Du son au texte : votre guide des logiciels de reconnaissance vocale
Découvrez comment le logiciel de reconnaissance vocale transforme l'audio en contenu précieux. Apprenez son fonctionnement, quelles fonctionnalités sont importantes et comment choisir le bon outil.
Praveen
February 17, 2025
Le logiciel de reconnaissance vocale est la magie qui transforme les mots parlés d'un fichier audio en texte brut et utilisable. Pensez-y comme à votre propre sténographe numérique, prêt à écouter des enregistrements, des réunions ou des notes vocales et à produire un document modifiable et consultable en quelques minutes. C'est un incontournable pour quiconque cherche à gagner beaucoup de temps et à rendre son contenu audio beaucoup plus utile.
Débloquez votre audio : des ondes sonores au texte consultable
Fonctionnalités de transcription par IA
IA de pointe
Alimenté par Whisper d'OpenAI pour une précision de premier plan. Prise en charge des vocabulaires personnalisés, des fichiers jusqu'à 10 heures et des résultats ultra rapides.

Importer depuis plusieurs sources
Importez des fichiers audio et vidéo depuis diverses sources, y compris le téléchargement direct, Google Drive, Dropbox, les URL, Zoom et plus encore.

Détection des intervenants
Identifiez automatiquement les différents intervenants dans vos enregistrements et étiquetez-les avec leurs noms.
Imaginez : vous venez de terminer un excellent épisode de podcast de deux heures ou une série d'entretiens approfondis avec des clients. Cet audio regorge d'informations précieuses, de citations percutantes et d'idées révolutionnaires, mais tout cela est piégé dans un fichier sonore. Vous ne pouvez pas le rechercher, vous ne pouvez pas facilement le citer, et le réutiliser est un cauchemar. Vous vous retrouvez face à une montagne d'audio avec la tâche décourageante de taper chaque mot.
C'est un goulot d'étranglement classique pour les créateurs, les chercheurs, les spécialistes du marketing et les étudiants. Tout ce temps passé courbé sur un clavier, à transcrire manuellement, pourrait être consacré à l'analyse, à la création de nouveau contenu ou à une véritable réflexion stratégique. Le logiciel de reconnaissance vocale brise cette barrière, agissant comme le pont entre vos paroles et un contenu numérique exploitable.
Mais cette technologie ne se contente plus de taper pour vous ; elle vise à libérer le potentiel caché de votre audio. Elle transforme vos fichiers audio et vidéo d'enregistrements statiques en atouts dynamiques et polyvalents.
- Découvrabilité : Une transcription rend votre contenu audio indexable par les moteurs de recherche, aidant ainsi un tout nouveau public à trouver votre travail.
- Accessibilité : Elle offre une alternative textuelle aux personnes sourdes ou malentendantes, élargissant instantanément votre portée.
- Réutilisation : Elle vous permet de récupérer rapidement des citations pour les réseaux sociaux, de transformer des interviews en articles de blog, ou de créer des notes d'émission détaillées sans effort.
La demande pour cela explose. Le marché mondial des API de reconnaissance vocale était évalué à 2,2 milliards de dollars en 2021 et devrait atteindre 5,4 milliards de dollars d'ici 2026. Cette croissance incroyable montre à quel point la technologie vocale est devenue essentielle dans presque toutes les industries. Vous pouvez trouver une analyse complète dans ce rapport détaillé sur le marché des API de reconnaissance vocale.
Fondamentalement, le processus est assez simple. Si vous souhaitez comprendre les mécanismes de base, vous pouvez découvrir comment créer une transcription à partir de n'importe quel fichier audio. Les outils modernes ont rendu cela extrêmement simple, vous fournissant un document très précis avec presque aucun effort. L'ajout de fonctionnalités telles que les horodatages est également un atout majeur pour synchroniser le texte avec l'audio, ce qui est une aubaine pour les monteurs vidéo et les chercheurs. Pour voir comment cela fonctionne, consultez notre guide sur l'obtention d'une transcription avec timecode pour une précision millimétrée.
Comment l'IA apprend à écouter et à transcrire
Avez-vous déjà utilisé un logiciel de reconnaissance vocale ? Cela peut sembler magique. Vous téléchargez un fichier audio ou commencez à parler, et quelques instants plus tard, une transcription presque parfaite apparaît à l'écran. Mais derrière ce processus apparemment simple se cache une collaboration fascinante entre différents modèles d'IA qui travaillent ensemble pour écouter, comprendre et écrire, un peu comme le ferait un humain.
Pensez-y comme à la formation d'une toute nouvelle sténographe. D'abord, elle doit apprendre à distinguer les sons individuels. Ensuite, elle doit reconnaître ces sons comme des mots. Enfin, elle doit assembler ces mots en phrases qui ont un sens réel. Une IA suit un chemin étonnamment similaire pour atteindre sa haute précision.
L'ensemble du processus démarre dès que le logiciel met la main sur votre fichier audio. Il commence par décomposer l'onde sonore continue de votre voix en milliers de petites unités sonores individuelles. Ce sont les phonèmes : les plus petits éléments constitutifs du langage parlé, comme le son "k" dans "chat" ou le son "ch" dans "chaud".
Le modèle acoustique : entendre les mots
Une fois l'audio découpé en ces fragments sonores fondamentaux, le modèle acoustique intervient. C'est l'oreille de l'IA. Il a été entraîné sur une immense bibliothèque de langage parlé, contenant des centaines de milliers d'heures d'audio méticuleusement associées à leurs transcriptions textuelles.
Cet entraînement intensif fait du modèle acoustique un expert dans une chose : faire correspondre les phonèmes entrants aux lettres et aux mots qu'il connaît déjà. Il analyse les fréquences et les motifs spécifiques de chaque son et fait une supposition éclairée, demandant : "Ce petit fragment sonore correspond-il au phonème pour 't', 'o', ou 'p' ?"
Bien sûr, ce n'est rarement parfait en soi. Des éléments tels que les accents, le bruit de fond ou simplement le fait de parler très vite peuvent facilement dérouter le modèle acoustique. Le résultat peut être un mélange de mots qui sonnent juste mais n'ont absolument aucun sens. C'est là qu'intervient la couche d'IA suivante.
Ce schéma montre le flux de base d'une onde sonore à un document texte final.
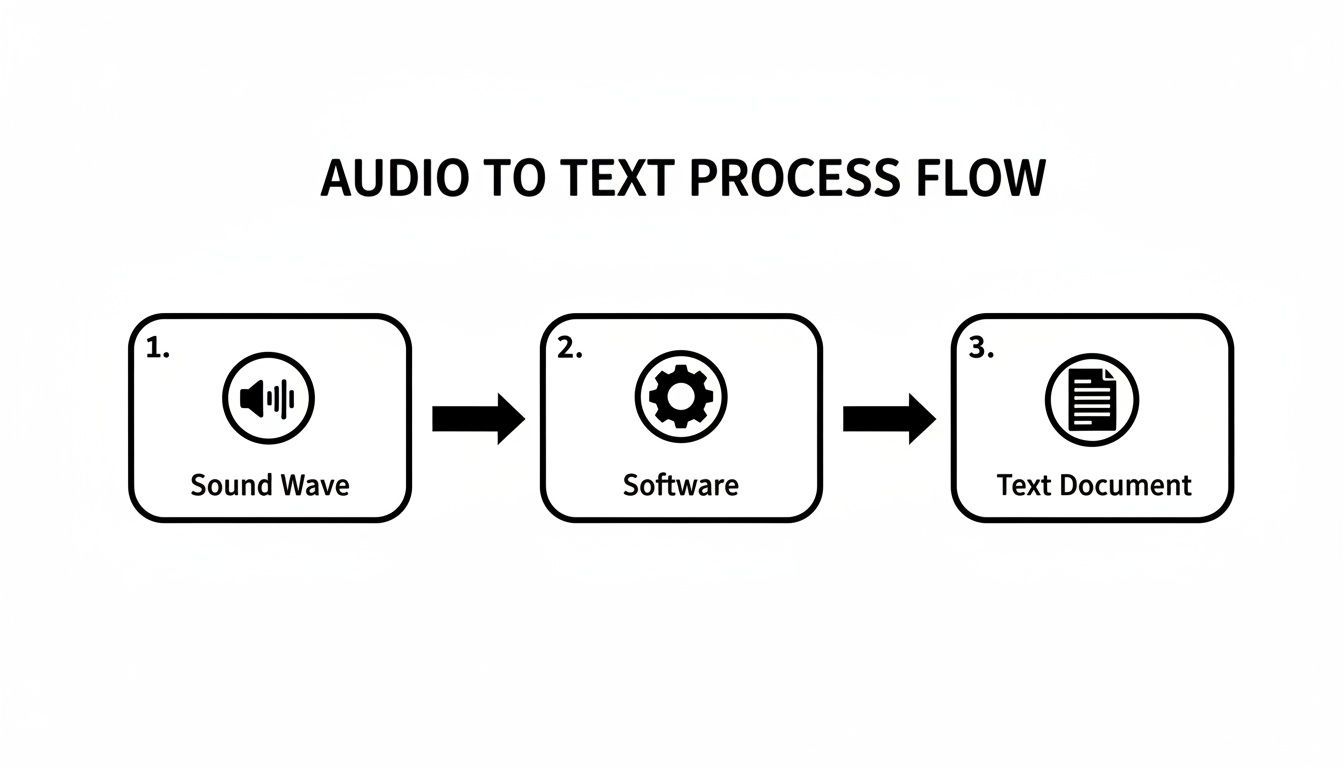
Cette simple conversion est alimentée par des modèles d'IA complexes travaillant en tandem pour garantir que le texte final soit à la fois précis et lisible.
Le modèle linguistique : donner du sens à tout cela
Après que le modèle acoustique a produit son brouillon, le modèle linguistique prend le relais. Vous pouvez le considérer comme le cerveau de l'IA ou son éditeur interne. Alors que le modèle acoustique s'intéresse aux sons, le modèle linguistique est obsédé par le contexte, la grammaire et la probabilité.
Il a été entraîné sur une gigantesque bibliothèque de textes – livres, articles, sites web, tout ce que vous voulez – il a donc une compréhension approfondie de la façon dont les mots sont censés s'articuler. Il examine la sortie maladroite du modèle acoustique et commence à poser des questions critiques :
- Grammaire : Cette phrase est-elle construite correctement ?
- Contexte : Ce mot suit-il logiquement le précédent ?
- Probabilité : Est-il plus probable que l'orateur ait dit "Je crie pour la crème glacée" ou "Œil crie pour œil crie" ?
Par exemple, un modèle acoustique pourrait entendre "reconnaître la parole" et "reconnaître une belle plage" comme étant presque identiques. Mais le modèle linguistique sait que "reconnaître la parole" est une phrase beaucoup plus courante et logique, surtout dans le contexte d'une transcription. Il corrige ce type d'erreurs, lisse les formulations maladroites et ajoute même de la ponctuation en fonction des pauses et de l'intonation de l'orateur. Ce système en deux parties est le secret derrière la façon dont l'IA audio vers texte obtient des résultats aussi impressionnants.
Pourquoi deux modèles sont importants
Les modèles acoustiques se concentrent sur la précision sonore, tandis que les modèles linguistiques garantissent le contexte et la lisibilité. Ensemble, ils réduisent les erreurs causées par les accents, les homophones et la prononciation peu claire. Cette approche multicouche explique pourquoi les outils modernes de reconnaissance vocale surpassent les anciens systèmes de dictée.
Point clé : La précision du logiciel de reconnaissance vocale repose sur un duo puissant. L'modèle acoustique transforme le son brut en une liste de mots probables, et le modèle linguistique utilise le contexte et la grammaire pour transformer cette liste en un texte cohérent et précis.
Toute cette collaboration se déroule en une fraction de seconde, transformant un flux audio désordonné en un document propre et structuré, prêt à être utilisé.
Choisir votre boîte à outils : Fonctionnalités essentielles et avancées
Choisir le bon logiciel de reconnaissance vocale, c'est un peu comme choisir une voiture. Une berline de base vous emmène du point A au point B, sans problème. Mais si vous avez besoin de transporter du matériel lourd, il vous faudra un camion spécialisé.
De la même manière, presque tous les outils peuvent transformer l'audio en mots, mais les meilleurs sont dotés de fonctionnalités conçues pour gérer des flux de travail exigeants et spécifiques sans transpirer. Pour choisir le bon, vous devez séparer ce qui est indispensable de ce qui est un plus.
Les non-négociables : Fonctionnalités de transcription de base
Avant de vous laisser distraire par des gadgets brillants, assurez-vous que le logiciel maîtrise les bases. Ce sont les piliers qui rendent un outil véritablement utile au lieu d'une source de frustration constante.
Considérez-les comme le moteur, les roues et la direction de votre véhicule de transcription : si vous vous trompez, vous n'irez nulle part.
- Haute précision : C'est le plus important. Une transcription pleine d'erreurs crée plus de travail qu'elle n'en économise, vous obligeant à passer des heures à corriger. Vous devriez rechercher des plateformes qui atteignent constamment 95 % de précision ou plus sur un audio clair.
- Large prise en charge des formats de fichiers : Vos fichiers audio et vidéo existent sous toutes formes et tailles. Un bon outil doit gérer les formats courants tels que MP3, MP4, M4A et WAV sans vous obliger à convertir les fichiers au préalable.
- Limites de fichiers généreuses : Les projets du monde réel impliquent souvent du contenu long. Qu'il s'agisse d'un podcast de deux heures ou d'une conférence d'une journée entière, le logiciel doit gérer de gros fichiers et de longs enregistrements sans faillir.
Ces trois fonctionnalités constituent la base absolue de tout logiciel de reconnaissance vocale efficace. C'est ce qui rend un outil fiable et suffisamment flexible pour un travail réel.
Au-delà des bases : Fonctionnalités avancées qui font gagner un temps précieux
Une fois que l'outil maîtrise les fondamentaux, il est temps de se pencher sur les fonctionnalités avancées. C'est là qu'un bon service devient excellent, transformant un simple outil de transcription en une véritable centrale de productivité.
Fonctionnalités de productivité et d'exportation
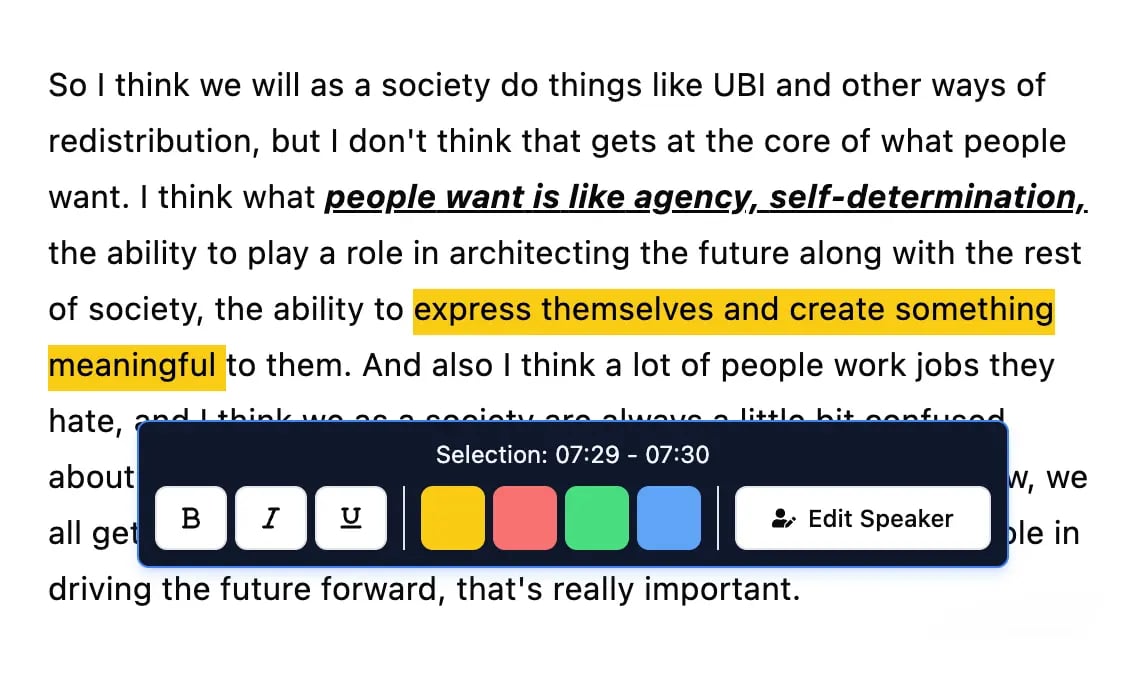
Outils d'édition
Modifiez les transcriptions avec des outils puissants incluant rechercher et remplacer, attribution des intervenants, formats de texte enrichi et surlignage.
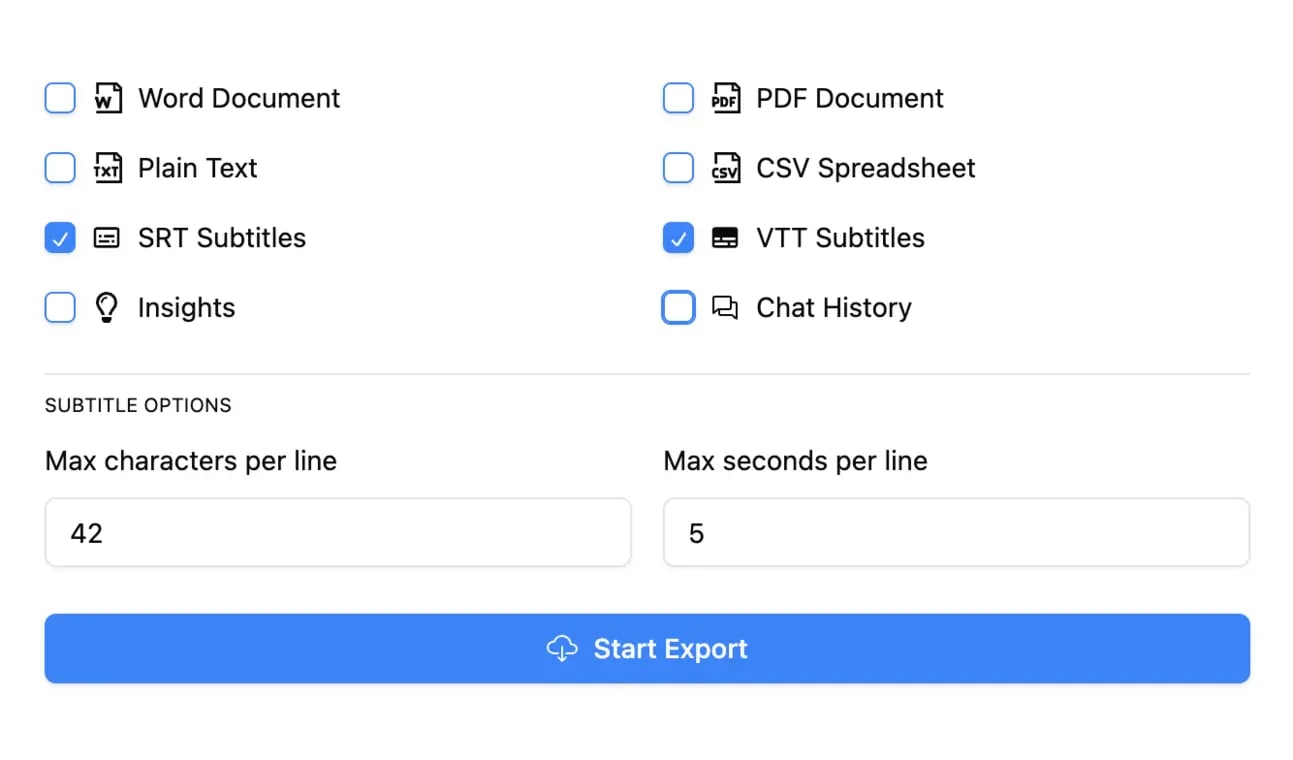
Exporter en plusieurs formats
Exportez vos transcriptions en plusieurs formats dont TXT, DOCX, PDF, SRT et VTT avec des options de formatage personnalisables.
Résumés et Chatbot
Générez des résumés et d'autres analyses de votre transcription, des prompts personnalisés réutilisables et un chatbot pour votre contenu.
Ce sont le GPS, la transmission intégrale et l'espace de chargement supplémentaire de votre logiciel : ils vous aident à naviguer dans des projets complexes, à gérer une charge de travail plus importante et à performer lorsque les conditions deviennent difficiles. Et le marché de ces outils est en plein essor. Le marché des API de reconnaissance vocale était évalué à 2,77 milliards de dollars en 2023 et devrait atteindre 9,86 milliards de dollars d'ici 2032, selon un récent rapport sur le marché des API de reconnaissance vocale.
Idée clé : Pour les professionnels, les fonctionnalités avancées ne sont pas de simples avantages. Elles se traduisent directement par un gain de temps, un travail de meilleure qualité et des flux de travail plus fluides.
Voici les éléments qui changent la donne à rechercher :
- Étiquetage automatique des intervenants (Diarisation) : C'est une aubaine pour tout enregistrement impliquant plusieurs personnes : interviews, réunions, groupes de discussion, etc. Le logiciel identifie automatiquement qui parle et étiquette le dialogue ("Intervenant 1", "Intervenant 2"), vous épargnant ainsi la tâche fastidieuse de le faire manuellement.
- Vocabulaire personnalisé : Les modèles d'IA standard ont souvent du mal avec le jargon industriel, les acronymes d'entreprise ou les noms spécifiques. Une fonctionnalité de vocabulaire personnalisé vous permet d'"enseigner" à l'IA ces termes spécifiques, ce qui améliore considérablement la précision pour le contenu spécialisé dans des domaines tels que la médecine, le droit ou la technologie.
- Intégrations transparentes : Les meilleurs outils s'intègrent bien avec les autres. Recherchez des intégrations avec les plateformes que vous utilisez déjà, comme Google Drive, Dropbox ou YouTube. Cela crée un flux de travail automatisé où vos fichiers sont transcrits automatiquement, sans téléchargements manuels. Notre guide sur les logiciels de transcription alimentés par l'IA montre comment ces connexions créent un système beaucoup plus efficace.
- Options d'exportation polyvalentes : Un simple fichier .txt n'est souvent pas suffisant. Les plateformes de premier plan vous permettent d'exporter des transcriptions dans plusieurs formats, tels que DOCX pour les rapports, SRT/VTT pour les sous-titres vidéo, et des PDF pour un partage facile. Cette flexibilité rend votre transcription immédiatement utile, quelle que soit votre utilisation.
- Politique de confidentialité des données robuste : C'est un point important. Lorsque vous téléchargez des conversations sensibles, vous devez savoir que vos données sont sécurisées. Choisissez uniquement un fournisseur avec une politique de confidentialité claire qui garantit qu'il n'utilisera pas vos données pour entraîner ses modèles d'IA. C'est le seul moyen de garantir que vos informations confidentielles restent telles quelles.
Pour vous aider à décider ce qui vous convient le mieux, voici un aperçu rapide des fonctionnalités essentielles par rapport aux fonctionnalités plus avancées.
Fonctionnalités essentielles vs avancées de la reconnaissance vocale
| Fonctionnalité | Ce qu'elle fait | Qui en a le plus besoin |
|---|---|---|
| Haute précision | Fournit une transcription avec un minimum d'erreurs, nécessitant peu ou pas de correction. | Tout le monde. C'est l'exigence fondamentale pour tout outil de transcription utile. |
| Prise en charge de formats de fichiers variés | Accepte les fichiers audio et vidéo courants (MP3, MP4, WAV) sans nécessiter de conversion. | Les utilisateurs qui travaillent avec diverses sources multimédias et ne veulent pas se soucier de la préparation des fichiers. |
| Limites de fichiers généreuses | Gère les enregistrements longs (par exemple, plus de 2 heures) et les fichiers volumineux sans défaillance. | Podcasteurs, chercheurs, journalistes et toute personne traitant du contenu long. |
| Étiquetage des intervenants | Identifie et étiquette automatiquement les différents intervenants dans la transcription (par exemple, "Intervenant 1"). | Intervieweurs, organisateurs de réunions et chercheurs qualitatifs qui ont besoin de distinguer les voix. |
| Vocabulaire personnalisé | Permet d'ajouter des termes, des noms ou du jargon spécifiques pour améliorer la précision de la reconnaissance. | Professionnels des domaines techniques (médical, juridique, financier) où la précision est essentielle. |
| Intégrations | Se connecte à d'autres applications comme Google Drive ou YouTube pour automatiser le flux de travail de transcription. | Créateurs de contenu, spécialistes du marketing et équipes cherchant à construire des pipelines de contenu efficaces et automatisés. |
| Options d'exportation polyvalentes | Permet de télécharger des transcriptions dans plusieurs formats (DOCX, SRT, VTT, PDF) pour différentes utilisations. | Monteurs vidéo ayant besoin de sous-titres, rédacteurs préparant des rapports et toute personne réutilisant du contenu sur plusieurs plateformes. |
| Garanties de confidentialité des données | Garantit que vos fichiers audio/vidéo confidentiels ne sont pas utilisés pour entraîner des modèles d'IA. | Professionnels du droit, thérapeutes, équipes d'entreprise et toute personne traitant des informations sensibles ou propriétaires. |
En fin de compte, le meilleur outil est celui qui s'adapte à votre flux de travail. En comprenant la différence entre les nécessités fondamentales et les ajouts puissants, vous pouvez trouver une solution qui non seulement résout les problèmes d'aujourd'hui, mais est prête à évoluer avec vous.
Mettre la transcription au travail dans tous les secteurs
Bien sûr, la technologie derrière la reconnaissance vocale est fascinante, mais c'est dans la résolution de problèmes quotidiens qu'elle brille vraiment. Il ne s'agit pas seulement de transformer l'audio en mots ; c'est un moteur de productivité qui permet d'économiser d'innombrables heures, de débloquer du nouveau contenu et de rendre l'information plus accessible dans des dizaines de domaines. L'impact est réel : il transforme des heures de travail manuel fastidieux en minutes d'action ciblée et stratégique.
Des équipes marketing aux amphithéâtres universitaires, les applications sont aussi diverses que précieuses. Chaque secteur utilise la transcription pour relever ses propres défis uniques, qu'il s'agisse de mettre à l'échelle la production de contenu, d'améliorer les résultats des étudiants ou de tenir des registres méticuleux pour la conformité juridique et médicale.
Comment différentes équipes utilisent la reconnaissance vocale ?
Créateurs de contenu
Les podcasteurs et les YouTubers transforment les épisodes en blogs, légendes et publications sur les réseaux sociaux sans temps d'enregistrement supplémentaire. Un fichier devient plusieurs éléments de contenu.
Chercheurs et universitaires
Les transcriptions d'interviews deviennent des ensembles de données consultables, accélérant l'analyse qualitative et réduisant le temps de recherche.
Équipes d'entreprise
Les enregistrements de réunions se transforment en procès-verbaux clairs, en éléments d'action et en archives de connaissances qui maintiennent les équipes alignées.
Professionnels de la santé
Les médecins dictent des notes directement dans les systèmes, réduisant la charge administrative tout en maintenant des dossiers médicaux précis.
Le fil conducteur est toujours l'efficacité. Il s'agit de libérer les professionnels pour qu'ils se concentrent sur un travail à forte valeur ajoutée au lieu d'être embourbés dans la transcription manuelle.
Marketing de contenu et production médiatique
Pour toute personne travaillant dans le marketing ou les médias, un seul fichier audio ou vidéo est une mine d'or. Un podcast ou un webinaire d'une heure, une fois transcrit, devient la matière première pour une douzaine d'autres contenus. Cette stratégie "créer une fois, distribuer plusieurs fois" est le secret pour maximiser votre retour sur investissement et atteindre un public beaucoup plus large.
Pensez à une seule interview de podcast. L'audio est excellent, mais la transcription est un couteau suisse marketing.
- Articles de blog et articles : La transcription complète peut être peaufinée en un article de blog complet, parsemé de mots-clés pour attirer le trafic organique des moteurs de recherche.
- Contenu pour les réseaux sociaux : Extrayez les meilleures citations et extraits sonores pour créer des graphiques accrocheurs, de courts clips vidéo et des publications percutantes sur les réseaux sociaux.
- Newsletters par e-mail : Un résumé rapide ou une liste des points clés constitue une newsletter pleine de valeur qui maintient l'engagement de votre public.
- Aimants à prospects : Mettez la transcription en forme dans un PDF téléchargeable et proposez-la comme ressource gratuite pour capturer de nouveaux prospects.
C'est là que des outils spécialisés s'avèrent utiles, comme les outils de transcription de podcasts conçus pour améliorer l'accessibilité et le référencement. Ce flux de travail simple transforme un enregistrement en une campagne marketing complète et multicanal.
Éducation et recherche académique
Dans le monde universitaire, la clarté et l'accès sont primordiaux. Le logiciel de reconnaissance vocale est un véritable bouleversement pour les étudiants et les enseignants, transformant les conférences orales et les entretiens de recherche en textes consultables et digestes.
Pour les étudiants, une conférence transcrite est un outil d'étude incroyable. Ils peuvent instantanément rechercher des termes ou des concepts spécifiques mentionnés par un professeur sans avoir à parcourir des heures de vidéo. Cela rend la préparation aux examens beaucoup plus efficace et aide les étudiants ayant des styles d'apprentissage différents à se connecter au matériel.
Les chercheurs constatent également des avantages considérables. La transcription d'entretiens qualitatifs était auparavant un travail manuel pénible et lent. La transcription automatisée transforme complètement ce flux de travail, permettant aux chercheurs de passer de la collecte de données à l'analyse en une fraction du temps. Cela permet d'économiser une quantité incroyable de temps et de budget.
Environnements juridiques et d'entreprise
Dans les mondes juridique et des affaires, la précision et la documentation ne sont pas seulement des options souhaitables, elles sont obligatoires. Chaque réunion, déposition, appel client et session de formation à la conformité contient des informations critiques qui doivent être capturées parfaitement.
Se fier à des notes manuelles est une recette pour les erreurs humaines et les détails manqués. Un service de transcription automatisé fournit un enregistrement verbatim, créant une source de vérité unique et fiable.
- Juridique : Les avocats peuvent rapidement parcourir les dépositions et les procédures judiciaires, à la recherche de témoignages spécifiques sans avoir à réécouter des enregistrements entiers.
- Entreprise : Les équipes peuvent générer des comptes rendus de réunion parfaits, indiquant qui a dit quoi, garantissant que tout le monde est aligné sur les actions à entreprendre et les décisions. Cela renforce la responsabilité et crée une archive consultable des connaissances de l'entreprise.
Le rôle croissant dans les soins de santé
Nulle part le besoin d'une documentation précise et sécurisée n'est plus critique que dans les soins de santé. L'industrie de la santé est désormais l'utilisateur à la croissance la plus rapide de la reconnaissance vocale, stimulée par l'essor de la surveillance à distance des patients, des consultations virtuelles et du besoin constant de documentation médicale.
Les cliniciens utilisent des logiciels de reconnaissance vocale pour dicter les notes des patients, les résumés de consultation et les rapports médicaux directement dans les systèmes de dossiers de santé électroniques (DSE). Cela ne fait pas que accélérer la paperasse ; cela réduit la charge administrative des médecins, leur permettant de consacrer plus de temps aux soins des patients.
Compte tenu de la sensibilité de ces données, des fonctionnalités telles qu'une confidentialité des données solide comme le roc et des vocabulaires personnalisés pour le jargon médical sont non négociables. Pour voir comment cela fonctionne en pratique, consultez notre guide sur les flux de travail de transcription médicale et de soins de santé.
Optimisation de votre flux de travail de l'audio à l'actif
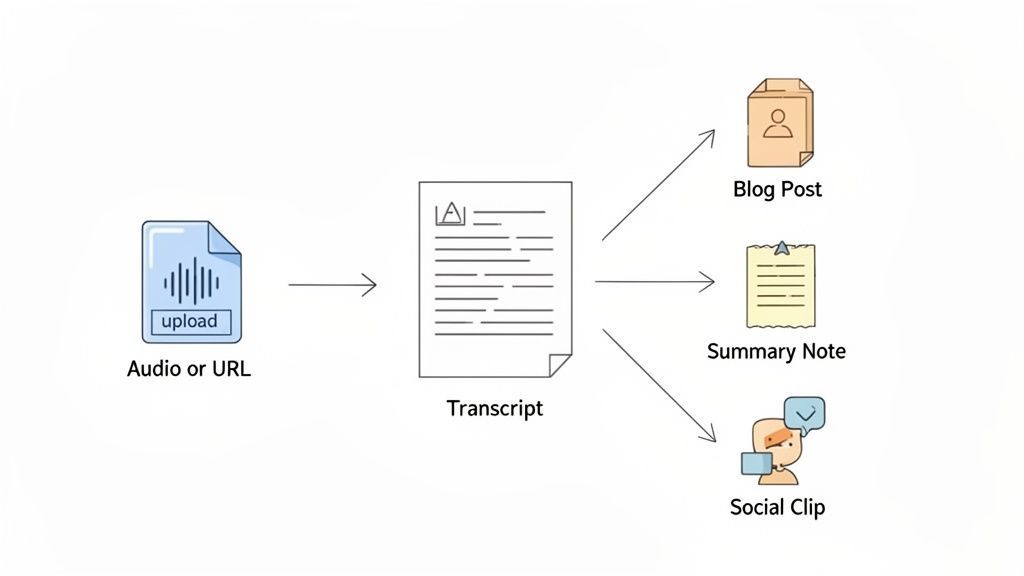
C'est une chose de comprendre les fonctionnalités des logiciels de reconnaissance vocale, mais c'en est une autre de voir comment elles s'articulent pour former un flux de travail fluide et transparent. Un outil moderne fait plus que simplement mettre des mots sur papier ; il transforme le labeur de la transcription en un tremplin pour toutes sortes d'actifs créatifs. Vous ne transcrivez pas seulement ; vous transformez un fichier audio brut en quelque chose de précieux sans presque aucun effort.
Tout commence par une étape simple. Vous pouvez glisser-déposer un fichier depuis votre ordinateur ou connecter des services cloud comme Google Drive et Dropbox. De nombreuses plateformes, y compris Transcript.LOL, vous permettent même de coller une URL depuis YouTube ou Vimeo, et elles récupéreront l'audio pour vous. Cette flexibilité élimine toute difficulté initiale et intègre immédiatement votre contenu dans le système.
En quelques minutes, l'IA fait son travail et renvoie une transcription très précise. C'est là que vous voyez immédiatement la valeur. Au lieu d'un bloc de texte énorme et intimidant, vous obtenez un document propre et structuré avec une identification automatique des locuteurs. Fini le casse-tête pour savoir qui a dit quoi.
Du texte brut au document peaufiné
Une fois cette première ébauche terminée, votre travail passe de la transcription au peaufinage. Les meilleurs outils vous offrent un éditeur intuitif où vous pouvez vérifier le texte tout en écoutant la lecture audio. Il est facile de corriger les petites erreurs, d'attribuer les bons noms de locuteurs et d'ajuster les horodatages pour que tout soit parfaitement synchronisé.
Le véritable gain de temps, cependant, est la fonctionnalité de vocabulaire personnalisé. Avant même de commencer, vous pouvez enseigner à l'IA le jargon spécifique, les noms de produits ou les orthographes inhabituelles qui sont uniques à votre monde. Prendre cette étape initiale signifie que vous n'aurez pas à corriger manuellement des termes comme "cardiopulmonaire" ou un nom de marque comme "AcuTech" encore et encore.
Toute cette première phase est conçue pour la rapidité. Elle est conçue pour vous permettre de passer d'un enregistrement brut à un document peaufiné et précis en une fraction du temps qu'il faudrait pour le faire à la main. L'objectif est simple : passer moins de temps à corriger et plus de temps à créer.
La puissance des outils d'IA post-transcription
Obtenir une excellente transcription n'est que le point de départ. La véritable magie des plateformes modernes réside dans ce que vous pouvez faire après que les mots soient sur la page. Au lieu de simplement exporter un fichier DOCX ou SRT et de considérer que c'est terminé, vous pouvez utiliser des outils d'IA intégrés pour réutiliser instantanément votre contenu.
Imaginez cliquer sur un seul bouton et obtenir :
- Un résumé concis qui condense une réunion d'une heure en ses points clés.
- Un article de blog prêt à être publié, rédigé à partir d'une interview de podcast.
- Une liste claire d'actions extraite d'un brainstorming d'équipe.
- Une poignée de publications engageantes sur les réseaux sociaux, avec des citations et des hashtags.
C'est le grand changement. Le logiciel cesse d'être un simple transcripteur pour devenir un moteur de contenu à part entière, multipliant la valeur de chaque enregistrement que vous effectuez.
Bien sûr, l'ensemble de ce processus doit reposer sur une base de sécurité et de confidentialité solides. Si vous traitez des réunions clients sensibles ou des interviews confidentielles, vous devez utiliser un service qui s'engage à une politique stricte de non-formation. Cela garantit que vos conversations privées ne sont pas utilisées pour former les modèles d'IA d'une autre entreprise. Vos données vous appartiennent, point final.
Quelques questions courantes que nous entendons
Se plonger dans la transcription automatisée soulève de nombreuses questions. C'est une technologie puissante, mais les détails comptent vraiment lorsque vous choisissez le bon outil et que vous déterminez comment l'utiliser efficacement. Nous avons rassemblé certaines des questions les plus courantes sur les logiciels de reconnaissance vocale pour vous donner des réponses claires et directes.
Considérez ceci comme votre guide pour traverser le bruit marketing. Nous aborderons les préoccupations du monde réel concernant la précision, les fonctionnalités et la sécurité afin que vous puissiez faire un choix éclairé.
Quelle est la précision de ces choses, en réalité ?
Les services modernes basés sur l'IA sont devenus incroyablement performants. Dans des conditions idéales – pensez à un enregistrement audio propre avec un seul locuteur et aucun bruit de fond – le meilleur logiciel peut atteindre plus de 95 % de précision. C'est une amélioration massive par rapport aux outils de dictée maladroits du passé, tout cela grâce à des modèles d'IA entraînés sur une quantité incroyable de langage parlé.
Mais le monde réel est désordonné. La précision peut diminuer lorsque vous introduisez des accents forts, des personnes qui se parlent par-dessus, ou simplement un mauvais microphone. Pour les domaines spécialisés comme la médecine ou le droit, où le jargon est omniprésent, l'IA peut se tromper. C'est pourquoi une fonctionnalité de vocabulaire personnalisé est si essentielle pour les professionnels – elle vous permet d'"enseigner" au logiciel des termes uniques, ce qui peut considérablement améliorer sa précision.
Peut-il gérer plus d'un locuteur ?
Oui, absolument. En fait, c'est l'une des fonctionnalités les plus précieuses que vous trouverez dans les outils modernes. La magie derrière cela s'appelle la diarisation des locuteurs. C'est un terme fantaisiste pour un processus simple : l'IA écoute l'audio, détermine qui parle quand, et sépare les voix automatiquement.
Une fois qu'elle détecte un nouveau locuteur, elle étiquette son texte en conséquence (par exemple, "Locuteur 1", "Locuteur 2", etc.). C'est une fonctionnalité indispensable pour quiconque transcrit :
- Des interviews
- Des réunions d'équipe
- Des podcasts avec plusieurs invités
- Des groupes de discussion
- Des dépositions juridiques
Sans cela, vous obtenez juste un mur de texte géant. Vous devriez écouter manuellement et déterminer qui a dit quoi, ce qui est un énorme casse-tête. L'étiquetage automatique des locuteurs permet d'économiser des heures de travail et rend la transcription utile dès le départ.
Quelle est la différence entre une transcription et des sous-titres ?
C'est une confusion courante, mais les deux servent des objectifs complètement différents. Ils proviennent tous deux du même audio, mais ils sont formatés et utilisés de manière totalement différente.
Distinction clé : Une transcription est un document texte destiné à la lecture et à l'analyse. Les sous-titres sont des extraits de texte chronométrés conçus pour apparaître à l'écran en synchronisation avec une vidéo.
Une transcription est le texte complet d'un fichier audio ou vidéo, généralement livré sous forme de document unique (comme un fichier DOCX ou TXT). Les gens l'utilisent pour rechercher des mots-clés, modifier du contenu ou transformer une conversation en article de blog ou en article.
Les sous-titres, en revanche, se présentent sous des formats spéciaux comme SRT ou VTT. Ces fichiers divisent la transcription en petits morceaux chronométrés. Chaque morceau est programmé pour apparaître à l'écran au moment exact où les mots sont prononcés. Leur rôle principal est de rendre les vidéos accessibles aux téléspectateurs sourds ou malentendants et d'attirer l'attention sur les réseaux sociaux, où la plupart des vidéos sont regardées sans le son.
Mes données sont-elles en sécurité lorsque je les télécharge ?
C'est un point important, et la réponse dépend vraiment du fournisseur que vous choisissez. Lorsque vous téléchargez un fichier contenant des informations sensibles – une réunion confidentielle, une consultation de patient, une interview privée – vous accordez une grande confiance à cette entreprise.
Les bons services utilisent un cryptage fort pour protéger vos fichiers pendant leur téléchargement et leur stockage sur leurs serveurs. Mais le plus important est de vérifier la politique de confidentialité de l'entreprise, en particulier ce qu'elle dit sur l'utilisation de vos données pour la formation de modèles d'IA.
De nombreuses plateformes se réservent le droit d'utiliser votre audio et vos transcriptions pour améliorer leur propre IA. Si vous traitez des informations confidentielles, c'est un énorme signal d'alarme. Vous devez absolument trouver un fournisseur avec une politique de non-formation claire et explicite. Cela garantit que vos données privées restent privées et ne sont jamais utilisées à d'autres fins que la génération de votre transcription. Mettez toujours, toujours votre vie privée en premier.
La confidentialité des données n'est pas une option
Toutes les plateformes de transcription ne protègent pas vos données. Certains fournisseurs réutilisent l'audio téléchargé pour entraîner leurs modèles d'IA. Vérifiez toujours une politique claire de non-entraînement avant de télécharger des enregistrements confidentiels ou sensibles.
Prêt à transformer votre audio et votre vidéo en texte précis et exploitable avec une plateforme qui respecte votre vie privée ? Transcript.LOL offre une solution basée sur l'IA avec détection des locuteurs, vocabulaire personnalisé et une politique stricte de non-entraînement pour sécuriser vos données. Découvrez la différence en visitant https://transcript.lol dès aujourd'hui.
Commencez à transcrire plus intelligemment dès aujourd'hui
Transformez l'audio en texte précis, sécurisé et réutilisable grâce à la transcription par IA conçue pour les professionnels.