue funzionalità più avanzate siano ottimizzate per l'inglese statunitense, offre un'esperienza fluida senza la necessità di installazioni o account di terze parti.
Avvio rapido e caso d'uso
Per avviare la digitazione vocale, premi semplicemente tasto logo Windows + H in qualsiasi campo di testo attivo. Per il controllo completo del sistema, abilita l'accesso vocale in Impostazioni > Accessibilità > Voce. Questa è una soluzione ideale per i professionisti che redigono e-mail direttamente in Outlook, gli studenti che prendono appunti in OneNote o qualsiasi utente che desideri ridurre la dipendenza dalla tastiera per le attività informatiche quotidiane.
| Analisi delle funzionalità | Dettagli |
|---|---|
| Funzione principale | Dettatura live e controllo PC a livello di sistema |
| Accessibilità | Gratuito e integrato in Windows 11 |
| Funzionalità chiave | Elaborazione sul dispositivo, uso offline, comandi vocali |
| Limitazioni | Il supporto linguistico varia; migliore in inglese statunitense |
In definitiva, gli strumenti nativi di Windows 11 sono la scelta migliore per gli utenti che cercano una soluzione di dettatura integrata, sicura e offline in grado di funzionare su tutte le loro applicazioni.
Sito web: https://www.microsoft.com/en-us/windows/tips/voice-access
4. Otter.ai
Per coloro che necessitano di più della semplice dettatura, Otter.ai si posiziona come un potente assistente AI per riunioni. Si distingue come un software gratuito speech-to-text di prim'ordine progettato specificamente per trascrivere conversazioni, riunioni e interviste. Il suo punto di forza principale risiede nella capacità di gestire più altoparlanti, identificando ed etichettando chi ha detto cosa in tempo reale o da un file audio, rendendolo prezioso per ambienti collaborativi.
Ciò che rende Otter.ai particolarmente utile per i team è la sua integrazione con piattaforme come Zoom, Google Meet e Microsoft Teams. L'IA genera note ricercabili, elementi d'azione e riassunti concisi dalle conversazioni, trasformando discussioni disordinate in registrazioni organizzate e attuabili. Il generoso livello gratuito fornisce una quantità sostanziale di minuti di trascrizione al mese, sebbene con alcune limitazioni sulla durata dell'importazione e sulle funzionalità rispetto ai suoi piani a pagamento.
Avvio rapido e caso d'uso
Per iniziare, registrati per un account gratuito e collegalo al tuo calendario per far sì che l'Assistente Otter si unisca automaticamente e trascriva le tue riunioni virtuali. Puoi anche registrare direttamente conversazioni o caricare file audio. È uno strumento perfetto per i project manager che catturano stand-up di team, i giornalisti che conducono interviste o gli studenti che registrano lezioni per una revisione successiva. Se sei nuovo in questo processo, capire come trascrivere audio in testo gratuitamente può fornire una solida base.
| Analisi delle funzionalità | Dettagli |
|---|---|
| Funzione principale | Trascrizione live di riunioni e presa di appunti |
| Accessibilità | Modello freemium con app web e mobili |
| Funzionalità chiave | Identificazione dell'altoparlante, riassunti AI, integrazioni per riunioni |
| Limitazioni | Il livello gratuito ha limiti sulla durata dell'importazione e sui minuti mensili |
In definitiva, Otter.ai è la scelta ideale per chiunque abbia bisogno di catturare, organizzare e condividere approfondimenti da conversazioni multi-altoparlante, colmando il divario tra audio grezzo e note strutturate.
Sito web: https://otter.ai
5. Descript
Descript va oltre la semplice trascrizione, posizionandosi come un editor audio e video all-in-one basato su testo. Per podcaster, YouTuber e creatori di contenuti, è uno strumento che cambia il gioco che unisce il processo di trascrizione direttamente all'editing multimediale. Invece di fornire solo una trascrizione, Descript consente di modificare video o audio semplicemente modificando il testo, rendendolo un software gratuito speech-to-text incredibilmente intuitivo per la produzione multimediale.
Ciò che rende Descript unico è il suo flusso di lavoro basato sulla trascrizione. L'eliminazione di una parola o di una frase nel testo la taglia automaticamente dal file audio o video, con transizioni fluide. Include anche potenti funzionalità AI come la rimozione delle parole di riempimento ("ehm", "uh") con un clic e una funzione "Overdub" per creare un clone AI della tua voce per correggere gli errori. Sebbene il suo livello gratuito sia più una prova con ore di trascrizione limitate, offre un assaggio completo di questo potente paradigma di editing.
Avvio rapido e caso d'uso
Per iniziare, registrati per un account gratuito, crea un nuovo progetto e trascina il tuo file audio o video. Descript lo trascriverà automaticamente, presentandoti l'editor basato su testo. Questo è ideale per i podcaster che ripuliscono interviste, i professionisti del marketing che creano clip per i social media da video di lunga durata o i team aziendali che modificano webinar e materiali di formazione senza bisogno di complessi software di editing video.
| Analisi delle funzionalità | Dettagli |
|---|---|
| Funzione principale | Editing audio/video integrato basato su testo |
| Accessibilità | Livello di prova gratuito con ore limitate; richiede un piano a pagamento per l'uso continuativo |
| Funzionalità chiave | Rimozione parole di riempimento, pulizia audio AI (Studio Sound), editing multitraccia |
| Limitazioni | Nessun piano gratuito permanente; può avere una curva di apprendimento per le funzionalità avanzate |
In definitiva, Descript è la scelta migliore per chiunque abbia esigenze di trascrizione direttamente legate alla creazione di contenuti e all'editing multimediale, offrendo un flusso di lavoro che nessun servizio di trascrizione tradizionale può eguagliare.
Sito web: https://www.descript.com
6. OpenAI Whisper (open source)
Per sviluppatori e utenti con competenze tecniche, Whisper di OpenAI rappresenta l'apice del software gratuito speech-to-text open-source. Invece di un servizio web pronto all'uso, Whisper è una raccolta di potenti modelli di riconoscimento vocale automatico (ASR) che puoi eseguire sul tuo hardware. Questo approccio offre un controllo senza precedenti sulla privacy ed elimina i costi di trascrizione continui per minuto, poiché l'unica spesa è la potenza di calcolo richiesta.
Whisper è rinomato per la sua eccezionale accuratezza in una vasta gamma di lingue e la sua capacità di gestire audio difficili con rumore di fondo. La sua vera forza risiede nella sua flessibilità; può essere integrato in applicazioni personalizzate, utilizzato per l'elaborazione batch di grandi volumi di file audio ed eseguire persino la traduzione diretta da parlato a inglese. Sebbene richieda una configurazione tecnica, il compromesso è un motore di trascrizione di livello professionale senza le commissioni ricorrenti dei servizi commerciali.
Avvio rapido e caso d'uso
Per iniziare, è necessario installare Python e la libreria Whisper dal suo repository GitHub. Da lì, puoi eseguire trascrizioni tramite la riga di comando sui tuoi file audio locali. È ideale per i ricercatori che analizzano grandi set di dati audio, gli sviluppatori che integrano funzionalità di trascrizione nelle loro app o i podcaster che desiderano elaborare in batch il loro intero catalogo arretrato in modo privato ed economico.
| Analisi delle funzionalità | Dettagli |
|---|---|
| Funzione principale | Trascrizione audio di alta precisione |
| Accessibilità | Gratuito e open-source; richiede configurazione locale (Python, GPU) |
| Funzionalità chiave | Diverse dimensioni di modelli, supporto multilingue, traduzione |
| Limitazioni | Richiede configurazione tecnica, nessuna dettatura in tempo reale, può "allucinare" |
In definitiva, Whisper è la scelta per coloro che danno priorità al controllo, alla privacy e all'accuratezza rispetto alla convenienza "out-of-the-box". Puoi scoprire di più su come modelli come questo si inseriscono nel panorama più ampio del software di trascrizione basato sull'intelligenza artificiale.
Sito web: https://github.com/openai/whisper
7. whisper.cpp (porting C/C++ di Whisper)
Per sviluppatori e utenti attenti alla privacy che cercano trascrizioni locali ad alte prestazioni, whisper.cpp offre un'alternativa potente ai servizi basati su cloud. Questo progetto è un porting C/C++ del modello Whisper di OpenAI, ottimizzato per prestazioni CPU efficienti, incluso il supporto nativo per Apple Silicon. Essendo uno strumento a riga di comando, offre un'esperienza software gratuito speech-to-text robusta interamente offline, garantendo che nessun dato lasci mai la tua macchina. È la soluzione ideale per elaborare audio sensibile senza fare affidamento su server esterni o dipendenze Python.
Ciò che distingue whisper.cpp è la sua pura efficienza e portabilità. Funziona senza uno stack software pesante, rendendolo veloce e rispettoso delle risorse su laptop e desktop moderni. Utilizzando modelli quantizzati, bilancia alta precisione con dimensioni di file e velocità di elaborazione gestibili, rendendolo accessibile anche senza una potente GPU. Sebbene la sua interfaccia a riga di comando richieda una certa familiarità tecnica, il compromesso è un controllo, una privacy e prestazioni senza pari per la trascrizione audio offline.
Avvio rapido e caso d'uso
Per iniziare, è necessario clonare il repository GitHub, compilare il codice e scaricare un modello Whisper pre-addestrato. Dal terminale, quindi, esegui un semplice comando che punta al tuo file audio. Questo strumento è perfetto per i giornalisti che trascrivono interviste sensibili, i ricercatori che elaborano registrazioni sul campo senza connessione Internet o gli sviluppatori che integrano funzionalità di trascrizione direttamente nelle applicazioni locali.
| Analisi delle funzionalità | Dettagli |
|---|---|
| Funzione principale | Trascrizione di file audio offline ad alte prestazioni |
| Accessibilità | Gratuito e open-source; richiede compilazione |
| Funzionalità chiave | Ottimizzato per Apple Silicon/AVX, nessuna necessità di Python, quantizzazione del modello |
| Limitazioni | Solo riga di comando (nessuna GUI), richiede il download e la configurazione manuale del modello |
In definitiva, whisper.cpp è la scelta ideale per gli utenti che danno priorità alla privacy e alle prestazioni e che si sentono a proprio agio lavorando in un ambiente terminale.
Sito web: https://github.com/ggml-org/whisper.cpp
8. Vosk (open source, offline)
Per sviluppatori e utenti attenti alla privacy che cercano un controllo completo sui propri dati, Vosk si distingue come un potente toolkit gratuito speech-to-text offline. A differenza dei servizi basati su cloud, Vosk viene eseguito interamente sulla tua macchina locale, da un computer desktop a un Raspberry Pi. Ciò lo rende una scelta fantastica per integrare il riconoscimento vocale nelle applicazioni in cui la connettività Internet è inaffidabile o la privacy dei dati è una preoccupazione primaria.
Il suo vantaggio chiave risiede nei suoi modelli leggeri ed efficienti e nell'ampio supporto per vari linguaggi di programmazione. Vosk fornisce agli sviluppatori gli elementi costitutivi per creare applicazioni personalizzate abilitate alla voce, dagli assistenti per la casa intelligente ai sistemi di comando per auto, senza inviare alcun audio a server di terze parti. Offre un eccezionale grado di flessibilità per progetti che richiedono l'elaborazione offline.
Avvio rapido e caso d'uso
Per iniziare, è necessario integrare la libreria Vosk in un progetto utilizzando un linguaggio come Python o Java. Uno sviluppatore scaricherebbe un modello linguistico pre-addestrato, quindi utilizzerebbe l'API Vosk per il riconoscimento in streaming in tempo reale. È ideale per creare interfacce di controllo vocale per app desktop, trascrivere audio in un ambiente sicuro o creare funzionalità attivate dalla voce per sistemi embedded. La sua licenza permissiva Apache 2.0 lo rende adatto anche per uso commerciale.
| Analisi delle funzionalità | Dettagli |
|---|---|
| Funzione principale | Toolkit di riconoscimento vocale offline per sviluppatori |
| Accessibilità | Gratuito e open-source (licenza Apache 2.0) |
| Funzionalità chiave | Modelli offline leggeri, supporta oltre 20 lingue, binding per molti linguaggi di programmazione |
| Limitazioni | Richiede conoscenze di codifica, l'accuratezza può essere inferiore rispetto ai grandi modelli cloud, manca una GUI pronta all'uso |
In definitiva, Vosk è la soluzione ideale per gli sviluppatori che necessitano di un motore di riconoscimento vocale offline, personalizzabile e royalty-free da integrare direttamente nel loro software.
Sito web: https://github.com/alphacep/vosk-api
9. Amazon Transcribe (AWS)
Per sviluppatori e aziende che necessitano di un motore di trascrizione potente e scalabile, Amazon Transcribe offre una soluzione robusta all'interno dell'ecosistema Amazon Web Services (AWS). Sebbene non sia una semplice app per consumatori, fornisce un generoso livello gratuito speech-to-text che consente test approfonditi e un uso su piccola scala. Transcribe eccelle sia nello streaming in tempo reale che nell'elaborazione batch di file audio preregistrati, rendendolo altamente versatile per applicazioni tecniche come l'analisi dei call center o l'indicizzazione di contenuti multimediali.
Ciò che lo distingue è la sua suite di funzionalità di livello enterprise, come la redazione automatica di informazioni di identificazione personale (PII), la creazione di vocabolari personalizzati per migliorare l'accuratezza per gergo specifico e la diarizzazione dell'altoparlante. Il suo livello gratuito, che dura 12 mesi, fornisce tempo di elaborazione sufficiente per creare e distribuire una prova di concetto. È un servizio API-first, progettato per essere integrato in altri software piuttosto che utilizzato come strumento autonomo.
Avvio rapido e caso d'uso
Per iniziare, è necessario creare un account AWS e navigare nella console Amazon Transcribe. È possibile creare un processo di trascrizione caricando un file audio direttamente dal computer o da un bucket S3. Questo servizio è ideale per gli sviluppatori che creano applicazioni abilitate alla voce, le aziende che analizzano le chiamate del servizio clienti per il controllo qualità o le società di media che cercano di generare automaticamente sottotitoli per i loro cataloghi video su larga scala.
| Analisi delle funzionalità | Dettagli |
|---|---|
| Funzione principale | Trascrizione batch e in tempo reale basata su API |
| Accessibilità | Livello gratuito per 12 mesi, poi pay-as-you-go |
| Funzionalità chiave | Redazione PII, vocabolari personalizzati, diarizzazione dell'altoparlante |
| Limitazioni | Richiede un account AWS; può essere complesso per i non sviluppatori |
In definitiva, Amazon Transcribe è la porta d'accesso per gli utenti che necessitano di funzionalità speech-to-text industriali, altamente personalizzabili e integrate direttamente nei propri prodotti e flussi di lavoro.
Sito web: https://aws.amazon.com/transcribe/
10. Google Cloud Speech‑to‑Text (API)
Per sviluppatori e aziende che cercano un motore di livello enterprise, l'API Speech-to-Text di Google Cloud rappresenta la potente tecnologia che supporta molte applicazioni commerciali. Sebbene non sia uno strumento rivolto all'utente, offre un generoso livello gratuito sulla sua API v1, rendendolo un software gratuito speech-to-text valido per gli utenti tecnici che pilotano un progetto o gestiscono attività di trascrizione a basso volume. Fornisce l'accesso a modelli altamente avanzati ottimizzati per diversi tipi di audio, incluse chiamate telefoniche e contenuti video.
La piattaforma si distingue per le sue potenti funzionalità come la diarizzazione dell'altoparlante, il potenziamento delle parole chiave e il supporto audio multicanale, che si trovano tipicamente nei servizi a pagamento. Ciò la rende una scelta solida per esigenze di trascrizione complesse. Tuttavia, sfruttare le sue capacità richiede un account Google Cloud Platform (GCP), una configurazione di fatturazione e una certa competenza tecnica per interagire con l'API. I minuti gratuiti sono specifici per la vecchia API v1 e i costi possono accumularsi una volta che l'utilizzo scala o se sono necessari i più recenti modelli v2.
Avvio rapido e caso d'uso
Per iniziare, è necessario configurare un progetto GCP, abilitare l'API Speech-to-Text e utilizzare una libreria client (come Python o Node.js) per inviare file audio per la trascrizione. Questo è ideale per gli sviluppatori che creano funzionalità di trascrizione nelle proprie applicazioni, i data scientist che analizzano set di dati audio o le aziende che necessitano di trascrizione automatizzata per registrazioni di call center. Eccelle sia nello streaming in tempo reale che nell'elaborazione batch di file preregistrati.
| Analisi delle funzionalità | Dettagli |
|---|---|
| Funzione principale | API per trascrizione audio batch e in tempo reale |
| Accessibilità | Livello gratuito disponibile; richiede account GCP e configurazione di fatturazione |
| Funzionalità chiave | Diarizzazione dell'altoparlante, potenziamento delle parole chiave, modelli specializzati |
| Limitazioni | Richiede configurazione tecnica, i costi possono aumentare con la scala |
In definitiva, l'API di Google Cloud è una soluzione per utenti tecnici che necessitano di un motore di trascrizione potente, scalabile e altamente accurato per progetti personalizzati.
Sito web: https://cloud.google.com/speech-to-text
11. Live Transcribe (Android)
Per gli utenti Android che cercano uno strumento di trascrizione istantaneo e incentrato sull'accessibilità, Live Transcribe di Google si distingue come un potente software gratuito speech-to-text. Sviluppata principalmente per la comunità sorda e con problemi di udito, questa app fornisce sottotitoli in tempo reale per conversazioni dal vivo, rendendola uno strumento indispensabile per la comunicazione faccia a faccia. Trasforma il microfono del tuo telefono in un dispositivo di trascrizione altamente accurato e sempre attivo.

Ciò che rende unico Live Transcribe è la sua attenzione alla consapevolezza ambientale immediata. Oltre a trascrivere parole pronunciate in oltre 70 lingue, identifica anche suoni non vocali come "abbaiare di cane" o "applausi", fornendo un contesto cruciale. Sebbene sia progettato per l'interazione dal vivo e non supporti il caricamento di file, la sua opzione di elaborazione sul dispositivo offre un livello di privacy non sempre presente nei servizi basati su cloud. L'uso continuo può influire sulla durata della batteria del tuo dispositivo, quindi imparare a gestire le app che consumano batteria su Android è un passo pratico per gli utenti assidui.
Avvio rapido e caso d'uso
Per iniziare, scarica Live Transcribe dal Google Play Store o trovalo preinstallato sui dispositivi Pixel. Apri l'app, concedi le autorizzazioni del microfono e inizierà immediatamente a trascrivere il suono ambientale. Questo è perfetto per gli studenti in aula, i professionisti in riunioni improvvisate o chiunque abbia bisogno di comprendere il dialogo parlato in un ambiente rumoroso. È un eccezionale aiuto per l'accessibilità, non uno strumento per la trascrizione post-produzione.
| Analisi delle funzionalità | Dettagli |
|---|---|
| Funzione principale | Sottotitoli live per conversazioni in persona |
| Accessibilità | Gratuito sulla maggior parte dei dispositivi Android moderni |
| Funzionalità chiave | Oltre 70 lingue, etichette di eventi sonori, modalità sul dispositivo |
| Limitazioni | Solo Android, nessun caricamento di file per la trascrizione |
In definitiva, Live Transcribe eccelle nell'abbattere le barriere comunicative in tempo reale, offrendo una soluzione semplice ma potente direttamente sul dispositivo che porti ogni giorno.
Sito web: https://www.android.com/accessibility/live-transcribe/
12. Deepgram
Per sviluppatori e startup che desiderano integrare potenti funzionalità di trascrizione nelle proprie applicazioni, Deepgram offre un approccio API-first altamente sofisticato. A differenza degli strumenti per utenti finali, Deepgram è un motore progettato per creare soluzioni personalizzate, fornendo generosi $200 in crediti gratuiti per i nuovi utenti per esplorare le sue capacità. Questa piattaforma è celebrata per la sua velocità, accuratezza e funzionalità avanzate come la diarizzazione dell'altoparlante, il potenziamento delle parole chiave e la formattazione intelligente, rendendola una scelta di prim'ordine per il riconoscimento vocale automatico (ASR) a livello di produzione.
Ciò che distingue Deepgram è la sua attenzione ai moderni modelli AI, come la sua serie Nova, che offrono alta precisione su varie qualità audio e accenti. Sebbene richieda conoscenze tecniche per l'implementazione, la flessibilità che offre è impareggiabile per coloro che necessitano di testare o scalare servizi di trascrizione. Funziona come una potente infrastruttura piuttosto che come un semplice strumento gratuito speech-to-text "out-of-the-box".
Avvio rapido e caso d'uso
Per iniziare, gli sviluppatori possono registrarsi per una chiave API gratuita e utilizzare la documentazione fornita per inviare file audio preregistrati o stabilire una connessione in streaming in tempo reale. È una soluzione ideale per le aziende che creano assistenti vocali, le società di media che automatizzano la generazione di sottotitoli o i call center che necessitano di analizzare dati conversazionali. I crediti gratuiti consentono test approfonditi prima di impegnarsi in un piano a pagamento.
| Analisi delle funzionalità | Dettagli |
|---|---|
| Funzione principale | API per trascrizione pre-registrata e in tempo reale |
| Accessibilità | Gratuito per iniziare con $200 in crediti; pay-as-you-go |
| Funzionalità chiave | Diarizzazione dell'altoparlante, potenziamento delle parole chiave, scelta del modello |
| Limitazioni | Richiede conoscenze di codifica; non è uno strumento per utenti finali |
In definitiva, Deepgram è la scelta ideale per gli utenti tecnici che necessitano di un motore di trascrizione veloce, accurato e scalabile per alimentare il proprio software e prodotti.
Sito web: https://deepgram.com
12 Confronto strumenti Speech-to-Text
| Prodotto | Funzionalità principali ✨ | Precisione e UX ★ | Prezzo / Valore 💰 | Pubblico di destinazione 👥 |
|---|---|---|---|---|
| Transcript.LOL 🏆 | Base Whisper; caricamenti da 10 ore; etichettatura altoparlanti; riassunti, esportazioni, integrazioni ✨ | ★4.8 (~99.8%); editor e ricerca veloci | 💰 Livello gratuito; Illimitato $120/anno; Team $240/anno — alto valore | 👥 Podcaster, marketer, educatori, team legali |
| Google Documenti – Digitazione vocale | Dettatura browser; comandi vocali di base ✨ | ★3–4; migliore per dettatura chiara a singolo altoparlante | 💰 Gratuito con account Google | 👥 Studenti, scrittori, uso occasionale |
| Microsoft Windows 11 – Accesso vocale | Dettatura sul dispositivo e controllo di sistema; supporto offline ✨ | ★3–4; forte per l'accessibilità; necessita di campo di testo | 💰 Incluso con Windows 11 | 👥 Utenti con disabilità; preferiscono offline |
| Otter.ai | Trascrizione live di riunioni; ID altoparlante; note ricercabili; riassunti ✨ | ★4; buona UX per riunioni; multi-altoparlante dipende dall'audio | 💰 Freemium; livelli a pagamento per volumi maggiori | 👥 Team, prenditori di appunti per riunioni |
| Descript | Editing audio/video basato su testo; rimozione parole di riempimento; strumenti multitraccia ✨ | ★4; eccellente flusso di lavoro editor + trascrizione | 💰 Piani a pagamento (nessun piano gratuito permanente) — focalizzato sui creatori | 👥 Podcaster, creatori, editor |
| OpenAI Whisper (open source) | ASR multilingue; traduzione; CLI/libreria Python ✨ | ★4; forte accuratezza ma necessita di configurazione e QA | 💰 Codice gratuito; costi di calcolo applicabili | 👥 Sviluppatori, ricercatori, utenti attenti alla privacy |
| whisper.cpp | Porting Whisper ottimizzato per CPU; Apple Silicon e modelli quantizzati ✨ | ★4; inferenza CPU locale veloce (CLI) | 💰 Gratuito; costi risorse locali e archiviazione | 👥 Sviluppatori, utenti offline/Apple Silicon |
| Vosk (open source) | Modelli offline piccoli; multilingue; molti binding linguistici ✨ | ★3–4; leggero, l'accuratezza varia in base al modello | 💰 Gratuito; licenza Apache-2.0 | 👥 App embedded, ambienti a basse risorse |
| Amazon Transcribe (AWS) | Batch e streaming; redazione PII; vocabolari personalizzati ✨ | ★4; servizio enterprise scalabile | 💰 Pay-per-minute; livello gratuito limitato di 12 mesi | 👥 Sviluppatori, enterprise su AWS |
| Google Cloud Speech‑to‑Text | Tempo reale e batch; diarizzazione; potenziamento parole chiave; multicanale ✨ | ★4–5; forte accuratezza e supporto linguistico | 💰 Pay-per-use; minuti gratuiti limitati | 👥 Enterprise, clienti GCP, sviluppatori |
| Live Transcribe (Android) | Sottotitoli in tempo reale; etichette sonore; privacy sul dispositivo ✨ | ★4; affidabile per conversazioni faccia a faccia | 💰 Gratuito | 👥 Sordi/ipoacusici, utenti quotidiani |
| Deepgram | API streaming e pre-registrata; diarizzazione; potenziamento parole chiave ✨ | ★4; API performante per uso in produzione | 💰 Credito gratuito di $200; prezzi pay-per-minuto | 👥 Startup, sviluppatori, team di produzione |
Fare la scelta giusta: le nostre raccomandazioni finali
🎯 Match the Tool to Your Audio Type
Live dictation, meetings, podcasts, or pre-recorded files — every tool is optimized for specific audio scenarios. Choose based on how and when your audio is created.
🔍 Balance Accuracy with Effort
High accuracy sometimes requires setup or editing. Decide whether you prefer instant convenience or professional-grade results with minor review.
🔐 Decide How Much Privacy Matters
Cloud tools are convenient, but offline or no-training platforms are safer for sensitive meetings, research, or client conversations.
💸 Think Beyond the Free Tier
Free plans are great for testing, but long-term use may require upgrades. Understand limits on minutes, exports, and features before scaling.
Navigating the landscape of free speech-to-text software can feel overwhelming, but as we've explored, the right tool is rarely a one-size-fits-all solution. Your ideal choice hinges directly on your specific needs, from the type of audio you're transcribing to your priorities regarding privacy, workflow integration, and offline access. The journey from spoken word to written text is now more accessible than ever, powered by a diverse array of powerful and often free tools.
Speech-to-Text Is No Longer Just Transcription
Modern tools now extend beyond transcription into summarization, content creation, and collaboration. Choosing the right platform today can future-proof your workflow as AI capabilities continue to expand.
In tutta questa guida, abbiamo analizzato tutto, dagli strumenti semplici integrati nel sistema operativo ai modelli sofisticati open-source e alle potenti API basate su cloud. Il punto chiave è che il "miglior" software gratuito di sintesi vocale è quello che si integra perfettamente nel tuo flusso di lavoro, non quello con l'elenco di funzionalità più lungo.
Punti chiave per la selezione del tuo strumento
Per distillare i nostri risultati, rivisitiamo i fattori chiave decisionali. La tua scelta finale sarà probabilmente un compromesso tra convenienza, accuratezza, costo e controllo.
- Per un uso istantaneo e quotidiano: Se le tue esigenze sono semplici, come la stesura di e-mail, la presa di appunti rapidi o la creazione di documenti di base, le soluzioni integrate sono imbattibili. Digitazione vocale di Google Docs e Accesso vocale di Windows offrono un'incredibile comodità senza alcuna configurazione, rendendoli perfetti per attività spontanee.
- Per flussi di lavoro collaborativi e automatizzati: Team e professionisti che necessitano di note automatiche per riunioni, identificazione degli oratori e collaborazione basata su cloud troveranno un immenso valore in servizi come Otter.ai e Descript. I loro piani gratuiti offrono un generoso punto di partenza per semplificare flussi di lavoro di trascrizione complessi.
- Per la massima privacy e controllo: Quando la privacy dei dati è non negoziabile o è necessario elaborare informazioni sensibili, i modelli offline open-source sono lo standard di riferimento. OpenAI Whisper e il suo efficiente corrispettivo, whisper.cpp, forniscono un'accuratezza all'avanguardia garantendo al contempo che i tuoi dati non lascino mai la tua macchina locale.
- Per esigenze specializzate e ad alto volume: Sviluppatori e aziende che richiedono trascrizioni scalabili e ad alta accuratezza per applicazioni dovrebbero rivolgersi alle potenti API offerte da Google Cloud Speech-to-Text, Amazon Transcribe e Deepgram. I loro piani gratuiti sono progettati per consentirti di creare e testare prima di impegnarti in un piano a pagamento.
Prossimi passi attuabili per l'implementazione
Ora che hai un quadro più chiaro delle opzioni disponibili, è il momento di agire. Non rimanere bloccato nella paralisi da analisi; il modo migliore per trovare la soluzione giusta è iniziare a sperimentare.
- Identifica il tuo caso d'uso principale: Sei un podcaster che necessita di trascrizioni di episodi, uno studente che registra lezioni o uno sviluppatore che crea un'app abilitata alla voce? Definisci prima il tuo requisito più importante.
- Testa i tuoi due candidati principali: In base alle tue esigenze principali, seleziona due strumenti dal nostro elenco che sembrano più promettenti. Ad esempio, se sei un creatore di video, potresti confrontare il piano gratuito di Descript con un'installazione locale di Whisper.
- Esegui un test nel mondo reale: Utilizza un file audio breve e rappresentativo (5-10 minuti) ed elaboralo con entrambi gli strumenti. Confronta i risultati in base ad accuratezza, formattazione, velocità e all'esperienza utente complessiva. Uno strumento ha gestito meglio il gergo o più oratori? Il processo di modifica è stato più semplice in uno rispetto all'altro?
- Valuta l'impatto sul flusso di lavoro: Considera come ogni strumento si inserisce nel tuo processo esistente. Richiede passaggi aggiuntivi o ti fa risparmiare tempo? Il miglior software gratuito di sintesi vocale non solo produce una trascrizione eccellente, ma rende anche più efficiente l'intero flusso di lavoro.
In definitiva, la potenza della moderna tecnologia di sintesi vocale risiede nella sua capacità di sbloccare il valore intrappolato nei tuoi contenuti audio e video. Trasformando le parole pronunciate in testo ricercabile, modificabile e condivisibile, apri nuove possibilità per la creazione di contenuti, l'accessibilità, la ricerca e la produttività. Lo strumento perfetto è in attesa di essere integrato nel tuo flusso di lavoro, pronto a farti risparmiare tempo e fatica.
Pronto a sperimentare uno strumento di trascrizione che dà priorità alla privacy, all'accuratezza e a un flusso di lavoro meravigliosamente semplice? Mentre molti strumenti gratuiti presentano limitazioni sulla privacy o sulle funzionalità, Transcript.LOL è progettato per professionisti che necessitano di trascrizioni affidabili e sicure senza la complessità. Dai alla tua audio la trascrizione privata e di alta qualità che merita provando Transcript.LOL oggi stesso.