Transkriptionssoftware für qualitative Forschung
Entdecken Sie die beste Transkriptionssoftware für qualitative Forschung. Dieser Leitfaden behandelt Genauigkeit, Workflow-Integration und Datenschutz für akademische Zwecke.
Praveen
November 20, 2024
Die Wahl der richtigen Transkriptionssoftware für qualitative Forschung ist mehr als nur ein logistischer Schritt – sie ist das Fundament Ihrer gesamten Analyse. Wenn Sie diese Wahl richtig treffen, erhalten Sie strukturierte, durchsuchbare Texte, die Ihre Erkenntnisse beschleunigen. Wenn Sie sie falsch treffen, stehen Ihnen stundenlange mühsame Korrekturen bevor.
Diese Wahl wirkt sich direkt auf die Integrität Ihrer Daten und die Effizienz Ihres Arbeitsablaufs aus. Es geht darum, Genauigkeit, forschungsspezifische Funktionen und solide Datensicherheit in Einklang zu bringen.
Die richtige Transkriptionssoftware für Ihre Forschung auswählen
Qualitative Forschung lebt von Nuancen. Es sind die subtilen Pausen, die überlappenden Dialoge und der spezifische Jargon, die enthüllen, was wirklich vor sich geht. Ihre Transkriptionssoftware ist nicht nur ein Werkzeug; sie ist ein Partner, der diese Reichhaltigkeit erfasst. Eine schlechte Wahl kann Ungenauigkeiten einführen, die Ihre Ergebnisse verzerren, oder, noch schlimmer, die Vertraulichkeit der Teilnehmer gefährden.
Eines der ersten Dinge, über das Sie entscheiden müssen, ist, ob Sie einen rein automatisierten KI-Dienst oder eine Plattform mit menschlicher Überprüfung (Human-in-the-Loop) wählen möchten. KI hat sich stark weiterentwickelt, aber sie kann immer noch über akademischen Jargon, starke Akzente oder Aufnahmen in einem lauten Café stolpern. Hier bietet die menschliche Komponente eine entscheidende Qualitätskontrolle.
Kernfunktionen, die jeder Forscher benötigt
Wenn Sie sich Transkriptionssoftware für qualitative Forschung ansehen, müssen Sie über einfaches Speech-to-Text hinausdenken. Ihr Ziel ist es, Funktionen zu finden, die den Analyseteil tatsächlich erleichtern.
Hier sind die unverzichtbaren Funktionen:
Wesentliche Transkriptionsfähigkeiten für Forscher
Modernste KI
Angetrieben von OpenAIs Whisper für branchenführende Genauigkeit. Unterstützung für benutzerdefinierte Vokabulare, bis zu 10 Stunden lange Dateien und ultraschnelle Ergebnisse.

Aus mehreren Quellen importieren
Importiere Audio- und Videodateien aus verschiedenen Quellen, einschließlich direktem Upload, Google Drive, Dropbox, URLs, Zoom und mehr.
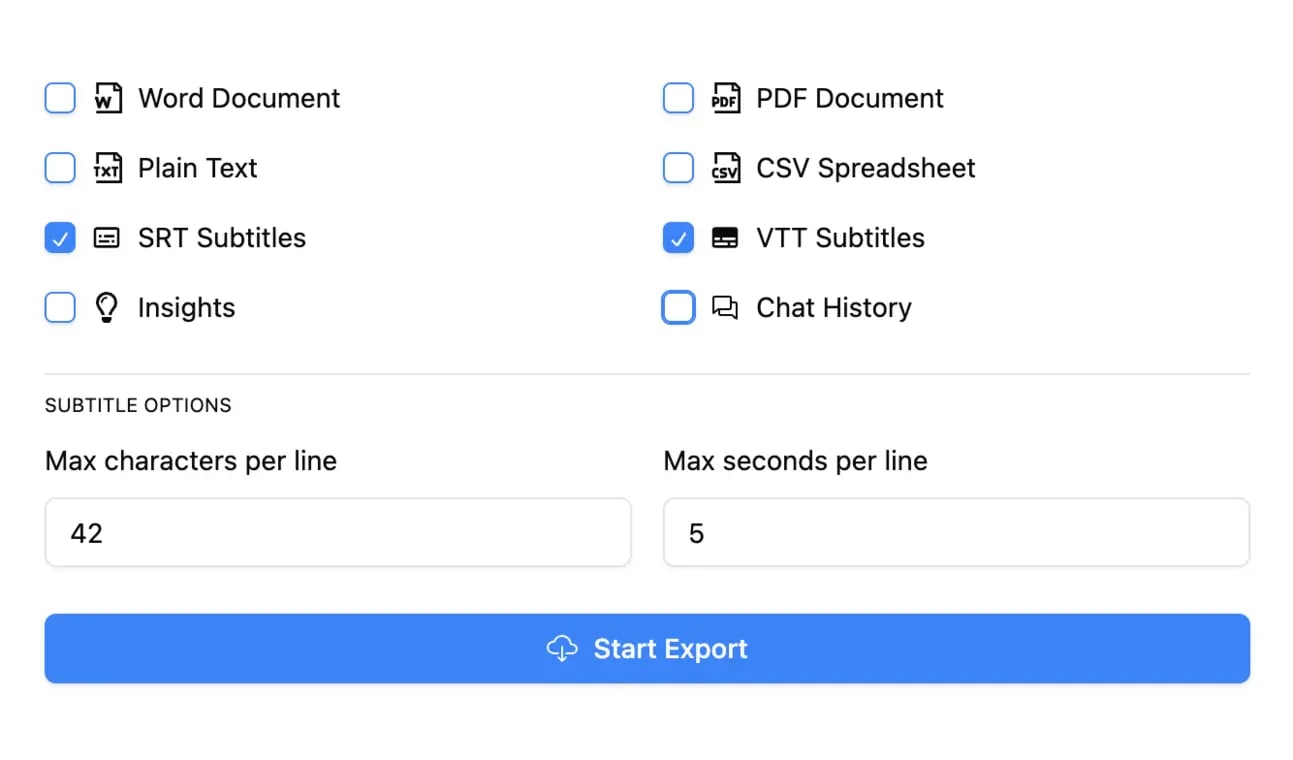
In mehreren Formaten exportieren
Exportiere deine Transkripte in mehreren Formaten, einschließlich TXT, DOCX, PDF, SRT und VTT mit anpassbaren Formatierungsoptionen.
- Hohe Genauigkeit: Das Transkript muss eine getreue Aufzeichnung des Gesprächs sein. Stellen Sie sicher, dass der Dienst Ihre spezifischen Themen und Audiobedingungen bewältigen kann.
- Zuverlässige Sprecherkennzeichnung: Sie müssen unbedingt wissen, wer was gesagt hat, besonders in Fokusgruppen. Die automatische Sprechererkennung spart enorm viel Zeit, muss aber einfach zu bearbeiten sein, wenn die KI Fehler macht.
- Präzise Zeitstempel: Zeitstempel sind Ihre Lebensader und verbinden den Text mit dem Original-Audio. So können Sie schnell den Tonfall eines Teilnehmers wieder aufgreifen oder eine gemurmelte Phrase direkt aus Ihrer Analysesoftware klären. Wir haben einen ganzen Leitfaden über die Bedeutung von Transkriptionen mit Zeitcode geschrieben, wenn Sie tiefer eintauchen möchten.
- Flexible Exportformate: Die Software muss mit Ihrer Software für qualitative Datenanalyse (QDAS) kompatibel sein. Achten Sie auf einfache Exportoptionen wie .docx oder .txt, die Sie direkt in Tools wie NVivo, ATLAS.ti oder Dedoose einfügen können.
Das Ziel ist ein Transkript, das sofort zum Codieren bereit ist, und nicht eines, das komplett umgeschrieben werden muss. Jede Minute, die Sie mit der Korrektur von Formatierungen oder Namen verbringen, ist eine Minute, die Sie nicht mit der Analyse verbringen.
Warum spart forschungsbereite Formatierung Wochen Arbeit?
Saubere Transkripte reduzieren den Einrichtungsaufwand in der qualitativen Analysesoftware. Korrekte Sprecherkennzeichnungen, Zeitstempel und einfache Exportformate ermöglichen sofortiges Kodieren ohne Umstrukturierung von Dateien. Dies beschleunigt dramatisch den Übergang von der Datenerfassung zur Erkenntnisgewinnung.
Wenn Sie bereit sind, verschiedene Plattformen zu bewerten, kann eine einfache Checkliste Ihnen helfen, sich auf das zu konzentrieren, was für die Forschung wirklich wichtig ist.
Kernfunktionen-Checkliste für qualitative Forschungssoftware
| Funktion | Warum sie für Forscher entscheidend ist | Worauf Sie achten sollten |
|---|---|---|
| Hohe Genauigkeit | Müll rein, Müll raus. Ungenaue Transkripte führen zu fehlerhaften Analysen und können Ihre gesamte Studie untergraben. | Genauigkeitsraten von 98 %+; Fähigkeit, Fachjargon, Akzente und Hintergrundgeräusche zu verarbeiten. |
| Sprecherkennzeichnung | Unerlässlich für die Verfolgung von Dialogen in Interviews und Fokusgruppen. Ohne sie können Sie Zitate nicht korrekt zuordnen. | Automatisierte, Mehrsprechererkennung, die leicht bearbeitbar ist. |
| Zeitstempel | Verknüpft Text mit dem Original-Audio zur Überprüfung. Entscheidend für die Überprüfung von Tonfall, Emotionen und Kontext. | Wort- oder absatzweise Zeitstempel, die leicht zu navigieren sind. |
| Mehrere Exportformate | Gewährleistet Kompatibilität mit Ihrer bevorzugten qualitativen Analysesoftware (QDAS). | .docx, .txt und .srt Formate, die sich sauber in Tools wie NVivo oder ATLAS.ti importieren lassen. |
| Datensicherheit & Datenschutz | Ihre Forschung beinhaltet oft sensible Informationen. Der Schutz der Vertraulichkeit der Teilnehmer ist ein Muss. | Klare Datenschutzrichtlinien, Datenverschlüsselung und Einhaltung von Standards wie DSGVO oder HIPAA. |
Diese Checkliste ist nicht erschöpfend, aber sie deckt die Kernfunktionalität ab, die Ihr Projekt entweder zu einem Kinderspiel oder zu einem Albtraum macht.
Wer profitiert am meisten von Transkriptionen in Forschungsqualität?
Akademische Forscher
Wandeln Sie Interviews und Fokusgruppen in strukturierte Datensätze für Kodierung, thematische Analyse und publikationsreife Erkenntnisse um.
Doktoranden & Masterstudenten
Verwandeln Sie aufgezeichnete Betreuungsgespräche und Feldinterviews in organisierte, durchsuchbare Studienmaterialien.
UX- & Marktforscher
Analysieren Sie Kundeninterviews schneller mit sprechergekennzeichneten, zeitgestempelten Transkripten, die für die Journey Mapping bereit sind.
Gesundheits- & Politikanalysten
Verarbeiten Sie sensible Interviews sicher unter Einhaltung strenger Compliance- und Vertraulichkeitsvorschriften.
Es ist keine Überraschung, dass der Markt für diese Tools boomt. Der US-amerikanische Transkriptionsmarkt wurde im Jahr 2024 auf 30,42 Milliarden US-Dollar bewertet und wird voraussichtlich bis 2030 41,93 Milliarden US-Dollar erreichen, wobei KI-gestützte Software die Führung übernimmt. Dieses Wachstum bedeutet mehr Optionen für Forscher, aber es bedeutet auch, dass Sie anspruchsvoller sein müssen.
Letztendlich ist die Wahl Ihrer Software eine strategische Entscheidung. Indem Sie Funktionen priorisieren, die die anspruchsvolle Arbeit der qualitativen Analyse unterstützen, legen Sie den Grundstein für den Erfolg Ihres Projekts vom ersten Tag an.
Entschlüsselung von Genauigkeitsaussagen bei KI-Transkriptionen
In der qualitativen Forschung ist Genauigkeit nicht nur eine Zahl – sie ist das absolute Fundament Ihrer Analyse. Sie ist der Unterschied zwischen der Erfassung der echten Einsicht eines Teilnehmers und der völligen Fehlinterpretation seiner Bedeutung. Es geht darum, die präzise Formulierung, die zögerliche Pause oder das überlappende Geplapper, das voller wertvoller Daten steckt, zu bewahren.
Obwohl KI-Transkriptionstools unglaublich leistungsfähig geworden sind, kann ihr Marketing für Forscher ein Minenfeld sein. Ein Unternehmen kann auf seiner Homepage "95% Genauigkeit" bewerben, aber diese Zahl basiert fast immer auf perfekten Laborbedingungen: ein einzelner, klarer Sprecher ohne Hintergrundgeräusche und ohne komplexe Terminologie.
Qualitative Forschung findet niemals in einer so makellosen Umgebung statt.
Die Genauigkeitslücke in der realen Welt
Seien wir ehrlich, unsere Daten sind unordentlich. Fokusgruppen, ethnografische Feldforschungsnotizen und sogar Einzelinterviews sind voller mehrerer Sprecher, unterschiedlicher Akzente, emotionaler Momente und akademischen Jargons. In diesen realen Szenarien kann die Leistung einer KI drastisch abfallen und die Integrität Ihrer Daten ernsthaft gefährden.
Denken Sie an diese gängigen Situationen, in denen KI oft stolpert:
- Fehlinterpretation von Sarkasmus: Eine KI transkribiert einen sarkastischen Kommentar wörtlich und verpasst den ironischen Ton völlig, wodurch die gesamte Bedeutung der Antwort des Teilnehmers verdreht wird.
- Zusammenführen von Sprechern: In einer schnelllebigen Fokusgruppe kann eine KI leicht verwirrt werden und ein kritisches Zitat der falschen Person zuordnen.
- Ignorieren nonverbaler Hinweise: Eine nachdenkliche Stille (z. B. "[Pause 5s]") oder ein gemeinsames Lachen sind entscheidende kontextbezogene Daten, die automatisierte Systeme fast immer übersehen.
- Verhunzen von Fachbegriffen: Fachbegriffe in Medizin, Recht oder Soziologie werden oft als phonetischer Unsinn transkribiert, den die KI zu hören glaubt, was Sie zwingt, Stunden mit der Bereinigung zu verbringen.
Dies sind keine bloßen Tippfehler; es sind Ereignisse der Datenkorruption. Sie können Sie auf den falschen Weg führen und direkt zu fehlerhaften Schlussfolgerungen. Deshalb müssen Sie über die glänzenden Marketingzahlen hinausblicken und sich der Einschränkungen bewusst werden.
KI-Fehler können Forschungsergebnisse verfälschen
Selbst kleine Transkriptionsfehler können die Bedeutung der Teilnehmer verzerren, falsche Codes einführen und die Forschungsgültigkeit schwächen. Ohne menschliche Überprüfung können KI-generierte Transkripte unbemerkt Verzerrungen und Fehlinformationen in Ihre Analyse einschleusen.
Warum 86 % eine schlechte Note für Forschung sind
Der Sprung von maschineller zu menschlicher Genauigkeit ist kein kleiner Schritt – er ist ein gewaltiger Qualitätsunterschied. Studien zeigen oft, dass KI-Transkriptionen unter typischen, nicht perfekten Bedingungen eine Genauigkeit von etwa 86 % erreichen. Für qualitative Arbeit, bei der jedes einzelne Wort zählt, ist das einfach nicht gut genug.
Vergleichen Sie das mit professionellen menschlichen Dienstleistungen, die eine Genauigkeit von 99,9 % erreichen können. Diese Lücke hat direkte Auswirkungen auf die Gültigkeit Ihrer Analyse.
Eine Genauigkeitsrate von 86 % bedeutet, dass im Durchschnitt 14 von 100 Wörtern falsch sein könnten. Bei einem 30-minütigen Interview (etwa 4.500 Wörter) entspricht dies über 600 potenziellen Fehlern. Die Korrektur eines solchen Fehlerumfangs ist nicht nur mühsam, sondern eine eigene, massive Forschungsaufgabe.
Der gefährlichste Fehler ist nicht der, der offensichtlich ist. Es ist der subtile Fehler, der unbemerkt bleibt, in Ihre Kodierung einfließt und als Tatsache behandelt wird.
Ein hybrider Ansatz zum Schutz Ihrer Arbeit
Das bedeutet nicht, dass KI nutzlos ist. Ganz im Gegenteil. Ein automatisiertes Transkript kann ein fantastischer erster Entwurf sein, besonders wenn Sie ein knappes Budget oder eine knappe Frist haben. Der Schlüssel ist, es genau so zu behandeln – als Entwurf, der eine sorgfältige menschliche Überprüfung erfordert. Dieser hybride Workflow ermöglicht es Ihnen, die Geschwindigkeit der KI zu nutzen, ohne die Integrität Ihrer Daten zu opfern.
Um ein Gefühl dafür zu bekommen, was die Ergebnisse beeinflusst, ist es hilfreich, die Grundlagen zu verstehen, die ein Transkript genau machen. Für eine tiefere Auseinandersetzung lesen Sie unseren Leitfaden dazu, wie die Genauigkeit von Sprache-zu-Text gemessen und verbessert wird.
Wenn Sie Transkriptionssoftware für qualitative Forschung bewerten, muss Ihre Wahl auf Ihrem spezifischen Projekt basieren. Wenn Ihre Audioaufnahmen kristallklar sind und das Thema allgemein ist, kann KI Sie weit bringen. Aber für die überwiegende Mehrheit der qualitativen Projekte – bei denen Nuancen alles sind – ist die Budgetierung von Zeit für eine gründliche menschliche Überprüfung nicht nur eine bewährte Methode. Es ist eine ethische Verpflichtung gegenüber Ihren Teilnehmern und Ihrer Forschung.
Integration von Transkription in Ihren Forschungs-Workflow
Seien wir ehrlich, Transkription wird oft als der mühsame Teil der qualitativen Forschung angesehen – die lästige Pflicht, die Sie erledigen müssen, bevor die eigentliche Analyse beginnt. Aber sie so zu betrachten, ist ein Fehler.
Ihr Transkriptionsprozess ist nicht nur eine Aufgabe; er ist die entscheidende Brücke zwischen Rohaudio und aufschlussreichen Erkenntnissen. Ein umständlicher Workflow verschwendet hier nicht nur Zeit – er kann Fehler einführen und Engpässe schaffen, die Ihr gesamtes Projekt zum Scheitern bringen. Das eigentliche Ziel ist ein nahtloser Fluss von der Aufnahme bis zur Kodierung.
Das alles hängt davon ab, wie gut Ihre Transkriptionssoftware mit Ihrer Qualitative Data Analysis Software (QDAS) zusammenspielt. Die großen Namen wie NVivo, ATLAS.ti und Dedoose sind darauf ausgelegt, strukturierte Texte zu verarbeiten, aber die Qualität des Imports hängt vollständig vom Transkript ab, das Sie ihnen zuführen.
Mehr als nur einfacher Import und Export
Echte Integration ist weit mehr als nur das Einspielen einer Textdatei in Ihre QDAS. Es geht darum, Funktionen in Ihrem Transkriptionstool zu nutzen, um den Kodierungsprozess schneller, genauer und ehrlich gesagt angenehmer zu gestalten.
Hier ist, was für eine reibungslose Übergabe wirklich wichtig ist:
Workflow-Integration & Analysetools

Sprechererkennung
Identifiziere automatisch verschiedene Sprecher in deinen Aufnahmen und beschrifte sie mit ihren Namen.
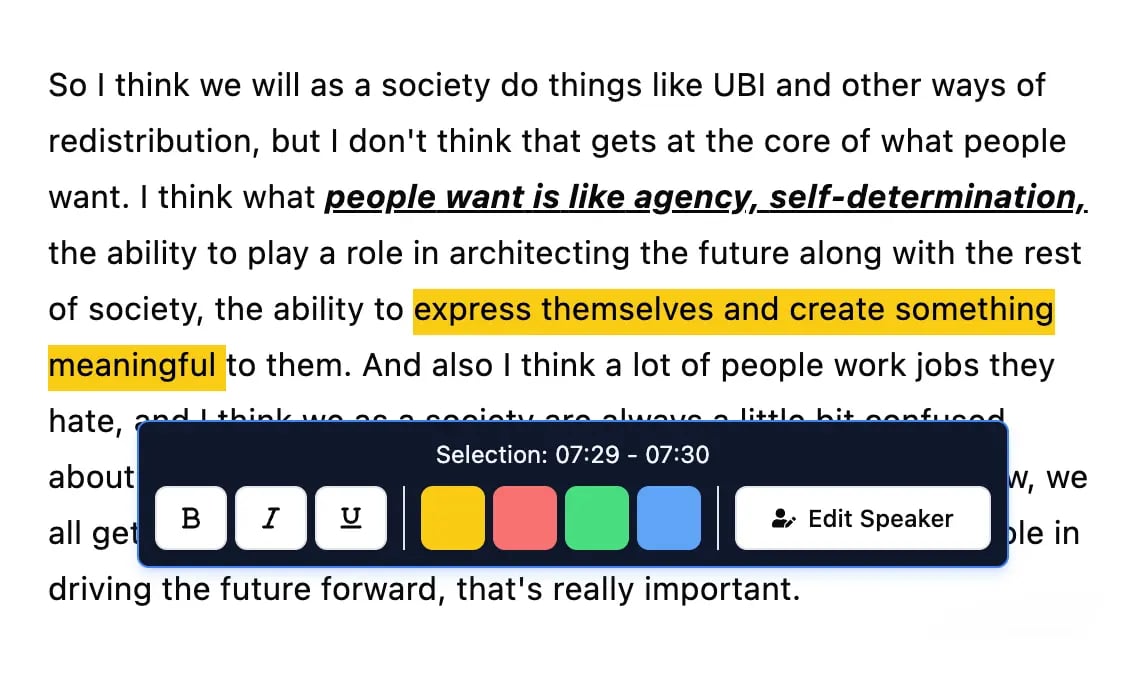
Bearbeitungswerkzeuge
Bearbeite Transkripte mit leistungsstarken Werkzeugen wie Suchen und Ersetzen, Sprecherzuordnung, Rich-Text-Formate und Hervorhebungen.
Zusammenfassungen und Chatbot
Erstelle Zusammenfassungen und andere Erkenntnisse aus deinem Transkript, wiederverwendbare benutzerdefinierte Prompts und Chatbot für deine Inhalte.
Integrationen
Verbinde dich mit deinen bevorzugten Tools und Plattformen, um deinen Transkriptions-Workflow zu optimieren.
- Präzise Zeitstempel: Das ist ein echter Game-Changer. Wenn Zeitstempel in Ihre Transkription eingebettet sind, können Sie auf ein Zitat in Ihrem QDAS klicken und sofort zu diesem genauen Zeitpunkt in der Audioaufnahme springen. Dies ist von unschätzbarem Wert, um den Tonfall eines Teilnehmers zu erfassen, ein gemurmeltes Wort zu klären oder den emotionalen Kontext einer aussagekräftigen Aussage noch einmal zu erleben.
- Klare Sprecherkennzeichnungen: Konsistente, genaue Sprecherkennzeichnungen (wie "Interviewer", "Teilnehmer 1", "Dr. Smith") sind absolut unerlässlich. Wenn Sie dies richtig machen, kann Ihr QDAS Zitate automatisch nach Sprecher sortieren, was es unglaublich einfach macht, Antworten zu vergleichen oder die Geschichte einer Person durch das gesamte Gespräch zu verfolgen.
- Intelligente Exportoptionen: Die besten Tools bieten Exporte, die speziell für die Analyse entwickelt wurden. Sie wünschen sich einfache, saubere Formate wie reinen Text (.txt) oder einfache Word-Dokumente (.docx), die Ihre QDAS-Importtools nicht mit seltsamer Formatierung durcheinanderbringen.
Betrachten Sie Ihre Transkription als einen vororganisierten Datensatz. Je mehr Struktur Sie während der Transkription einbauen – mit klaren Sprechern und Zeitstempeln –, desto weniger mühsame Arbeit müssen Sie während der Analyse leisten.
Diese Infografik zeigt, wie ein solider Workflow für Forschungszwecke aussieht.
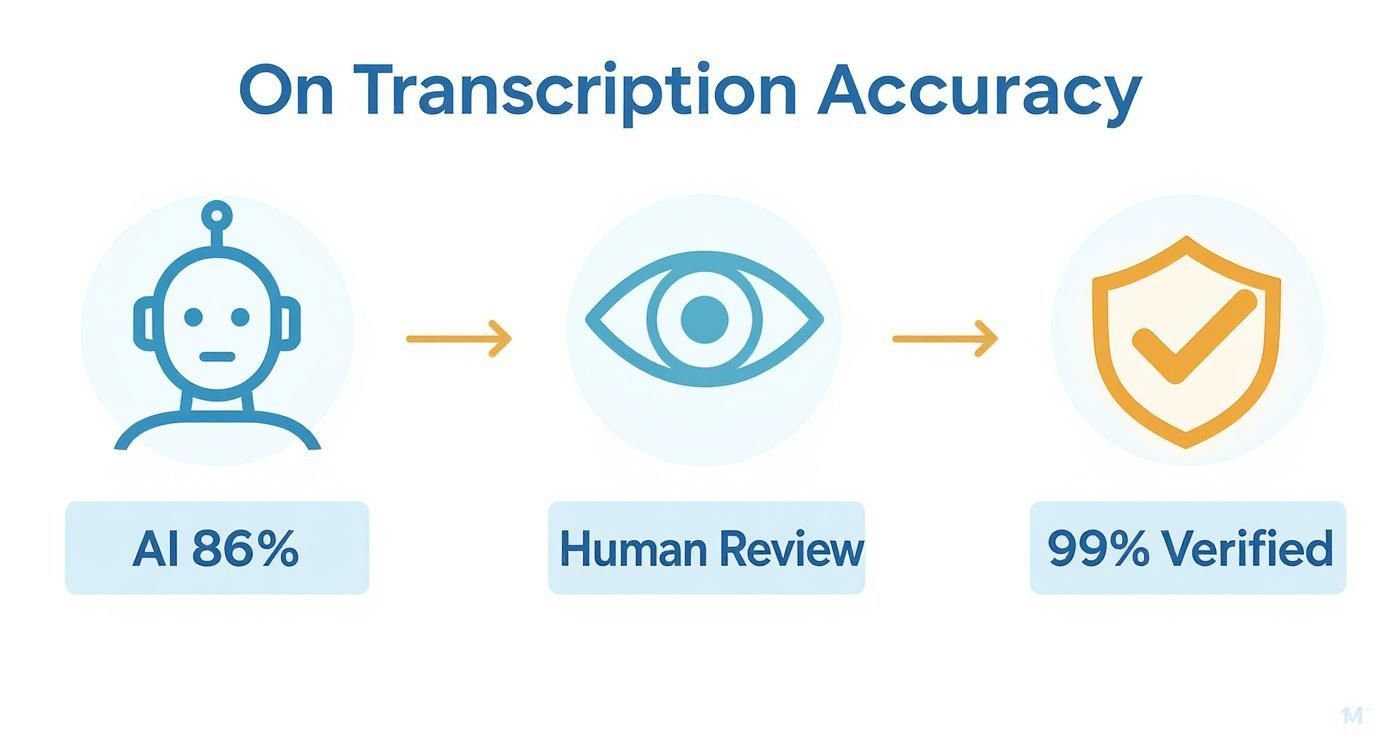
Wie Sie sehen können, beginnt der Prozess mit einem guten KI-Entwurf und verlässt sich dann auf menschliche Überprüfung, um die 99% Genauigkeit zu erreichen – der Standard, der für rigorose akademische und professionelle Forschung erforderlich ist.
Hybrid-KI + menschliche Überprüfung ist der neue Forschungsstandard
Die meisten Universitäten und Ethikkommissionen empfehlen mittlerweile einen hybriden Ansatz: KI für Geschwindigkeit, menschliche Überprüfung für Genauigkeit. Dies gewährleistet sowohl Produktivität als auch vollständige Datenintegrität in der modernen qualitativen Forschung.
Arbeitsabläufe für verschiedene Forschungsszenarien anpassen
Natürlich wird sich Ihr Workflow je nach Ihrer Forschungsmethode ändern. Ein Einzelgespräch ist eine Welt entfernt von einer chaotischen Fokusgruppe.
- Für Tiefeninterviews: Hier liegt der Fokus auf den reichen, nuancierten Details einer einzelnen Person. Wortgenaue Zeitstempel sind eine enorme Hilfe bei der Analyse von Pausen und Zögern. Ein sauberer Export bedeutet, dass Sie das gesamte Dokument in Sekundenschnelle automatisch dem Fall des Teilnehmers in NVivo zuordnen können.
- Für Fokusgruppen: Sprecheridentifikation ist alles. Bevor Sie überhaupt an den Export denken, ist es Ihre oberste Priorität sicherzustellen, dass jeder einzelne Sprecher korrekt und konsistent gekennzeichnet ist. Diese Vorarbeit ermöglicht es Ihrer QDAS, jeden Teilnehmer als einzigartige Quelle zu behandeln, was für den Vergleich von Perspektiven innerhalb der Gruppe unerlässlich ist.
- Für ethnografische Feldforschungsnotizen: Wenn Sie unterwegs Notizen diktieren, kann eine solide KI-Transkription Ihre gesprochenen Gedanken fast augenblicklich in durchsuchbaren Text umwandeln. Von dort aus können Sie den Text in Ihre Analysesoftware importieren und ihn direkt neben Ihren anderen Daten kodieren.
Sobald Ihr Text fertig ist, benötigen Sie effektive Strategien zur Analyse von Interviewdaten, um diese wertvollen Erkenntnisse zu gewinnen. Für eine tiefere Auseinandersetzung mit diesem Teil des Prozesses, lesen Sie unseren Leitfaden wie man Interviewdaten analysiert.
Verbindung mit Software für qualitative Datenanalyse
Wir sind nicht die Einzigen, die sich auf eine bessere Integration konzentrieren. Der globale Markt für Software für qualitative Datenanalyse wurde 2024 auf 1,56 Milliarden US-Dollar bewertet und wird voraussichtlich bis 2033 2,76 Milliarden US-Dollar erreichen. Dieses Wachstum ist auf die steigende Nachfrage nach Tools zurückzuführen, die nahtlos zusammenarbeiten. Lesen Sie die vollständige Marktforschung zu QDAS.
Der Aufbau eines effizienten Forschungs-Workflows bedeutet, Transkription nicht als Endprodukt, sondern als entscheidenden Vorbereitungsschritt zu betrachten. Wenn Sie ein Tool mit starker Integrationsfähigkeit wählen, investieren Sie in einen intelligenteren, schnelleren und rigoroseren Forschungsprozess.
Transkription nach Forschungsmethode
Tiefgehende Interviews
Am besten unterstützt durch Wort-für-Wort-Zeitstempel und saubere Sprecherkennzeichnungen für emotionale und narrative Analysen.
Fokusgruppen
Erfordert hochgenaue Multi-Speaker-Erkennung, um Standpunkte und Interaktionsdynamiken zu vergleichen.
Ethnografische Studien
Die Transkription von Sprachnotizen ermöglicht die schnelle Umwandlung von Feldbeobachtungen in kodierte Daten.
Politik- & Rechtsforschung
Erfordert extreme Genauigkeit, langfristige Datenspeicherung und strenge Sicherheitsprotokolle.
Schutz von Teilnehmerdaten und Vertraulichkeit

Wenn Ihre Arbeit menschliche Subjekte involviert, ist Datensicherheit nicht nur ein technisches Kontrollkästchen – sie ist ein ethischer Eckpfeiler. Jede einzelne Audiodatei, die Sie hochladen, enthält sensible, persönliche Informationen, denen Ihre Teilnehmer Ihnen anvertraut haben. Das Hochladen dieser Dateien in ein nicht geprüfstes Online-Tool kann leicht gegen die Protokolle von Ethikkommissionen (IRB) verstoßen, rechtliche Vereinbarungen brechen und, was am wichtigsten ist, dieses Vertrauen missbrauchen.
Die Verantwortung für den Schutz dieser Daten liegt eindeutig bei Ihnen als Forscher. Die Bequemlichkeit eines schnellen, kostenlosen Dienstes geht oft mit einem hohen, versteckten Preis einher, der normalerweise tief in verschlungenen Nutzungsbedingungen vergraben ist. Die Zusammenarbeit mit einem Transkriptionsanbieter, der die höchsten Standards der Forschungsethik einhält, ist absolut nicht verhandelbar.
Bewertung von Datenschutzrichtlinien und Sicherheitsmaßnahmen
Bevor Sie auch nur ein Byte an Daten hochladen, müssen Sie sich mit dem Lesen von Datenschutzrichtlinien vertraut machen. Ja, sie können dicht sein, aber sie enthalten die entscheidenden Hinweise darauf, wie ein Unternehmen Ihre Forschungsdaten tatsächlich behandeln wird. Überfliegen Sie sie nicht einfach – suchen Sie aktiv nach Antworten auf einige Schlüsselfragen.
Hier ist, wonach Sie suchen sollten:
- Ende-zu-Ende-Verschlüsselung: Dies ist die Basis. Sie stellt sicher, dass Ihre Daten verschlüsselt und unlesbar sind, sobald sie Ihren Computer verlassen, bis sie verarbeitet werden. Achten Sie auf Begriffe wie AES-256-Verschlüsselung, ein Goldstandard für die Datensicherheit.
- Klare Datenhandhabungsprotokolle: Die Richtlinie muss ausdrücklich festlegen, wer auf Ihre Daten zugreifen darf und warum. Vage Formulierungen sind ein massives Warnsignal.
- Einhaltung von Vorschriften: Je nachdem, wo Sie und Ihre Teilnehmer sich befinden, müssen Sie Zusagen zu Standards wie der DSGVO für europäische Daten oder HIPAA für gesundheitsbezogene Informationen sehen.
Ihr Leitprinzip hier ist einfach: Wenn ein Dienst nicht klar erklären kann, wie er Ihre Daten schützt, gehen Sie davon aus, dass er es nicht tut. Vertrauen basiert auf Transparenz, nicht auf Hoffnung.
Ein solides Beispiel dafür, wie dies in der Praxis aussieht, finden Sie in Dokumenten wie der Datenschutzrichtlinie von Parakeet-AI. Dies ist die Art von Dokument, die Ihnen Vertrauen in die Sicherheitsverpflichtung einer Plattform geben muss.
Die versteckten Risiken des KI-Modelltrainings
Eine der größten ethischen Fallen bei der Nutzung moderner Transkriptionssoftware für qualitative Forschung ist die Art und Weise, wie KI-Modelle trainiert werden. Viele Dienste, insbesondere die kostenlosen, schleichen eine Klausel in ihre Bedingungen ein, die ihnen das Recht gibt, Ihre Audioaufnahmen und Transkripte zur Verbesserung ihrer eigenen KI zu verwenden.
Dies ist ein Deal-Breaker für vertrauliche Forschung. Es bedeutet, dass die Geschichten, Meinungen und persönlichen Daten Ihrer Teilnehmer Teil eines permanenten, proprietären Datensatzes werden könnten, der für kommerzielle Zwecke verwendet wird, über die Sie keinerlei Kontrolle haben.
KI-Training mit Forschungsdaten ist ein ethischer Verstoß
Wenn Ihr Transkriptionsanbieter Teilnehmerdaten für das KI-Training verwendet, verstoßen Sie möglicherweise unwissentlich gegen Zustimmungsvereinbarungen, IRB-Bedingungen und internationale Datenschutzgesetze. Fordern Sie immer eine strikte Null-Trainings-Richtlinie.
Sie müssen einen Dienst mit einer ausdrücklichen Null-Trainings-Richtlinie finden. Dies ist ein festes Versprechen, dass Ihre Daten nur zur Generierung Ihrer Transkription verwendet werden – sonst nichts. Sie können beispielsweise sehen, wie eine strenge No-Training-Haltung Ihre Daten in dieser Datenschutzrichtlinie schützt: https://transcript.lol/legal/privacy. Diese Garantie ist der absolute Goldstandard für jede ernsthafte akademische oder professionelle Forschung.
Ein weiterer entscheidender Faktor ist die Datenresidenz – der physische, geografische Standort, an dem Ihre Daten gespeichert werden. Viele Zuschüsse und IRB-Anforderungen schreiben vor, dass Daten in einem bestimmten Land oder einer bestimmten Region (wie der Europäischen Union) verbleiben müssen. Ein vertrauenswürdiger Dienst wird offen darüber informieren, wo sich seine Server befinden, sodass Sie Ihre institutionellen und finanziellen Verpflichtungen ohne Rätselraten erfüllen können.
Ihr erstes Projekt mit Transcript.LOL
Werden wir praktisch. Theorie ist großartig, aber der beste Weg, um zu sehen, wie gut Transkriptionssoftware für qualitative Forschung wirklich etwas verändert, ist, einfach einzusteigen. Ich führe Sie durch ein reales Forschungsprojekt von Anfang bis Ende mit Transcript.LOL, um Ihnen zu zeigen, wie es die üblichen Kopfschmerzen löst.
https://www.youtube.com/embed/eSOssNY9v6A
Stellen Sie sich vor: Sie haben gerade eine 45-minütige Fokusgruppe abgeschlossen. Sie haben drei Teilnehmer und einen Moderator. Die Audiodatei liegt auf Ihrem Desktop, und Sie müssen sie in NVivo zur Kodierung übertragen – ohne eine Woche mit manueller Transkription zu verschwenden.
Von Rohaudio zu einem Arbeitsentwurf
Zuerst müssen Sie Ihre Audiodatei in das System bekommen. Mit Transcript.LOL können Sie die Datei einfach per Drag & Drop von Ihrem Computer ziehen oder sogar aus Cloud-Speichern wie Google Drive abrufen. Sie macht sich sofort an die Arbeit, angetrieben von der Whisper-Engine von OpenAI.
In nur wenigen Minuten haben Sie einen vollständigen ersten Entwurf. Die KI erkennt automatisch, wer spricht, und weist ihnen Bezeichnungen wie „Sprecher 1“, „Sprecher 2“ usw. zu. Dies ist nicht das Endprodukt, aber es ist eine solide Grundlage, auf der Sie aufbauen können.
Die Benutzeroberfläche ist sauber und einfach. Sie platziert den Text direkt neben einem Audioplayer, sodass Sie gleichzeitig hören und lesen können.
Diese Ansicht ist Ihr Kommandozentrum. Sie können die klaren Sprecherwechsel sehen und alle benötigten Bearbeitungswerkzeuge direkt zur Hand haben, was den Überprüfungsprozess erheblich beschleunigt.
Verfeinerung des Transkripts für die Analyse
Hier kommt Ihre Expertise als Forscher ins Spiel. KI ist ein fantastischer Assistent, aber ihr fehlt der Kontext. Ihre erste Aufgabe ist es, diesen generischen Sprecherbezeichnungen Bedeutung zu verleihen. Klicken Sie einfach auf „Sprecher 1“ und benennen Sie ihn in „Moderator“ um, ändern Sie „Sprecher 2“ in „Teilnehmer A“ und so weiter. Das Beste daran? Die Änderung wird automatisch überall angewendet. Keine Alpträume mehr mit Suchen und Ersetzen.
Als Nächstes geht es um Fachbegriffe und Terminologie. Nehmen wir an, Ihre Fokusgruppe diskutierte „hermeneutische Phänomenologie“, aber die KI hörte „hermetisches Phänomen“. Einfache Korrektur. Sie klicken einfach auf den Ausdruck und geben den richtigen Begriff ein.
Eine der mächtigsten Funktionen für Forscher ist der Aufbau eines benutzerdefinierten Vokabulars. Wenn Sie der Software mitteilen, „Phänomenologie“ oder den Namen Ihres leitenden Forschers immer zu erkennen, wird die Genauigkeit bei allen zukünftigen Transkriptionen für dieses Projekt verbessert. Es ist ein kleiner Schritt, der auf lange Sicht viel Bearbeitungszeit spart.
Dies ist auch Ihre Gelegenheit, eine abschließende Qualitätskontrolle durchzuführen. Sie können Absätze zusammenführen, wenn der Gedanke einer Person geteilt wurde, lose Satzzeichen korrigieren und einfach sicherstellen, dass das Transkript den Fluss des ursprünglichen Gesprächs wirklich widerspiegelt. Es ist ein schneller, aber absolut wesentlicher Schritt.
Vorbereitung des Exports für Ihre QDAS
Sobald Sie mit dem Transkript zufrieden sind, ist es an der Zeit, es für Ihre Analysesoftware wie ATLAS.ti oder Dedoose zu exportieren. Hier wird es bei anderen Tools oft unübersichtlich, aber eine für Forscher entwickelte Plattform macht es schmerzfrei.
Anstatt nur eine generische .txt-Datei auszugeben, erhalten Sie Optionen, die für die qualitative Datenanalyse maßgeschneidert sind.
Export-Checkliste für NVivo oder ATLAS.ti:
- Wählen Sie das .docx-Format. Dies ist die zuverlässigste Option für einen sauberen Import, die Ihren Text ohne seltsame Formatierungen beibehält, die Ihre QDAS durcheinanderbringen können.
- Stellen Sie sicher, dass Sprecherbezeichnungen aktiviert sind. Ihr Export muss die korrigierten Namen („Moderator“, „Teilnehmer A“) enthalten, damit Ihre Software sie als verschiedene Personen erkennen kann.
- Fügen Sie Zeitstempel hinzu. Sie können Zeitstempel in festgelegten Intervallen oder nur am Anfang jedes Absatzes hinzufügen. Dies ist das, was den Text in Ihrer Analysesoftware mit dem genauen Moment in der Audiodatei verknüpft.
Mit diesen Einstellungen können Sie einfach die Datei herunterladen. Wenn Sie dieses Dokument in NVivo importieren, erkennt es automatisch die verschiedenen Sprecher und synchronisiert die Zeitstempel. So erhalten Sie ein sauberes, perfekt formatiertes Transkript, das zur Kodierung bereit ist.
Sie sind in einem Bruchteil der Zeit, die manuell erforderlich wäre, von einer Rohdatei zu einer tiefgehenden Analyse gelangt, ohne die Genauigkeit zu beeinträchtigen, die Ihre Forschung erfordert.
Fragen? Wir haben Antworten.
Wenn Sie sich tief in der qualitativen Forschung befinden, kann die Transkription wie ein Minenfeld praktischer und ethischer Fragen erscheinen. Wir verstehen das. Sie benötigen Werkzeuge, die nicht nur genau sind, sondern auch in Ihren Arbeitsablauf passen und Ihre Daten respektieren. Lassen Sie uns einige der häufigsten Fragen angehen, die wir von Forschern hören.
Wie gehe ich mit schlechten Audioaufnahmen um?
Ah, die gefürchtete Aufnahme von schlechter Qualität. Sie ist wahrscheinlich die größte Kopfschmerzursache für jede Transkription, egal ob Sie eine KI oder einen Menschen verwenden. Der beste Weg ist immer die Prävention – ernsthaft, ein externes Mikrofon liefert dramatisch bessere Ergebnisse als das eingebaute Mikrofon Ihres Laptops.
Aber manchmal sind Sie mit dem zufrieden, was Sie haben. Es ist nicht alles verloren.
Bevor Sie überhaupt daran denken, es hochzuladen, versuchen Sie, es mit einem kostenlosen Tool wie Audacity zu bereinigen. Sein Rauschunterdrückungsfilter kann Wunder bei Hintergrundrauschen wirken, und das Verstärkungswerkzeug kann zu leise Stimmen verstärken. Sie werden überrascht sein, wie sehr ein paar einfache Anpassungen helfen können.
Wenn das Audio absolut entscheidend, aber immer noch ein Durcheinander ist, ist dies der Punkt, an dem ein professioneller menschlicher Transkribent seine Leistung wirklich unter Beweis stellt. Sie sind darin geschult, unverständliche Sprache zu entschlüsseln und können oft wichtige Erkenntnisse retten, die ein Algorithmus einfach als [unverständlich] markieren würde.
Kann diese Software verschiedene Sprachen und Akzente verarbeiten?
Die meisten erstklassigen Transkriptionsdienste unterstützen eine Vielzahl von Sprachen, aber die Leistung kann gemischt sein. Überprüfen Sie immer die Liste der unterstützten Sprachen des Anbieters, aber wichtiger ist, dass Sie eine schnelle Testaufnahme mit einer kurzen Audiodatei in Ihrer Zielsprache durchführen, um die reale Genauigkeit selbst zu sehen.
Akzente sind eine ganz andere Sache. Sie sind eine massive Herausforderung für automatisierte Systeme.
Während viele Plattformen mit Standard-amerikanischem oder britischem Englisch besser werden, können starke regionale Dialekte oder Akzente von Nicht-Muttersprachlern die Genauigkeit drastisch reduzieren.
Wenn Ihre Forschung auf der Analyse von Dialekt, Akzent oder sprachlicher Nuance beruht, ist ein menschlicher Transkribent, der auf diesen spezifischen Dialekt spezialisiert ist, fast immer die bessere Wahl. Ein Algorithmus kann die subtilen, aber bedeutungsvollen Details, nach denen Sie suchen, leicht übersehen.
Was ist der beste Weg, Transkripte für die Kodierung zu formatieren?
Das perfekte Format hängt wirklich von Ihrem Analyseplan und der von Ihnen verwendeten Software für qualitative Datenanalyse (QDAS) ab, wie z. B. NVivo oder ATLAS.ti. Für die meisten Projekte gilt jedoch: Weniger ist mehr.
Hier sind einige Best Practices, um sicherzustellen, dass Ihre Transkripte gut mit Ihrer QDAS zusammenarbeiten:
- Saubere Sprecherbezeichnungen: Konsistenz ist alles. Verwenden Sie für jede einzelne Datei dieselben Bezeichnungen – wie „Interviewer“ und „Teilnehmer 1“.
- Häufige Zeitstempel: Das Hinzufügen von Zeitstempeln in regelmäßigen Abständen (sagen wir alle 30-60 Sekunden) oder bei jedem Sprecherwechsel ist eine Rettung. Es ermöglicht Ihnen, auf einen Textteil zu klicken und in Ihrer Analysesoftware sofort zu diesem genauen Zeitpunkt in der Audiodatei zu springen.
- Einfache Exportformate: Bleiben Sie bei den Grundlagen. Der Export als .docx- oder .txt-Datei gewährleistet einen sauberen Import ohne seltsame Formatierungsprobleme, die Ihre Software durcheinanderbringen.
Diese Fähigkeit, Text und Audio zu synchronisieren, ist pures Gold, wenn Sie während des Kodierungsprozesses den Ton eines Teilnehmers überprüfen, den Kontext verifizieren oder herausfinden müssen, was in einer gemurmelten Phrase gesagt wurde.
Lohnt es sich wirklich, für Transkriptionssoftware zu bezahlen?
Die Versuchung des „Kostenlosen“ ist groß, aber für jedes ernsthafte qualitative Projekt ist ein kostenpflichtiger Dienst eine Investition, die sich auszahlt. Kostenlose Tools haben oft versteckte Kosten, die Ihre Forschung ernsthaft beeinträchtigen können.
Hier sind die Probleme, auf die Sie bei kostenlosen Diensten häufig stoßen:
- Geringere Genauigkeit: Sie verwenden ältere, weniger ausgefeilte KI-Modelle, was mehr Fehler und mehr Zeit für manuelle Korrekturen bedeutet.
- Begrenzte Funktionen: Wahrscheinlich finden Sie keine Sprecheridentifizierung, winzige Dateigrößenbeschränkungen und grundlegende Exportoptionen.
- Erhebliche Datenschutzrisiken: Das ist der große Punkt. Viele kostenlose Tools finanzieren sich, indem sie Ihre vertraulichen Daten zum Trainieren ihrer KI verwenden. Für jede Forschung, die menschliche Teilnehmer betrifft, ist dies ein massiver ethischer Verstoß.
Ein seriöser kostenpflichtiger Dienst bietet Ihnen höhere Genauigkeit und unverzichtbare Funktionen, aber auch solide Sicherheit und eine klare Datenschutzrichtlinie. Er spart Ihnen enorm viel Zeit, schützt die Integrität Ihrer Forschung und hilft Ihnen, Ihre ethischen Verpflichtungen zu erfüllen.
Bereit, Ihre Daten in Minuten statt in Tagen analysereif zu machen? Transcript.LOL wurde für Forscher entwickelt. Wir bieten schnelle, genaue und sichere Transkriptionen mit Funktionen wie Sprechererkennung, benutzerdefiniertem Vokabular und flexiblen Exporten. Am wichtigsten ist, dass wir eine strikte Null-Trainings-Richtlinie haben, um die Vertraulichkeit Ihrer Teilnehmer zu schützen.
Beginnen Sie kostenlos mit der Transkription auf Transcript.LOL