From Sound to Text Your Guide to Speech to Text Software
Discover how speech to text software transforms audio into valuable content. Learn how it works, what features matter, and how to choose the right tool.
Praveen
February 17, 2025
Speech-to-text software is the magic that turns spoken words from an audio file into plain, usable text. Think of it as your own digital stenographer, ready to listen to recordings, meetings, or voice notes and churn out an editable, searchable document in minutes. It’s a must-have for anyone looking to save a ton of time and make their audio content way more useful.
Unlocking Your Audio: From Sound Waves to Searchable Text
AI Transcription Features
IA de última generación
Impulsado por Whisper de OpenAI para una precisión líder en la industria. Soporte para vocabularios personalizados, archivos de hasta 10 horas y resultados ultra rápidos.

Importar desde múltiples fuentes
Importa archivos de audio y video desde diversas fuentes, incluyendo carga directa, Google Drive, Dropbox, URLs, Zoom y más.

Detección de hablantes
Identifica automáticamente diferentes hablantes en tus grabaciones y etiquétalos con sus nombres.
Imagina esto: acabas de terminar un brillante episodio de podcast de dos horas o una serie de entrevistas profundas con clientes. Ese audio está lleno de oro: ideas valiosas, citas impactantes e ideas innovadoras, pero todo está atrapado dentro de un archivo de sonido. No puedes buscarlo, no puedes citarlo fácilmente y reutilizarlo es una pesadilla. Te quedas mirando una montaña de audio con la desalentadora tarea de escribir cada palabra.
Este es un cuello de botella clásico para creadores, investigadores, especialistas en marketing y estudiantes por igual. Todo ese tiempo dedicado encorvado sobre un teclado, transcribiendo manualmente, podría dedicarse a análisis, a crear contenido nuevo o a la reflexión estratégica real. El software de voz a texto rompe esa barrera, actuando como el puente entre tus palabras habladas y el contenido digital procesable.
Pero esta tecnología ya no se trata solo de escribir por ti; se trata de desbloquear el potencial oculto en tu audio. Transforma tus archivos de audio y video de grabaciones estáticas a activos dinámicos y multipropósito.
- Descubribilidad: Una transcripción hace que tu contenido de audio sea indexable por los motores de búsqueda, ayudando a una audiencia completamente nueva a encontrar tu trabajo.
- Accesibilidad: Ofrece una alternativa de texto para personas sordas o con problemas de audición, ampliando instantáneamente tu alcance.
- Reutilización: Te permite capturar rápidamente citas para redes sociales, convertir entrevistas en publicaciones de blog o crear notas detalladas del programa sin sudar la gota gorda.
La demanda de esto está explotando. El mercado global de API de voz a texto se valoró en 2.200 millones de dólares en 2021 y se prevé que alcance los 5.400 millones de dólares para 2026. Ese increíble crecimiento solo demuestra cuán esencial se ha vuelto la tecnología de voz en casi todas las industrias. Puedes ver el desglose completo en este informe detallado sobre el mercado de API de voz a texto.
En esencia, el proceso es bastante sencillo. Si deseas comprender la mecánica básica, puedes explorar cómo crear una transcripción de cualquier archivo de audio. Las herramientas modernas han hecho esto increíblemente simple, brindándote un documento de alta precisión con casi ningún esfuerzo. La adición de funciones como marcas de tiempo también es un cambio de juego para sincronizar texto con audio, lo que es un salvavidas para editores de video e investigadores. Para ver cómo funciona, consulta nuestra guía sobre cómo obtener una transcripción con código de tiempo para una precisión milimétrica.
Cómo la IA aprende a escuchar y transcribir
¿Alguna vez has usado software de voz a texto? Puede parecer magia. Subes un archivo de audio o empiezas a hablar, y momentos después, aparece una transcripción casi perfecta en tu pantalla. Pero detrás de ese proceso aparentemente simple hay una fascinante colaboración entre diferentes modelos de IA que trabajan juntos para escuchar, comprender y escribir, muy parecido a como lo haría un humano.
Piensa en ello como entrenar a un taquígrafo completamente nuevo. Primero, necesitan aprender a distinguir sonidos individuales. Luego, tienen que reconocer esos sonidos como palabras. Finalmente, deben unir esas palabras en oraciones que realmente tengan sentido. Una IA sigue un camino sorprendentemente similar para lograr su alta precisión.
Todo el proceso comienza en el momento en que el software pone sus manos en tu archivo de audio. Comienza descomponiendo la onda sonora continua de tu voz en miles de unidades de sonido diminutas e individuales. Estos se llaman fonemas, los bloques de construcción más pequeños del lenguaje hablado, como el sonido "c" en "casa" o el sonido "sh" en "shoe".
El Modelo Acústico: Escuchando las Palabras
Una vez que el audio se divide en estos fragmentos de sonido fundamentales, interviene el modelo acústico. Este es el oído de la IA. Ha sido entrenado con una biblioteca masiva de lenguaje hablado, que contiene cientos de miles de horas de audio que han sido meticulosamente emparejadas con sus transcripciones de texto.
Este intenso entrenamiento convierte al modelo acústico en un experto en una cosa: hacer coincidir los fonemas entrantes con las letras y palabras que ya conoce. Analiza las frecuencias y patrones específicos de cada sonido y hace una suposición informada, preguntando: "¿Este pequeño fragmento de sonido coincide con el fonema de 't', 'o' o 'p'?"
Por supuesto, esto rara vez es perfecto por sí solo. Cosas como acentos, ruido de fondo o simplemente hablar muy rápido pueden fácilmente confundir al modelo acústico. El resultado puede ser una mezcla de palabras que suenan bien pero que no tienen ningún sentido. Ahí es donde entra en juego la siguiente capa de IA.
Este diagrama muestra el flujo básico de una onda sonora a un documento de texto final.
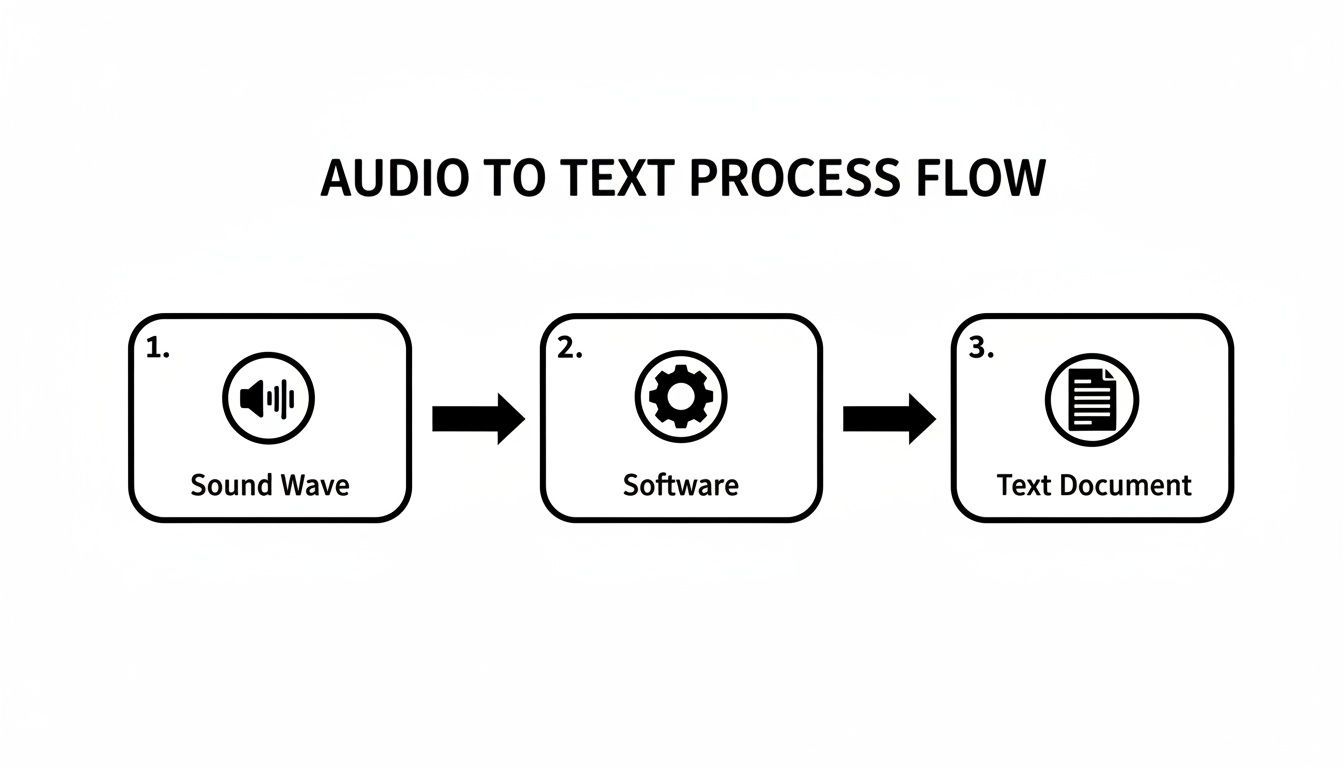
Esta simple conversión está impulsada por complejos modelos de IA que trabajan en tándem para garantizar que el texto final sea preciso y legible.
El Modelo de Lenguaje: Dando Sentido a Todo
Después de que el modelo acústico arroja su borrador, el modelo de lenguaje se encarga. Puedes pensar en esto como el cerebro de la IA o su editor interno. Mientras que el modelo acústico se trata de sonidos, el modelo de lenguaje está obsesionado con el contexto, la gramática y la probabilidad.
Ha sido entrenado con una gigantesca biblioteca de texto (libros, artículos, sitios web, lo que sea), por lo que tiene una profunda comprensión de cómo las palabras deben encajar. Mira la salida tosca del modelo acústico y comienza a hacer algunas preguntas críticas:
- Gramática: ¿Está construida correctamente esta oración?
- Contexto: ¿Esta palabra sigue lógicamente a la anterior?
- Probabilidad: ¿Es más probable que el hablante dijera "grito por helado" o "ojo grito por ojo grito"?
Por ejemplo, un modelo acústico podría escuchar "reconocer voz" y "romper una playa bonita" como casi idénticos. Pero el modelo de lenguaje sabe que "reconocer voz" es una frase mucho más común y lógica, especialmente en el contexto de una transcripción. Corrige este tipo de errores, suaviza las frases torpes e incluso agrega puntuación basándose en las pausas y la entonación del hablante. Este sistema de dos partes es la salsa secreta detrás de cómo la IA de audio a texto logra resultados tan impresionantes.
Why Two Models Matter
Acoustic models focus on sound accuracy, while language models ensure context and readability. Together, they reduce errors caused by accents, homophones, and unclear pronunciation. This layered approach is why modern speech-to-text tools outperform older dictation systems.
Conclusión Clave: La precisión del software de voz a texto proviene de un dúo poderoso. El modelo acústico convierte el sonido crudo en una lista de palabras probables, y el modelo de lenguaje utiliza el contexto y la gramática para convertir esa lista en texto coherente y preciso.
Toda esta colaboración ocurre en una fracción de segundo, convirtiendo un flujo de audio desordenado en un documento limpio y estructurado que está listo para que lo uses.
Eligiendo Tu Kit de Herramientas: Funciones Esenciales y Avanzadas
Elegir el software de voz a texto adecuado es un poco como elegir un coche. Un sedán básico te lleva del punto A al punto B sin problemas. Pero si necesitas transportar equipo pesado, necesitarás un camión especializado.
De la misma manera, casi cualquier herramienta puede convertir audio en palabras, pero las mejores están repletas de funciones diseñadas para manejar flujos de trabajo exigentes y específicos sin sudar. Para elegir la adecuada, necesitas separar lo imprescindible de lo deseable.
Lo No Negociable: Funciones de Transcripción Principales
Antes de que te distraigan los adornos brillantes, debes asegurarte de que el software domina lo básico. Estos son los pilares que hacen que una herramienta sea genuinamente útil en lugar de una fuente de frustración constante.
Piensa en ellos como el motor, las ruedas y la dirección de tu vehículo de transcripción: si te equivocas, no llegarás a ninguna parte.
- Alta Precisión: Esto lo es todo. Una transcripción llena de errores crea más trabajo del que ahorra, dejándote pasar horas corrigiendo. Deberías buscar plataformas que consistentemente alcancen un 95% de precisión o más en audio claro.
- Amplia Compatibilidad de Formatos de Archivo: Tus archivos de audio y video vienen en todas las formas y tamaños. Una buena herramienta debería manejar formatos comunes como MP3, MP4, M4A y WAV sin obligarte a convertir archivos primero.
- Límites Generosos de Archivos: Los proyectos del mundo real a menudo implican contenido de formato largo. Ya sea un podcast de dos horas o una conferencia de todo el día, el software debe manejar archivos grandes y grabaciones largas sin fallar.
Estas tres funciones son la base absoluta para cualquier software de voz a texto efectivo. Son lo que hace que una herramienta sea confiable y lo suficientemente flexible para el trabajo real.
Más Allá de lo Básico: Funciones Avanzadas que Ahorran Tiempo Real
Una vez que una herramienta domina los fundamentos, es hora de mirar las funciones avanzadas. Aquí es donde un buen servicio se convierte en uno excelente, transformando una simple herramienta de transcripción en una verdadera potencia de productividad.
Productivity & Export Features
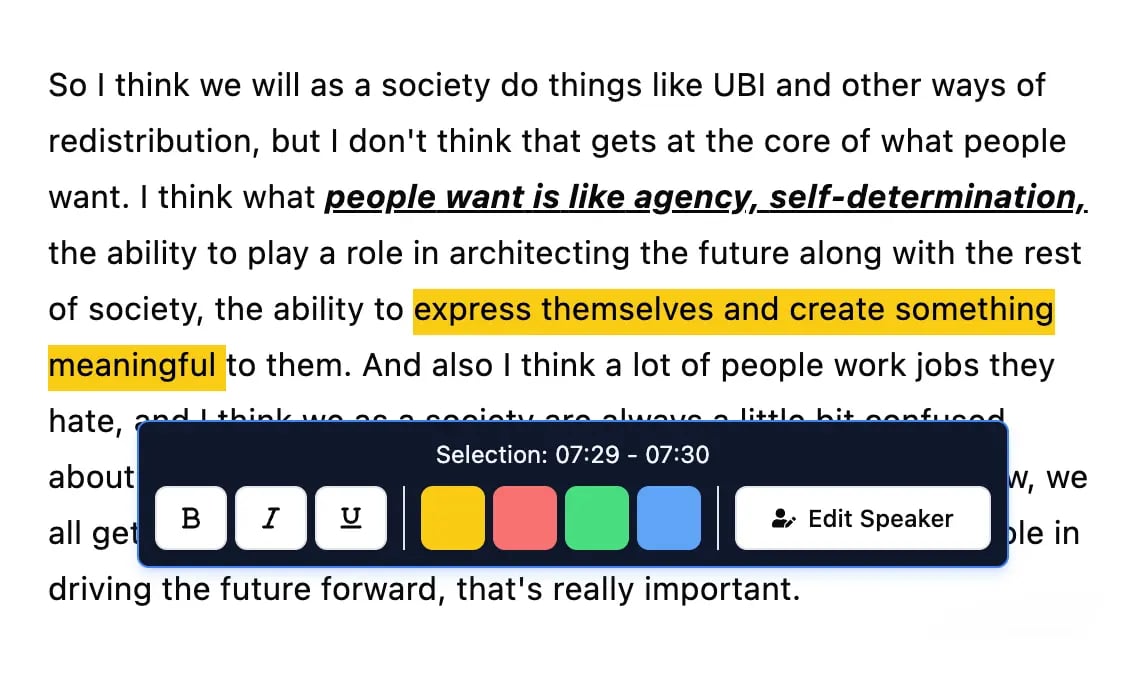
Herramientas de edición
Edita transcripciones con herramientas potentes como buscar y reemplazar, asignación de hablantes, formatos de texto enriquecido y resaltado.
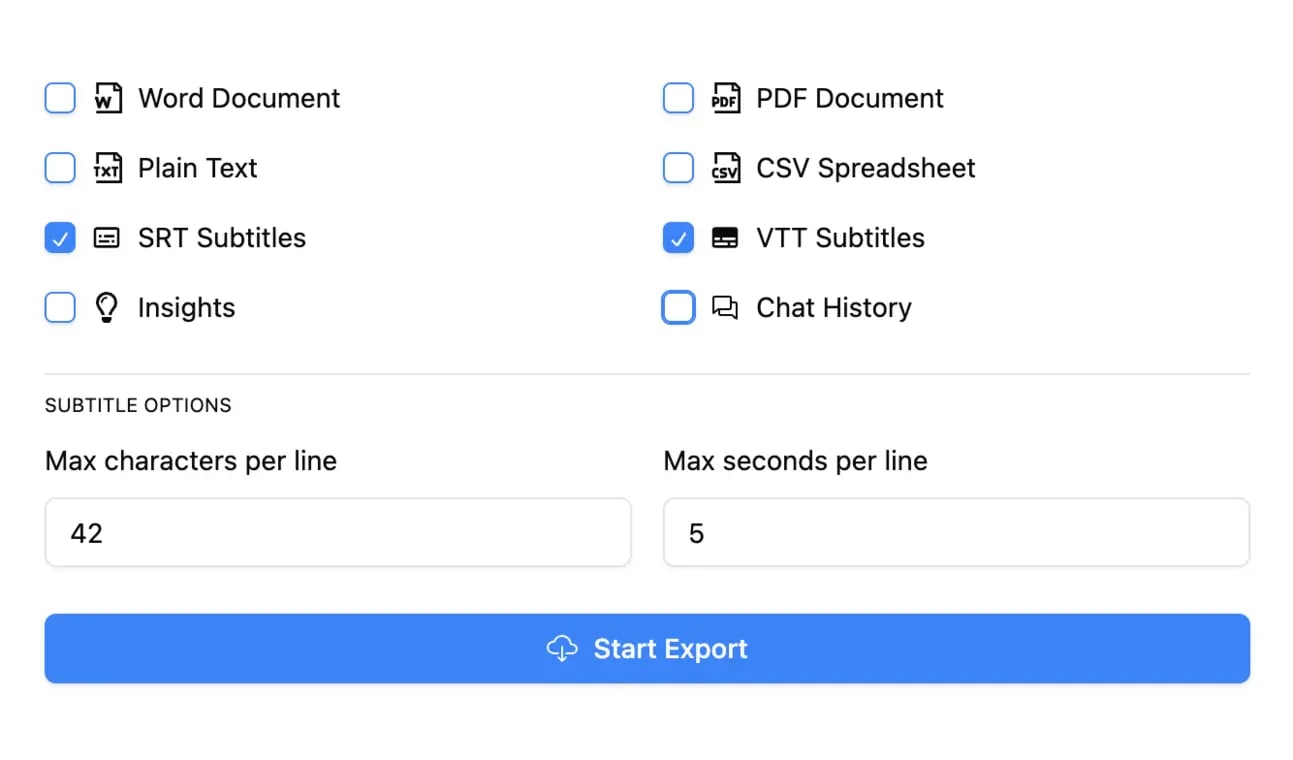
Exportar en múltiples formatos
Exporta tus transcripciones en múltiples formatos incluyendo TXT, DOCX, PDF, SRT y VTT con opciones de formato personalizables.
Resúmenes y Chatbot
Genera resúmenes y otros análisis de tu transcripción, prompts personalizados reutilizables y chatbot para tu contenido.
Estas son el GPS, la tracción en las cuatro ruedas y el espacio de carga adicional de tu software: te ayudan a navegar proyectos complicados, a manejar una carga de trabajo más pesada y a rendir cuando las condiciones se ponen difíciles. Y el mercado para estas herramientas está en auge. El mercado de API de voz a texto se valoró en 2.770 millones de dólares en 2023 y se espera que alcance los 9.860 millones de dólares para 2032, según un reciente informe del mercado de API de voz a texto.
Información Clave: Para los profesionales, las funciones avanzadas no son solo ventajas. Se traducen directamente en tiempo ahorrado, trabajo de mayor calidad y flujos de trabajo más fluidos.
Aquí tienes los factores que cambian el juego y que debes buscar:
- Etiquetado Automático de Hablantes (Diarización): Esto es un salvavidas para cualquier grabación con varias personas: entrevistas, reuniones, grupos focales, lo que sea. El software determina automáticamente quién está hablando y etiqueta el diálogo ("Hablante 1", "Hablante 2"), ahorrándote el tedioso trabajo de hacerlo manualmente.
- Vocabulario Personalizado: Los modelos de IA estándar a menudo tropiezan con la jerga de la industria, los acrónimos de la empresa o los nombres únicos. Una función de vocabulario personalizado te permite "enseñar" a la IA estos términos específicos, lo que aumenta enormemente la precisión para contenido especializado en campos como la medicina, el derecho o la tecnología.
- Integraciones Perfectas: Las mejores herramientas funcionan bien con otras. Busca integraciones con plataformas en las que ya te mueves, como Google Drive, Dropbox o YouTube. Esto crea un flujo de trabajo automático donde tus archivos se transcriben automáticamente, sin necesidad de cargas manuales. Nuestra guía sobre software de transcripción con IA muestra cómo estas conexiones crean un sistema mucho más eficiente.
- Opciones de Exportación Versátiles: Un simple archivo .txt a menudo no es suficiente. Las plataformas de primer nivel te permiten exportar transcripciones en varios formatos, como DOCX para informes, SRT/VTT para subtítulos de video y PDF para compartir fácilmente. Esta flexibilidad hace que tu transcripción sea inmediatamente útil para lo que necesites.
- Política de Privacidad de Datos Robusta: Este es un punto importante. Cuando subes conversaciones confidenciales, necesitas saber que tus datos están seguros. Elige solo un proveedor con una política de privacidad clara que garantice que no utilizará tus datos para entrenar sus modelos de IA. Esta es la única forma de asegurar que tu información confidencial permanezca así.
Para ayudarte a decidir qué es lo adecuado para ti, aquí tienes un resumen rápido de las características esenciales frente a las más avanzadas.
Características Esenciales vs. Avanzadas de Voz a Texto
| Característica | Qué Hace | Quién la Necesita Más |
|---|---|---|
| Alta Precisión | Ofrece una transcripción con errores mínimos, que requiere poca o ninguna corrección. | Todos. Este es el requisito fundamental para cualquier herramienta de transcripción útil. |
| Amplio Soporte de Formatos de Archivo | Acepta archivos de audio y video comunes (MP3, MP4, WAV) sin necesidad de conversión. | Usuarios que trabajan con diversas fuentes multimedia y no quieren la molestia de la preparación de archivos. |
| Límites Generosos de Archivos | Maneja grabaciones largas (por ejemplo, más de 2 horas) y archivos de gran tamaño sin fallar. | Podcasters, investigadores, periodistas y cualquier persona que trabaje con contenido de formato largo. |
| Etiquetado de Hablantes | Identifica y etiqueta automáticamente a los diferentes hablantes en la transcripción (por ejemplo, "Hablante 1"). | Entrevistadores, organizadores de reuniones e investigadores cualitativos que necesitan distinguir entre voces. |
| Vocabulario Personalizado | Te permite agregar términos, nombres o jerga específicos para mejorar la precisión del reconocimiento. | Profesionales en campos técnicos (médico, legal, financiero) donde la precisión es crítica. |
| Integraciones | Se conecta con otras aplicaciones como Google Drive o YouTube para automatizar el flujo de trabajo de transcripción. | Creadores de contenido, especialistas en marketing y equipos que buscan construir pipelines de contenido eficientes y automatizados. |
| Opciones de Exportación Versátiles | Te permite descargar transcripciones en varios formatos (DOCX, SRT, VTT, PDF) para diferentes usos. | Editores de video que necesitan subtítulos, escritores que redactan informes y cualquiera que reutilice contenido en múltiples plataformas. |
| Garantías de Privacidad de Datos | Asegura que tus archivos de audio/video confidenciales no se utilicen para entrenar modelos de IA. | Profesionales legales, terapeutas, equipos corporativos y cualquier persona que maneje información sensible o propietaria. |
En última instancia, la mejor herramienta es la que se adapta a tu flujo de trabajo. Al comprender la diferencia entre las necesidades básicas y los potentes complementos, puedes encontrar una solución que no solo resuelva los problemas de hoy, sino que esté lista para crecer contigo.
Poniendo la Transcripción a Trabajar en Diversas Industrias
Claro, la tecnología detrás de la voz a texto es fascinante, pero donde realmente brilla es en la resolución de problemas cotidianos. No se trata solo de convertir audio en palabras; es un motor de productividad que ahorra incontables horas, desbloquea nuevo contenido y hace que la información sea más accesible en docenas de campos. El impacto es real: convierte horas de tedioso trabajo manual en minutos de acción enfocada y estratégica.
Desde equipos de marketing hasta auditorios universitarios, las aplicaciones son tan diversas como valiosas. Cada industria utiliza la transcripción para abordar sus desafíos únicos, ya sea escalar la producción de contenido, mejorar los resultados de los estudiantes o mantener registros meticulosos para el cumplimiento legal y médico.
How Different Teams Use Speech-to-Text?
Content Creators
Podcasters and YouTubers turn episodes into blogs, captions, and social posts without extra recording time. One file becomes multiple content assets.
Researchers & Academics
Interview transcripts become searchable datasets, speeding up qualitative analysis and reducing research turnaround time.
Corporate Teams
Meeting recordings transform into clear minutes, action items, and knowledge archives that keep teams aligned.
Healthcare Professionals
Doctors dictate notes directly into systems, reducing admin workload while maintaining accurate medical records.
El hilo conductor es siempre la eficiencia. Se trata de liberar a los profesionales para que se centren en tareas de alto valor en lugar de atascarse en la transcripción manual.
Marketing de Contenidos y Producción de Medios
Para cualquier persona en marketing o medios, un solo archivo de audio o video es una mina de oro. Un podcast o seminario web de una hora, una vez transcrito, se convierte en la materia prima para una docena de otras piezas de contenido. Esta estrategia de "crear una vez, distribuir muchas" es el secreto para maximizar tu ROI y llegar a una audiencia mucho más amplia.
Piensa en una sola entrevista de podcast. El audio es genial, pero la transcripción es una navaja suiza de marketing.
- Publicaciones de blog y artículos: La transcripción completa se puede pulir en una publicación de blog completa, salpicada de palabras clave para atraer tráfico de búsqueda orgánica.
- Contenido para redes sociales: Extrae las mejores citas y fragmentos de sonido para crear gráficos llamativos, clips de video cortos y publicaciones concisas para redes sociales.
- Boletines por correo electrónico: Un resumen rápido o una lista de puntos clave para llevar hacen un boletín lleno de valor que mantiene a tu audiencia comprometida.
- Imanes de leads: Formatea la transcripción en un PDF descargable y ofrécelo como un recurso gratuito para capturar nuevos leads.
Aquí es donde las herramientas especializadas son útiles, como las herramientas de transcripción de podcasts diseñadas para mejorar la accesibilidad y el SEO. Este simple flujo de trabajo transforma una grabación en una campaña de marketing completa y multicanal.
Educación e Investigación Académica
En el mundo académico, la claridad y el acceso lo son todo. El software de voz a texto cambia completamente las reglas del juego para estudiantes y educadores por igual, convirtiendo conferencias habladas y entrevistas de investigación en texto buscable y digerible.
Para los estudiantes, una conferencia transcrita es una herramienta de estudio increíble. Pueden buscar instantáneamente términos o conceptos específicos que un profesor mencionó sin tener que revisar horas de video. Hace que la preparación para los exámenes sea mucho más eficiente y ayuda a los estudiantes con diferentes estilos de aprendizaje a conectarse con el material.
Los investigadores también ven enormes beneficios. Transcribir entrevistas cualitativas solía ser un trabajo manual dolorosamente lento. La transcripción automatizada transforma completamente este flujo de trabajo, permitiendo a los investigadores pasar de la recopilación de datos al análisis en una fracción del tiempo. Ahorra una cantidad increíble de tiempo y presupuesto.
Entornos Legales y Corporativos
En los mundos legal y corporativo, la precisión y la documentación no son solo deseables, son obligatorias. Cada reunión, deposición, llamada de cliente y sesión de capacitación de cumplimiento contiene información crítica que debe ser capturada a la perfección.
Confiar en notas manuales es una receta para errores humanos y detalles perdidos. Un servicio de transcripción automatizado proporciona un registro literal, creando una única fuente de verdad confiable.
- Legal: Los abogados pueden escanear rápidamente deposiciones y procedimientos judiciales, buscando testimonios específicos sin tener que volver a escuchar grabaciones completas.
- Corporativo: Los equipos pueden generar actas de reunión perfectas, completas con quién dijo qué, asegurando que todos estén alineados en los puntos de acción y las decisiones. Esto genera responsabilidad y crea un archivo buscable del conocimiento de la empresa.
El Creciente Papel en la Atención Médica
En ningún otro lugar la necesidad de una documentación precisa y segura es más crítica que en la atención médica. La industria de la salud es ahora el usuario de reconocimiento de voz de más rápido crecimiento, impulsado por el auge de la monitorización remota de pacientes, las consultas virtuales y la necesidad constante de documentación médica.
Los médicos utilizan software de voz a texto para dictar notas de pacientes, resúmenes de consultas e informes médicos directamente en los sistemas de registros de salud electrónicos (EHR). Esto no solo acelera el papeleo; reduce la carga administrativa de los médicos, liberándolos para pasar más tiempo cuidando a los pacientes.
Dada la sensibilidad de estos datos, características como una privacidad de datos sólida como una roca y vocabularios personalizados para la jerga médica son innegociables. Para ver cómo funciona esto en la práctica, consulta nuestra guía de flujos de trabajo de transcripción médica y de atención médica.
Optimización de tu Flujo de Trabajo de Audio a Activo
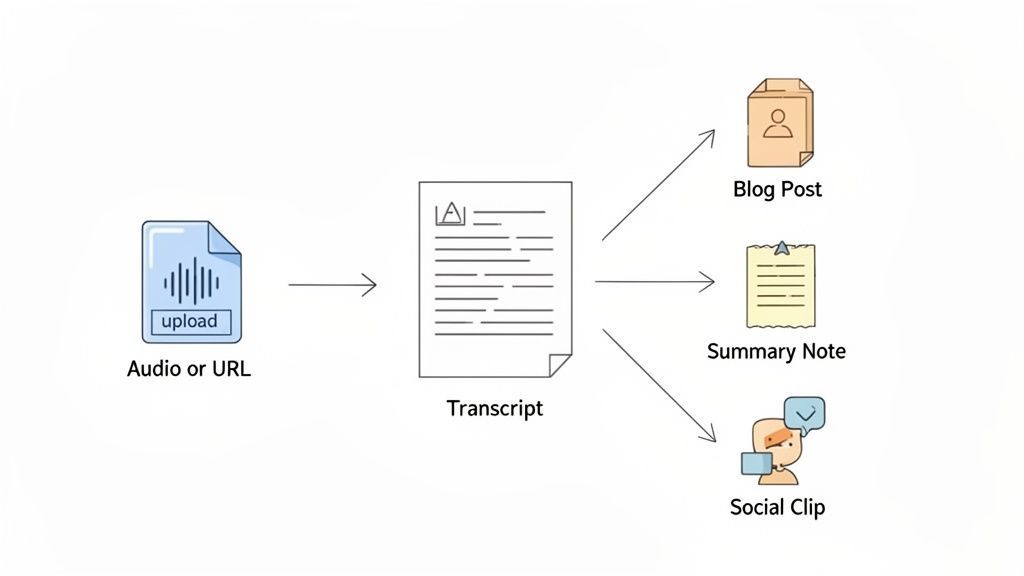
Una cosa es entender las características del software de voz a texto, pero otra es ver cómo encajan en un flujo de trabajo fluido y sin interrupciones. Una herramienta moderna hace más que simplemente poner palabras en una página: convierte la rutina de la transcripción en una plataforma de lanzamiento para todo tipo de activos creativos. No solo estás transcribiendo; estás transformando un archivo de audio en bruto en algo valioso con casi ningún esfuerzo.
Todo comienza con un simple paso. Puedes arrastrar y soltar un archivo desde tu computadora o vincular servicios en la nube como Google Drive y Dropbox. Muchas plataformas, incluida Transcript.LOL, incluso te permiten pegar una URL de YouTube o Vimeo, y ellos obtendrán el audio por ti. Esta flexibilidad elimina cualquier molestia inicial y trae tu contenido al sistema de inmediato.
En solo unos minutos, la IA hace su trabajo y devuelve una transcripción de alta precisión. Aquí es donde inmediatamente ves el valor. En lugar de un bloque de texto gigante e intimidante, obtienes un documento limpio y estructurado con etiquetado automático de hablantes. No más dolores de cabeza tratando de averiguar quién dijo qué.
De Texto en Bruto a Documento Pulido
Una vez que se completa ese borrador inicial, tu trabajo cambia de transcribir a refinar. Las mejores herramientas te brindan un editor intuitivo donde puedes verificar el texto mientras escuchas la reproducción del audio. Facilita la corrección de pequeños errores, la asignación de nombres de hablantes adecuados y el ajuste de marcas de tiempo para que todo esté perfectamente sincronizado.
Sin embargo, el verdadero ahorro de tiempo es la función de vocabulario personalizado. Antes de comenzar, puedes enseñar a la IA jerga específica, nombres de productos o escrituras extrañas que son únicas en tu mundo. Dar este paso inicial significa que no tendrás que corregir manualmente términos como "cardiopulmonar" o un nombre de marca como "AcuTech" una y otra vez.
Toda esta primera fase está diseñada para la velocidad. Está diseñada para que pases de una grabación en bruto a un documento pulido y preciso en una fracción del tiempo que llevaría hacerlo a mano. El objetivo es simple: pasar menos tiempo arreglando cosas y más tiempo creando cosas.
El Poder de las Herramientas de IA Post-Transcripción
Obtener una transcripción excelente es solo el punto de partida. La verdadera magia de las plataformas modernas es lo que puedes hacer después de que las palabras estén en la página. En lugar de simplemente exportar un archivo DOCX o SRT y darlo por terminado, puedes usar herramientas de IA integradas para reutilizar instantáneamente tu contenido.
Imagina hacer clic en un solo botón y obtener:
- Un resumen conciso que reduce una reunión de una hora a sus puntos clave.
- Una publicación de blog lista para publicar redactada a partir de una entrevista de podcast.
- Una lista limpia de puntos de acción extraída de una lluvia de ideas de equipo.
- Un puñado de publicaciones atractivas para redes sociales, completas con citas y hashtags.
Este es el gran cambio. El software deja de ser un simple transcriptor y se convierte en un motor de contenido completo, multiplicando el valor de cada grabación que realizas.
Por supuesto, todo este proceso debe basarse en una base de seguridad y privacidad sólidas. Si estás tratando con reuniones confidenciales de clientes o entrevistas confidenciales, debes usar un servicio que se comprometa con una política estricta de no entrenamiento. Esto garantiza que tus conversaciones privadas no se utilicen para entrenar los modelos de IA de otra empresa. Tus datos son tuyos, punto.
Algunas Preguntas Comunes que Escuchamos
Sumergirse en la transcripción automatizada genera muchas preguntas. Es una tecnología poderosa, pero los detalles realmente importan cuando eliges la herramienta adecuada y descubres cómo usarla de manera efectiva. Hemos reunido algunas de las preguntas más comunes sobre el software de voz a texto para brindarte respuestas claras y directas.
Piensa en esto como tu guía para cortar el ruido del marketing. Abordaremos las preocupaciones del mundo real sobre precisión, características y seguridad para que puedas tomar una decisión segura.
¿Qué Tan Preciso Es Esto, Realmente?
Los servicios modernos impulsados por IA se han vuelto increíblemente buenos. En condiciones ideales —piensa en una grabación de audio limpia con un solo hablante y sin ruido de fondo— el mejor software puede alcanzar más del 95% de precisión. Esa es una mejora masiva con respecto a las torpes herramientas de dictado del pasado, todo gracias a modelos de IA entrenados con cantidades increíbles de lenguaje hablado.
Pero el mundo real es complicado. La precisión puede disminuir cuando intervienen acentos fuertes, personas que hablan al mismo tiempo o simplemente un mal micrófono. Para campos especializados como la medicina o el derecho, donde la jerga está en todas partes, la IA puede tener problemas. Es por eso que una función de vocabulario personalizado es tan crítica para los profesionales: te permite "enseñar" al software términos únicos, lo que puede aumentar drásticamente su precisión.
¿Puede Manejar Más de un Hablante?
Sí, absolutamente. De hecho, esta es una de las características más valiosas que encontrarás en las herramientas modernas. La magia detrás de esto se llama diarización de hablantes. Es un término elegante para un proceso simple: la IA escucha el audio, descubre quién está hablando y cuándo, y separa las voces automáticamente.
Una vez que detecta un nuevo hablante, etiqueta su texto en consecuencia (como "Hablante 1", "Hablante 2", etc.). Esta es una característica imprescindible para cualquiera que transcriba:
- Entrevistas
- Reuniones de equipo
- Podcasts con varios invitados
- Grupos focales
- Deposiciones legales
Sin ella, solo obtienes un muro gigante de texto. Tendrías que escuchar manualmente y averiguar quién dijo qué, lo cual es un gran dolor de cabeza. El etiquetado automático de hablantes ahorra horas de trabajo y hace que la transcripción sea útil de inmediato.
¿Cuál es la Diferencia Entre una Transcripción y los Subtítulos?
Esta es una confusión común, pero los dos sirven para propósitos completamente diferentes. Ambos provienen del mismo audio, pero están formateados y se utilizan de maneras totalmente distintas.
Distinción Clave: Una transcripción es un documento de texto para leer y analizar. Los subtítulos son fragmentos de texto cronometrados diseñados para aparecer en una pantalla sincronizados con un video.
Una transcripción es el texto completo de un archivo de audio o video, que generalmente se entrega como un solo documento (como un archivo DOCX o TXT). Las personas lo utilizan para buscar palabras clave, editar contenido o convertir una conversación en una publicación de blog o artículo.
Los subtítulos, por otro lado, vienen en formatos especiales como SRT o VTT. Estos archivos dividen la transcripción en fragmentos pequeños y codificados por tiempo. Cada fragmento está programado para aparecer en pantalla en el momento exacto en que se dicen las palabras. Su trabajo principal es hacer que los videos sean accesibles para espectadores sordos o con problemas de audición y captar la atención en las redes sociales, donde la mayoría de los videos se ven en silencio.
¿Están Seguros Mis Datos Cuando los Subo?
Este es un punto importante, y la respuesta realmente depende del proveedor que elijas. Cuando subes un archivo con información confidencial —una reunión confidencial, una consulta de paciente, una entrevista privada— estás depositando mucha confianza en esa empresa.
Los buenos servicios utilizan un cifrado sólido para proteger tus archivos mientras se cargan y mientras se almacenan en sus servidores. Pero lo más importante que debes verificar es la política de privacidad de la empresa, especialmente lo que dice sobre el uso de tus datos para el entrenamiento de modelos de IA.
Muchas plataformas se reservan el derecho de usar tu audio y transcripciones para mejorar su propia IA. Si manejas información confidencial, esa es una gran señal de alerta. Absolutamente necesitas encontrar un proveedor con una política de no entrenamiento clara y explícita. Esto garantiza que tus datos privados permanezcan privados y nunca se utilicen para nada más que para generar tu transcripción. Siempre, siempre pon tu privacidad en primer lugar.
Data Privacy Is Not Optional
Not all transcription platforms protect your data. Some providers reuse uploaded audio to train their AI models. Always verify a clear no-training policy before uploading confidential or sensitive recordings.
Ready to turn your audio and video into accurate, actionable text with a platform that respects your privacy? Transcript.LOL offers an AI-powered solution with speaker detection, custom vocabulary, and a strict no-training policy to keep your data secure. Experience the difference by visiting https://transcript.lol today.
Start Transcribing Smarter Today
Turn audio into accurate, secure, and reusable text with AI-powered transcription built for professionals.