Die 12 besten kostenlosen Speech-to-Text-Softwareoptionen im Jahr 2026...
Entdecken Sie die Top 12 kostenlosen Speech-to-Text-Softwaretools für 2026. Vergleichen Sie Funktionen, Genauigkeit und Datenschutz, um die perfekte Lösung für Sie zu finden.
Praveen
January 12, 2026
Von gesprochenen Worten zu digitalem Text: Ihr ultimativer Leitfaden für Speech-to-Text-Software
Das manuelle Transkribieren von Audio- und Videocontent ist eine mühsame und zeitaufwändige Aufgabe. Egal, ob Sie ein Podcaster sind, der Show Notes erstellt, ein Marketer, der Videoinhalte für einen Blog wiederverwendet, oder ein Student, der Vorlesungsdetails festhält – die Umwandlung gesprochener Worte in genauen Text ist ein kritischer Engpass. Die richtige kostenlose Speech-to-Text-Software kann diese Reibung beseitigen, Ihnen Stunden an Arbeit ersparen und neue Potenziale für Ihre Inhalte erschließen. Dieser Leitfaden soll Ihnen helfen, das perfekte Tool für Ihre spezifischen Bedürfnisse zu finden und die besten verfügbaren Optionen zu vergleichen.
Warum ist Speech-to-Text ein Workflow-Upgrade?
Speech-to-Text-Tools ersetzen nicht nur das Tippen – sie verbessern grundlegend, wie Informationen erfasst, wiederverwendet und verteilt werden. Sobald Audio zu Text wird, ist es durchsuchbar, bearbeitbar und sofort wiederverwendbar in Blogs, E-Mails, Berichten und sozialen Medien.
Wir haben eine breite Palette von Lösungen evaluiert, von einfachen, integrierten Diktierfunktionen bis hin zu leistungsstarken, KI-gesteuerten Transkriptionsplattformen. Für jede Option bieten wir eine detaillierte Aufschlüsselung, die wichtige Funktionen, Genauigkeitsstufen, Datenschutzaspekte und ideale Anwendungsfälle abdeckt. Sie finden direkte Links und Screenshots, um zu sehen, wie jede Plattform funktioniert, sowie ehrliche Einschätzungen ihrer Vor- und Nachteile. Wir werden alles untersuchen, von der datenschutzorientierten Genauigkeit von Transcript.LOL über den allgegenwärtigen Komfort der Google Docs-Spracheingabe bis hin zu den Offline-Fähigkeiten von Open-Source-Modellen wie Whispers von OpenAI.
Während wir diese Lösungen untersuchen, ist es wichtig zu erkennen, wie diese KI-gestützten Tools zum breiteren Trend von wie KI die Content-Erstellung für KMUs verändert beitragen. Dieser Wandel macht hochentwickelte Transkriptionstechnologie zugänglicher als je zuvor und ermöglicht es Kreativen und Fachleuten, ihre Arbeitsabläufe erheblich zu optimieren. Diese kuratierte Liste dient als Ihre definitive Ressource und hilft Ihnen bei der Auswahl der effektivsten Software, um Ihre Audiodaten in durchsuchbaren, bearbeitbaren und teilbaren Text umzuwandeln, ohne hohe Kosten oder manuellen Aufwand.
Modernste KI
Angetrieben von OpenAIs Whisper für branchenführende Genauigkeit. Unterstützung für benutzerdefinierte Vokabulare, bis zu 10 Stunden lange Dateien und ultraschnelle Ergebnisse.

Aus mehreren Quellen importieren
Importiere Audio- und Videodateien aus verschiedenen Quellen, einschließlich direktem Upload, Google Drive, Dropbox, URLs, Zoom und mehr.
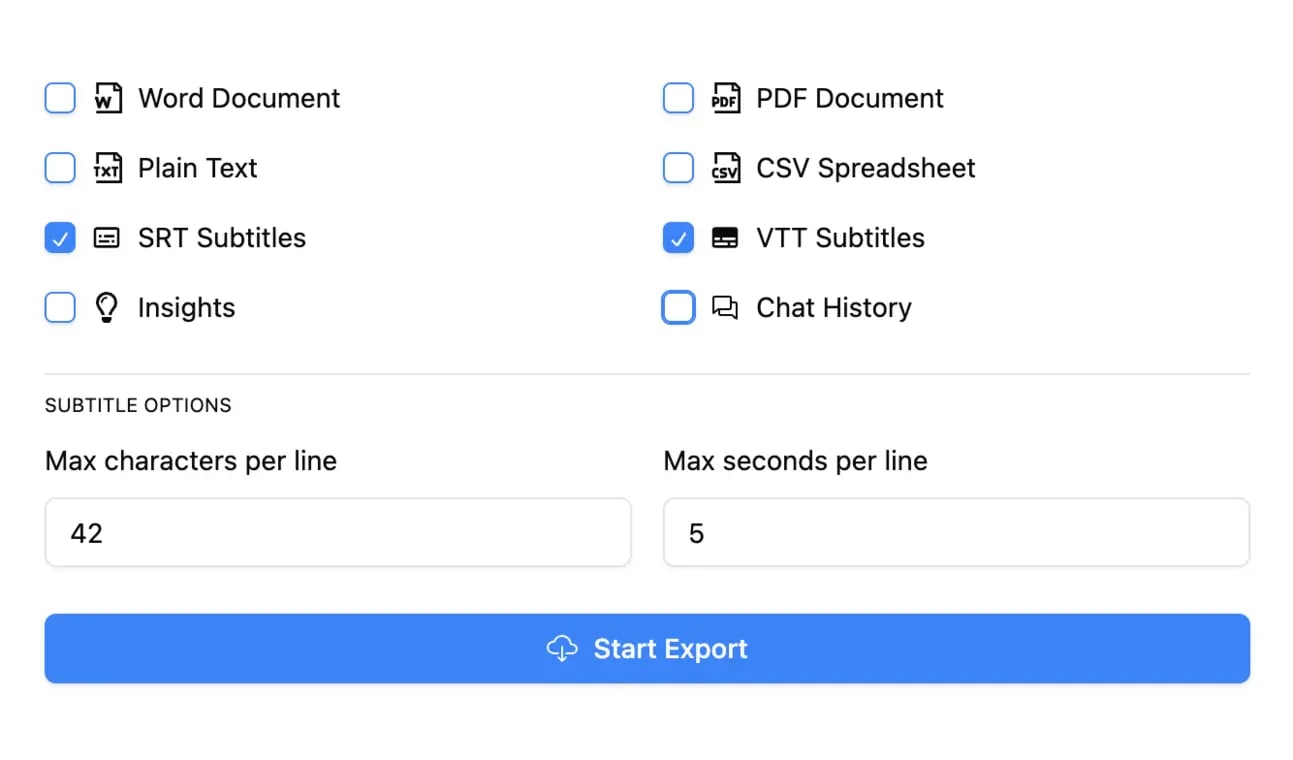
In mehreren Formaten exportieren
Exportiere deine Transkripte in mehreren Formaten, einschließlich TXT, DOCX, PDF, SRT und VTT mit anpassbaren Formatierungsoptionen.
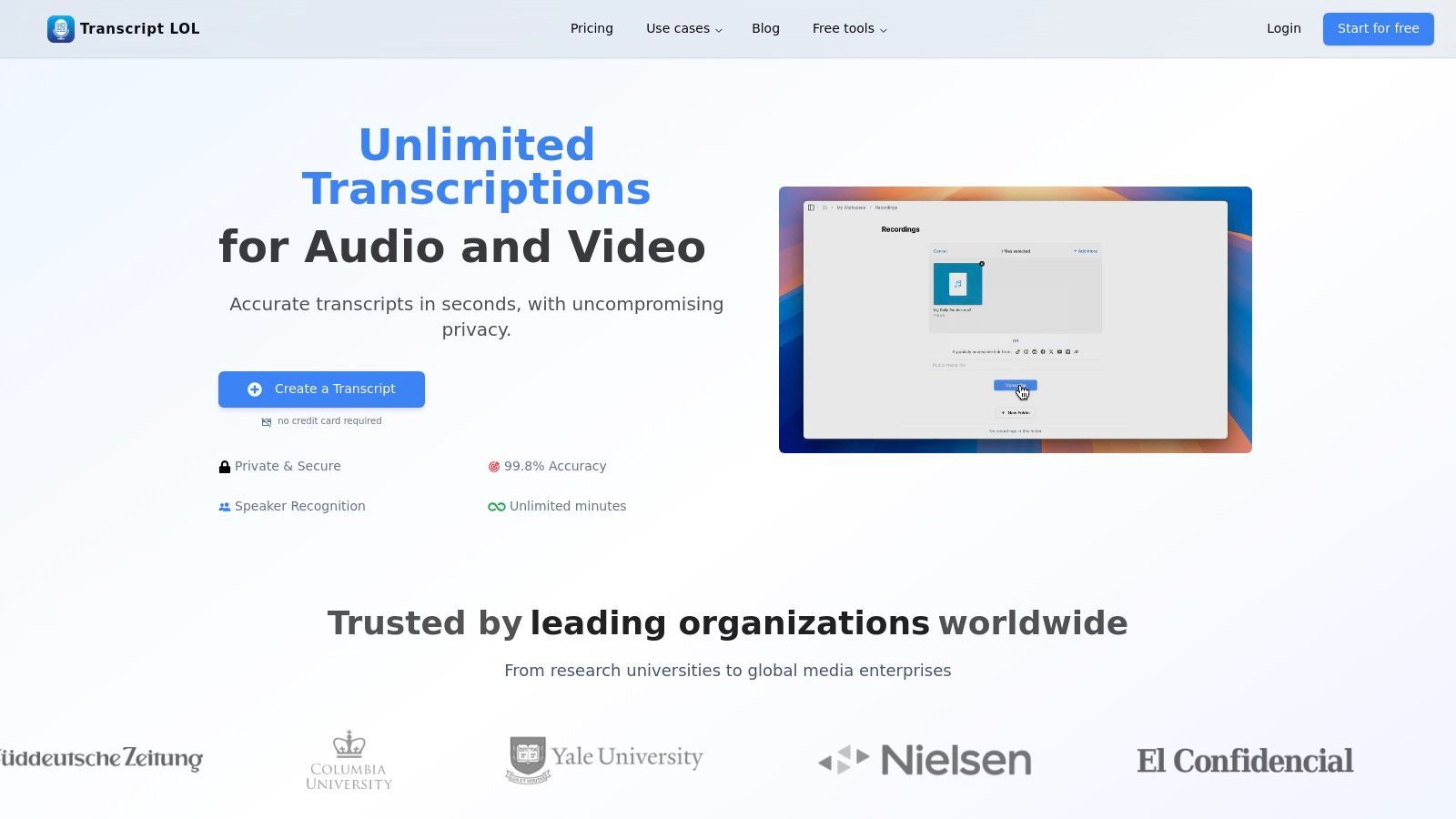
1. Transcript.LOL
Transcript.LOL ist eine erstklassige Wahl für Fachleute, die eine robuste, KI-gesteuerte Transkription suchen, die außergewöhnliche Genauigkeit mit leistungsstarken Tools zur Inhaltserstellung kombiniert. Es ist mehr als nur ein Speech-to-Text-Konverter; es ist eine integrierte Workflow-Plattform, die darauf ausgelegt ist, rohe Audio- und Videodateien in wenigen Minuten in polierte, einsatzbereite Assets umzuwandeln, was es zu einem Top-Anwärter für die beste kostenlose Speech-to-Text-Software macht, die heute verfügbar ist.
Seine Kernstärke liegt in der Nutzung einer fein abgestimmten Version der Whisper-Engine von OpenAI, die eine beworbene Genauigkeitsrate von ~99,8 % liefert. Diese Präzision wird durch die Unterstützung benutzerdefinierter Vokabulare verbessert, die sicherstellt, dass Fachbegriffe, Namen und Branchenjargon korrekt erfasst werden – ein entscheidendes Merkmal für Benutzer in technischen, akademischen oder medizinischen Bereichen.
Hauptunterscheidungsmerkmale und Anwendungsfälle
Was Transcript.LOL wirklich auszeichnet, ist seine umfangreiche Suite von Funktionen nach der Transkription. Über die Bereitstellung eines wortwörtlichen Transkripts hinaus generiert die Plattform automatisch wertvolle Inhalte wie Zusammenfassungen, Aktionspunkte, Quizfragen und sogar Social-Media-Posts. Dies verwandelt das Tool von einem einfachen Dienstprogramm in einen erheblichen Zeitsparer für Vermarkter, Pädagogen und Content-Ersteller.

Sprechererkennung
Identifiziere automatisch verschiedene Sprecher in deinen Aufnahmen und beschrifte sie mit ihren Namen.
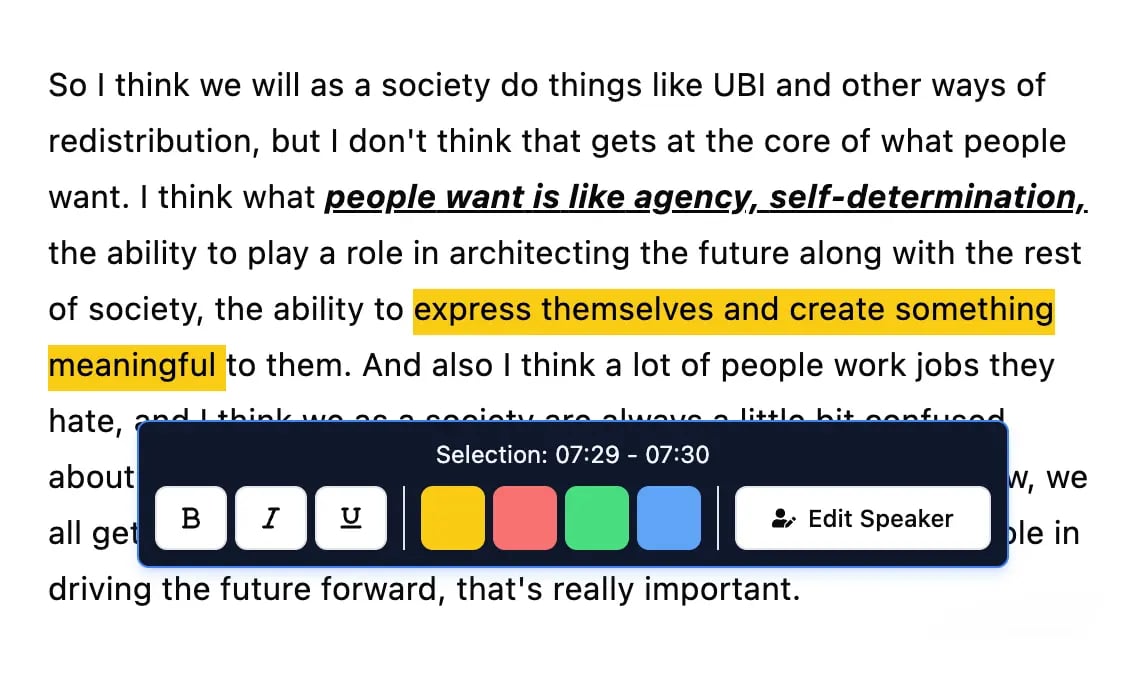
Bearbeitungswerkzeuge
Bearbeite Transkripte mit leistungsstarken Werkzeugen wie Suchen und Ersetzen, Sprecherzuordnung, Rich-Text-Formate und Hervorhebungen.
Zusammenfassungen und Chatbot
Erstelle Zusammenfassungen und andere Erkenntnisse aus deinem Transkript, wiederverwendbare benutzerdefinierte Prompts und Chatbot für deine Inhalte.
- Für Content-Ersteller & Vermarkter: Verwandeln Sie Podcasts oder Webinare schnell in Blogbeiträge, Show Notes und eine Reihe von Social-Media-Updates. Die Möglichkeit, Dateien mit einer Länge von bis zu 10 Stunden zu verarbeiten, macht es ideal für Langform-Inhalte.
- Für Teams & Unternehmen: Die gemeinsamen Arbeitsbereiche, die Ordnerorganisation und die Integrationen (Zoom, Zapier, Google Drive) der Plattform optimieren kollaborative Überprüfungsprozesse. Das Transkribieren von Besprechungsaufzeichnungen und das Generieren von Aktionspunkten wird zu einer automatisierten, effizienten Aufgabe.
- Für Forscher & Studenten: Die hohe Genauigkeit und die Unterstützung für verschiedene Importquellen (einschließlich direkter URLs) machen es perfekt für die zuverlässige Transkription von Vorlesungen, Interviews und Forschungs-Audios.
Datenschutzorientierter Ansatz: Ein wesentlicher Vorteil ist die strikte "No-Training"-Richtlinie von Transcript.LOL. Ihre Daten werden nicht zum Trainieren von KI-Modellen verwendet, ein entscheidendes Engagement für Benutzer, die mit sensiblen oder proprietären Informationen umgehen.
Plattformübersicht
| Merkmal | Details |
|---|---|
| Genauigkeit & Geschwindigkeit | Nutzt OpenAI Whisper mit benutzerdefiniertem Vokabular für nahezu Echtzeit-Ergebnisse mit hoher Präzision. |
| Dateiverarbeitung | Akzeptiert einzelne Uploads bis zu 10 Stunden / 5 GB. Unterstützt verschiedene Formate und direkte Importe von Cloud-Diensten, Zoom und URLs. |
| KI-Content-Tools | Generiert Zusammenfassungen, Quizfragen, Mindmaps, Blogbeiträge, Social-Media-Texte und mehr direkt aus der Transkription. |
| Zusammenarbeit | Bietet gemeinsame Arbeitsbereiche, robuste Suche und Integrationen mit Zapier, WhatsApp, Telegram und wichtigen Cloud-Speicheranbietern. |
| Preise | Kostenlose Stufe: 2 Transkripte/Tag (max. 20 Min. pro Transkript). Unbegrenzter Plan: 120 $/Jahr für unbegrenzte Nutzung, lange Uploads und alle KI-Funktionen. |
| Sicherheit | Erzwingt eine strikte "No-Training"-Richtlinie für Kundendaten und arbeitet mit Subprozessoren zusammen, um die Wiederverwendung von Daten zu verhindern. |
Erste Schritte
- Registrieren: Erstellen Sie ein kostenloses Konto auf der Website.
- Hochladen: Ziehen Sie Ihre Audio-/Videodatei per Drag & Drop oder importieren Sie sie von Google Drive, Zoom, einer URL oder anderen verbundenen Diensten.
- Transkribieren: Die KI verarbeitet die Datei, erkennt automatisch Sprecher und generiert die Transkription.
- Verfeinern & Exportieren: Verwenden Sie den Rich-Text-Editor, um Anpassungen vorzunehmen. Nutzen Sie dann die KI-Tools, um Zusammenfassungen oder andere Inhalte zu erstellen und in Ihrem gewünschten Format (DOCX, SRT, PDF usw.) zu exportieren.
Für einen detaillierteren Vergleich der Funktionen mit anderen Marktoptionen können Sie die Analyse in diesem Leitfaden zu Speech-to-Text-Software einsehen.
Website: https://transcript.lol
2. Google Docs – Spracheingabe
Für Benutzer, die bereits im Google-Ökosystem integriert sind, ist die zugänglichste kostenlose Speech-to-Text-Software wahrscheinlich diejenige, die direkt in die von ihnen täglich genutzten Tools integriert ist. Die Spracheingabe-Funktion von Google Docs ist ein Kraftpaket an Komfort und bietet eine Installation-freie, browserbasierte Diktierfunktion für jeden mit einem Google-Konto und dem Chrome-Browser. Sie eignet sich hervorragend zur Umwandlung gesprochener Wörter in Text in Echtzeit und ist somit ideal für das Erstellen von Dokumenten, das schnelle Notieren oder das Überwinden von Schreibblockaden.
Was die Spracheingabe so effektiv macht, ist ihre Einfachheit und überraschende Genauigkeit bei klarer Diktierfunktion für einzelne Sprecher. Sie unterstützt eine Vielzahl von Sprachen und erkennt sogar grundlegende Formatierungsbefehle wie "neuer Absatz" oder "fett". Während ihr die erweiterten Funktionen dedizierter Transkriptionsdienste wie Sprechererkennung oder Zeitstempel fehlen, liegt ihre Stärke in der reibungslosen Integration in den Workflow eines Autors.
Schneller Einstieg & Anwendungsfall
Um zu beginnen, öffnen Sie einfach ein Google Doc, navigieren Sie zu Tools > Spracheingabe und klicken Sie auf das Mikrofon-Symbol. Dies ist ein perfektes Werkzeug für Studenten, die Aufsätze verfassen, Content-Ersteller, die Drehbücher entwerfen, oder Fachleute, die Besprechungsprotokolle erfassen, während sie geschehen. Es ist ein direktes Live-Diktierwerkzeug, kein Dienst zum Hochladen vorab aufgenommener Audiodateien.
| Funktionsanalyse | Details |
|---|---|
| Hauptfunktion | Live-Diktierfunktion direkt in ein Dokument |
| Zugänglichkeit | Kostenlos mit einem Google-Konto; funktioniert in Chrome |
| Hauptmerkmale | Unterstützung mehrerer Sprachen, grundlegende Sprachbefehle |
| Einschränkungen | Keine Datei-Uploads, keine Sprecher-Diarisierung |
Letztendlich ist das Tool von Google die erste Wahl für die sofortige, unkomplizierte Dokumentenerstellung ohne zusätzliche Software. Für einen tieferen Einblick in die Faktoren, die Transkriptionsergebnisse beeinflussen, können Sie mehr über die Faktoren erfahren, die die Genauigkeit von Speech-to-Text beeinflussen erfahren.
Website: https://docs.google.com
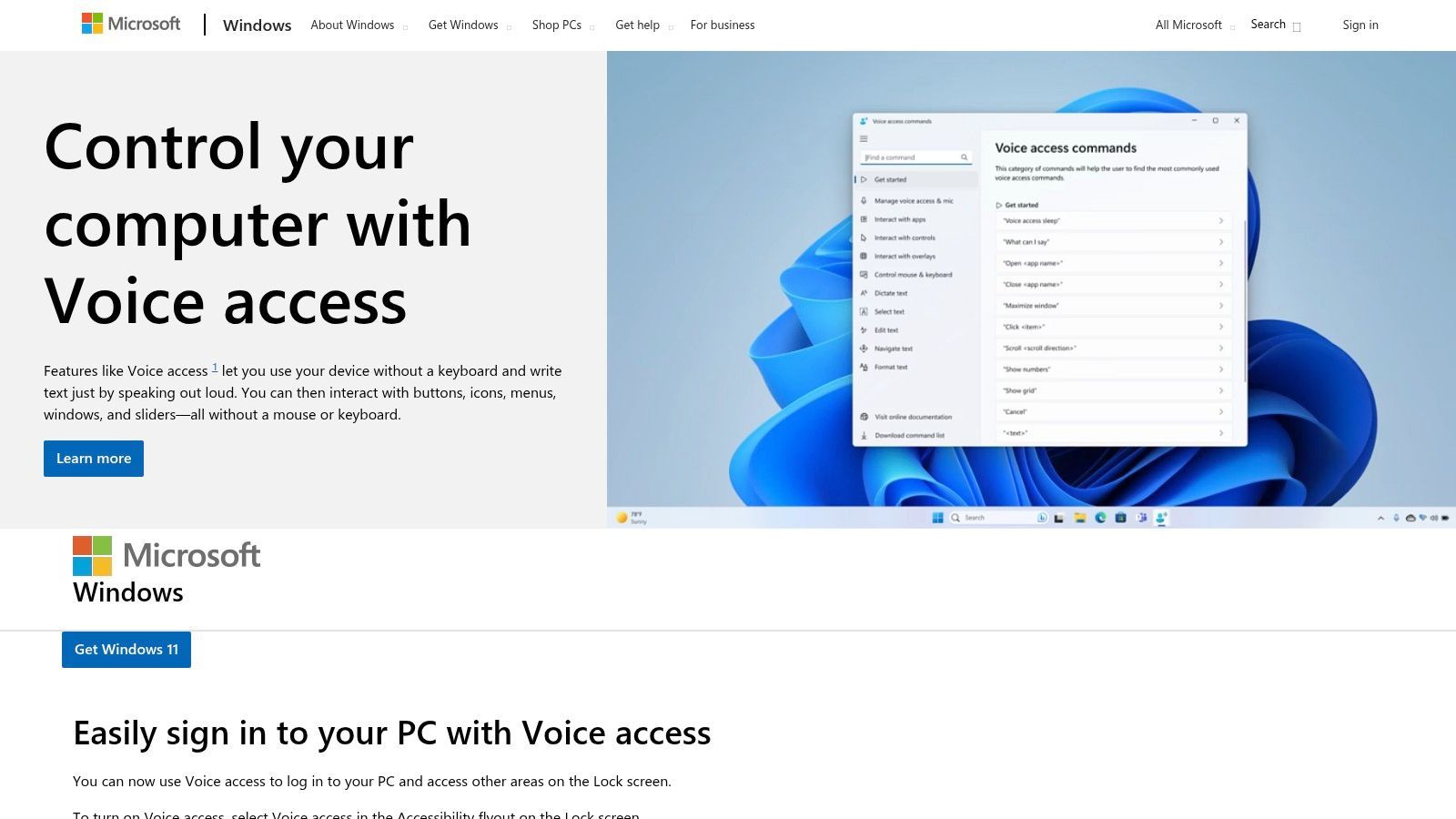
3. Microsoft Windows 11 – Sprachzugriff und Spracheingabe
Für Windows 11-Benutzer ist eine leistungsstarke und datenschutzfreundliche kostenlose Speech-to-Text-Software bereits direkt im Betriebssystem integriert. Sprachzugriff und Spracheingabe in Windows 11 bieten eine robuste, geräteinterne Diktierfunktion, die systemweit funktioniert, von Textverarbeitungsprogrammen bis hin zu Webbrowsern. Diese integrierte Lösung ist hervorragend für Benutzer geeignet, die Offline-Funktionalität priorisieren und ihre Daten lokal halten möchten, da die Spracherkennung auf dem Gerät selbst stattfindet.
Sie bietet flüssige Diktierfunktionen mit automatischer Zeichensetzung und unterstützt Sprachbefehle für Textbearbeitung und Systemnavigation, wie z. B. das Öffnen von Anwendungen oder das Klicken auf Schaltflächen. Dies macht sie zu einem formidable Werkzeug sowohl für die Barrierefreiheit als auch für die allgemeine Produktivität, da Sie Ihren PC steuern und Text verfassen können, ohne die Tastatur zu berühren. Während ihre fortschrittlichsten Funktionen für US-amerikanisches Englisch optimiert sind, bietet sie eine nahtlose Erfahrung, ohne Installationen oder Drittanbieterkonten zu benötigen.
Schneller Einstieg & Anwendungsfall
Um die Spracheingabe zu starten, drücken Sie einfach die Windows-Logo-Taste + H in einem aktiven Textfeld. Für die vollständige Systemsteuerung aktivieren Sie den Sprachzugriff unter Einstellungen > Barrierefreiheit > Sprache. Dies ist eine ideale Lösung für Fachleute, die E-Mails direkt in Outlook verfassen, Studenten, die Notizen in OneNote machen, oder jeden Benutzer, der die Abhängigkeit von seiner Tastatur für alltägliche Computeraufgaben reduzieren möchte.
| Funktionsanalyse | Details |
|---|---|
| Hauptfunktion | Systemweite Live-Diktierfunktion und PC-Steuerung |
| Zugänglichkeit | Kostenlos und in Windows 11 integriert |
| Hauptmerkmale | Geräteinterne Verarbeitung, Offline-Nutzung, Sprachbefehle |
| Einschränkungen | Sprachunterstützung variiert; am besten in US-Englisch |
Letztendlich sind die nativen Tools von Windows 11 die Top-Wahl für Benutzer, die eine integrierte, sichere und offline-fähige Diktierlösung suchen, die über alle ihre Anwendungen hinweg funktioniert.
Website: https://www.microsoft.com/en-us/windows/tips/voice-access
4. Otter.ai
Für diejenigen, die mehr als nur einfache Diktierfunktionen benötigen, positioniert sich Otter.ai als leistungsstarker KI-Besprechungsassistent. Es zeichnet sich als kostenlose Speech-to-Text-Software der Spitzenklasse aus, die speziell für die Transkription von Gesprächen, Besprechungen und Interviews entwickelt wurde. Seine Hauptstärke liegt in der Fähigkeit, mehrere Sprecher zu verarbeiten, zu identifizieren und zu kennzeichnen, wer was in Echtzeit oder aus einer Audiodatei gesagt hat, was es für kollaborative Umgebungen unverzichtbar macht.
Was Otter.ai besonders nützlich für Teams macht, ist die Integration mit Plattformen wie Zoom, Google Meet und Microsoft Teams. Die KI generiert durchsuchbare Notizen, Aktionspunkte und prägnante Zusammenfassungen aus Gesprächen und verwandelt unübersichtliche Diskussionen in organisierte, umsetzbare Aufzeichnungen. Die großzügige kostenlose Stufe bietet eine beträchtliche Anzahl von Transkriptionsminuten pro Monat, wenn auch mit einigen Einschränkungen bei der Importlänge und den Funktionen im Vergleich zu den kostenpflichtigen Plänen.
Schneller Einstieg & Anwendungsfall
Um zu beginnen, melden Sie sich für ein kostenloses Konto an und verbinden Sie es mit Ihrem Kalender, damit der Otter-Assistent automatisch an Ihren virtuellen Besprechungen teilnimmt und diese transkribiert. Sie können auch direkt Gespräche aufzeichnen oder Audiodateien hochladen. Es ist ein perfektes Werkzeug für Projektmanager, die Team-Stand-ups erfassen, Journalisten, die Interviews führen, oder Studenten, die Vorlesungen zur späteren Überprüfung aufzeichnen. Wenn Sie neu in diesem Prozess sind, kann das Verständnis von wie man Audio kostenlos in Text transkribiert eine solide Grundlage bieten.
| Funktionsanalyse | Details |
|---|---|
| Hauptfunktion | Live-Besprechungstranskription und Notizen |
| Zugänglichkeit | Freemium-Modell mit Web- und Mobile-Apps |
| Hauptmerkmale | Sprechererkennung, KI-Zusammenfassungen, Besprechungsintegrationen |
| Einschränkungen | Kostenlose Stufe hat Limits bei Importdauer und monatlichen Minuten |
Letztendlich ist Otter.ai die ideale Wahl für alle, die Erkenntnisse aus Gesprächen mit mehreren Sprechern erfassen, organisieren und teilen müssen und die Lücke zwischen Roh-Audio und strukturierten Notizen schließen.
Website: https://otter.ai
5. Descript
Descript geht über einfache Transkription hinaus und positioniert sich als All-in-One-Audio- und Videoeditor, der von Text angetrieben wird. Für Podcaster, YouTuber und Content-Ersteller ist es ein revolutionäres Werkzeug, das den Transkriptionsprozess direkt mit der Medienbearbeitung verbindet. Anstatt nur eine Transkription bereitzustellen, ermöglicht Descript die Bearbeitung Ihres Videos oder Audios durch einfaches Bearbeiten des Textes, was es zu einer unglaublich intuitiven kostenlosen Speech-to-Text-Software für die Medienproduktion macht.
Was Descript einzigartig macht, ist sein textbasierter Workflow. Das Löschen eines Wortes oder Satzes im Text schneidet es automatisch aus der Audio- oder Videodatei aus, komplett mit nahtlosen Übergängen. Es enthält auch leistungsstarke KI-Funktionen wie das Entfernen von Füllwörtern ("ähm", "äh") mit einem einzigen Klick und eine "Overdub"-Funktion, um einen KI-Klon Ihrer Stimme zu erstellen, um Fehler zu korrigieren. Obwohl seine kostenlose Stufe eher eine Testversion mit begrenzten Transkriptionsstunden ist, bietet sie einen vollständigen Einblick in dieses leistungsstarke Bearbeitungsparadigma.
Schneller Einstieg & Anwendungsfall
Um zu beginnen, melden Sie sich für ein kostenloses Konto an, erstellen Sie ein neues Projekt und ziehen Sie Ihre Audio- oder Videodatei per Drag & Drop hinein. Descript transkribiert sie automatisch und präsentiert Ihnen den textbasierten Editor. Dies ist ideal für Podcaster, die Interviews bereinigen, Vermarkter, die Social-Media-Clips aus Langform-Videos erstellen, oder für Unternehmensteams, die Webinare und Schulungsmaterialien bearbeiten, ohne komplexe Videobearbeitungssoftware zu benötigen.
| Funktionsanalyse | Details |
|---|---|
| Hauptfunktion | Integrierte, textbasierte Audio-/Video-Bearbeitung |
| Zugänglichkeit | Kostenlose Testversion mit begrenzten Stunden; kostenpflichtige Pläne für fortlaufende Nutzung erforderlich |
| Hauptmerkmale | Entfernung von Füllwörtern, KI-Audiobereinigung (Studio Sound), Mehrspur-Bearbeitung |
| Einschränkungen | Kein permanenter kostenloser Plan; kann eine Lernkurve für erweiterte Funktionen haben |
Letztendlich ist Descript die beste Wahl für alle, deren Transkriptionsanforderungen direkt mit der Content-Erstellung und Medienbearbeitung verbunden sind und die einen Workflow bieten, den kein traditioneller Transkriptionsdienst erreichen kann.
Website: https://www.descript.com
6. OpenAI Whisper (Open Source)
Für Entwickler und Benutzer mit technischem Fachwissen stellt Whisper von OpenAI den Höhepunkt der Open-Source-kostenlosen Speech-to-Text-Software dar. Anstatt eines gebrauchsfertigen Webdienstes ist Whisper eine Sammlung leistungsstarker Modelle zur automatischen Spracherkennung (ASR), die Sie auf Ihrer eigenen Hardware ausführen können. Dieser Ansatz bietet unübertroffene Kontrolle über die Privatsphäre und eliminiert laufende Transkriptionskosten pro Minute, da die einzige Ausgabe die erforderliche Rechenleistung ist.
Whisper ist bekannt für seine außergewöhnliche Genauigkeit in einer Vielzahl von Sprachen und seine Fähigkeit, schwierige Audios mit Hintergrundgeräuschen zu verarbeiten. Seine wahre Stärke liegt in seiner Flexibilität; es kann in benutzerdefinierte Anwendungen integriert, für die Stapelverarbeitung großer Mengen von Audiodateien verwendet und sogar direkte Sprach-zu-Englisch-Übersetzungen durchführen. Obwohl es eine technische Einrichtung erfordert, ist der Kompromiss eine professionelle Transkriptions-Engine ohne die wiederkehrenden Gebühren kommerzieller Dienste.
Schneller Einstieg & Anwendungsfall
Der Einstieg beinhaltet die Installation von Python und der Whisper-Bibliothek aus seinem GitHub-Repository. Von dort aus können Sie Transkriptionen über die Befehlszeile auf Ihren lokalen Audiodateien ausführen. Es ist ideal für Forscher, die große Audiodatensätze analysieren, Entwickler, die Transkriptionsfunktionen in ihre Apps integrieren, oder Podcaster, die ihren gesamten Backkatalog privat und kostengünstig stapelweise verarbeiten möchten.
| Funktionsanalyse | Details |
|---|---|
| Hauptfunktion | Hochgenaue Transkription von Audiodateien |
| Zugänglichkeit | Kostenlos und Open Source; erfordert lokale Einrichtung (Python, GPU) |
| Hauptmerkmale | Mehrere Modellgrößen, mehrsprachige Unterstützung, Übersetzung |
| Einschränkungen | Erfordert technische Einrichtung, keine Echtzeit-Diktierfunktion, kann halluzinieren |
Letztendlich ist Whisper die Wahl für diejenigen, die Kontrolle, Datenschutz und Genauigkeit über sofortige Bequemlichkeit stellen. Sie können mehr darüber erfahren, wie Modelle wie dieses in die breitere Landschaft der KI-gestützten Transkriptionssoftware passen.
Website: https://github.com/openai/whisper
7. whisper.cpp (C/C++ Port von Whisper)
Für Entwickler und datenschutzbewusste Benutzer, die eine hochleistungsfähige lokale Transkription suchen, bietet whisper.cpp eine leistungsstarke Alternative zu Cloud-basierten Diensten. Dieses Projekt ist ein C/C++-Port des Whisper-Modells von OpenAI, optimiert für effiziente CPU-Leistung, einschließlich nativer Unterstützung für Apple Silicon. Als Befehlszeilenwerkzeug liefert es eine robuste kostenlose Speech-to-Text-Software-Erfahrung, die vollständig offline funktioniert und sicherstellt, dass keine Daten Ihren Computer verlassen. Es ist die ideale Lösung für die Verarbeitung sensibler Audios, ohne auf externe Server oder Python-Abhängigkeiten angewiesen zu sein.
Was whisper.cpp auszeichnet, ist seine schiere Effizienz und Portabilität. Es läuft ohne einen schweren Software-Stack, was es auf modernen Laptops und Desktops schnell und ressourcenschonend macht. Durch die Verwendung von quantisierten Modellen gleicht es hohe Genauigkeit mit überschaubaren Dateigrößen und Verarbeitungsgeschwindigkeiten aus, was es auch ohne leistungsstarke GPU zugänglich macht. Obwohl seine Befehlszeilenschnittstelle ein gewisses technisches Know-how erfordert, ist der Kompromiss unübertroffene Kontrolle, Datenschutz und Leistung für die Offline-Audio-Transkription.
Schneller Einstieg & Anwendungsfall
Der Einstieg beinhaltet das Klonen des GitHub-Repositorys, das Kompilieren des Codes und das Herunterladen eines vortrainierten Whisper-Modells. Vom Terminal aus führen Sie dann einen einfachen Befehl aus, der auf Ihre Audiodatei verweist. Dieses Werkzeug ist perfekt für Journalisten, die sensible Interviews transkribieren, Forscher, die Feldaufnahmen ohne Internetverbindung verarbeiten, oder Entwickler, die Transkriptionsfunktionen direkt in lokale Anwendungen integrieren.
| Funktionsanalyse | Details |
|---|---|
| Hauptfunktion | Offline, hochleistungsfähige Audio-Datei-Transkription |
| Zugänglichkeit | Kostenlos und Open Source; erfordert Kompilierung |
| Hauptmerkmale | Optimiert für Apple Silicon/AVX, kein Python erforderlich, Modellquantisierung |
| Einschränkungen | Nur Befehlszeile (keine GUI), erfordert manuellen Modell-Download und Einrichtung |
Letztendlich ist whisper.cpp die erste Wahl für Benutzer, die Datenschutz und Leistung priorisieren und sich mit der Arbeit in einer Terminalumgebung wohlfühlen.
Website: https://github.com/ggml-org/whisper.cpp
8. Vosk (Open Source, Offline)
Für Entwickler und datenschutzbewusste Benutzer, die eine vollständige Kontrolle über ihre Daten wünschen, ist Vosk ein leistungsstarkes, offline kostenloses Speech-to-Text-Software-Toolkit. Im Gegensatz zu Cloud-basierten Diensten läuft Vosk vollständig auf Ihrem lokalen Rechner, von einem Desktop-Computer bis zu einem Raspberry Pi. Dies macht es zu einer fantastischen Wahl für die Einbettung von Spracherkennung in Anwendungen, bei denen die Internetverbindung unzuverlässig ist oder Datenschutz oberste Priorität hat.
Sein Hauptvorteil liegt in seinen leichten, effizienten Modellen und der umfassenden Unterstützung für verschiedene Programmiersprachen. Vosk bietet Entwicklern die Bausteine, um benutzerdefinierte sprachaktivierte Anwendungen zu erstellen, von Smart-Home-Assistenten bis hin zu In-Car-Befehlssystemen, ohne Audio an Drittanbieter-Server zu senden. Es bietet ein außergewöhnliches Maß an Flexibilität für Projekte, die eine Offline-Verarbeitung erfordern.
Schneller Einstieg & Anwendungsfall
Der Einstieg beinhaltet die Integration der Vosk-Bibliothek in ein Projekt mit einer Sprache wie Python oder Java. Ein Entwickler würde ein vortrainiertes Sprachmodell herunterladen und dann die Vosk-API für die Echtzeit-Streaming-Erkennung verwenden. Es ist ideal für die Erstellung von Sprachsteuerungsschnittstellen für Desktop-Anwendungen, die Transkription von Audio in einer sicheren Umgebung oder die Erstellung sprachaktivierter Funktionen für eingebettete Systeme. Seine permissive Apache 2.0-Lizenz macht es auch für kommerzielle Zwecke geeignet.
| Funktionsanalyse | Details |
|---|---|
| Hauptfunktion | Offline-Toolkit zur Spracherkennung für Entwickler |
| Zugänglichkeit | Kostenlos und Open Source (Apache 2.0-Lizenz) |
| Hauptmerkmale | Leichte Offline-Modelle, unterstützt über 20 Sprachen, Bindungen für viele Programmiersprachen |
| Einschränkungen | Erfordert Programmierkenntnisse, Genauigkeit kann geringer sein als bei großen Cloud-Modellen, keine gebrauchsfertige GUI |
Letztendlich ist Vosk die erste Wahl für Entwickler, die eine Offline-, anpassbare und lizenzfreie Spracherkennungs-Engine benötigen, die direkt in ihre Software integriert werden kann.
Website: https://github.com/alphacep/vosk-api
9. Amazon Transcribe (AWS)
Für Entwickler und Unternehmen, die eine leistungsstarke, skalierbare Transkriptions-Engine benötigen, bietet Amazon Transcribe eine robuste Lösung innerhalb des Amazon Web Services (AWS)-Ökosystems. Obwohl es sich nicht um eine einfache Verbraucher-App handelt, bietet es eine großzügige kostenlose Speech-to-Text-Software-Stufe, die umfangreiche Tests und kleine Anwendungsfälle ermöglicht. Transcribe zeichnet sich sowohl bei der Echtzeit-Streaming- als auch bei der Stapelverarbeitung von vorab aufgenommenen Audiodateien aus, was es für technische Anwendungen wie Callcenter-Analysen oder die Indizierung von Medieninhalten äußerst vielseitig macht.
Was es auszeichnet, ist seine Suite von Enterprise-Funktionen wie die automatische Schwärzung von persönlich identifizierbaren Informationen (PII), die Erstellung benutzerdefinierter Vokabulare zur Verbesserung der Genauigkeit für spezifische Fachbegriffe und die Sprecher-Diarisierung. Seine kostenlose Stufe, die 12 Monate lang gültig ist, bietet genügend Verarbeitungszeit, um einen Proof-of-Concept zu erstellen und bereitzustellen. Es handelt sich um einen API-first-Dienst, der zur Integration in andere Software konzipiert ist und nicht als eigenständiges Tool verwendet wird.
Schneller Einstieg & Anwendungsfall
Um zu beginnen, erstellen Sie ein AWS-Konto und navigieren Sie zur Amazon Transcribe-Konsole. Sie können einen Transkriptionsauftrag erstellen, indem Sie eine Audiodatei direkt von Ihrem Computer oder einem S3-Bucket hochladen. Dieser Dienst ist ideal für Entwickler, die sprachaktivierte Anwendungen erstellen, Unternehmen, die Kundendienstgespräche zur Qualitätssicherung analysieren, oder Medienunternehmen, die automatisch Untertitel für ihre Videokataloge in großem Maßstab generieren möchten.
| Funktionsanalyse | Details |
|---|---|
| Hauptfunktion | API-gesteuerte Stapel- und Echtzeit-Transkription |
| Zugänglichkeit | Kostenlose Stufe für 12 Monate, danach Pay-as-you-go |
| Hauptmerkmale | PII-Schwärzung, benutzerdefinierte Vokabulare, Sprecher-Diarisierung |
| Einschränkungen | Erfordert AWS-Konto; kann für Nicht-Entwickler komplex sein |
Letztendlich ist Amazon Transcribe das Tor für Benutzer, die industrielle, hochgradig anpassbare Speech-to-Text-Funktionen benötigen, die direkt in ihre eigenen Produkte und Workflows integriert sind.
Website: https://aws.amazon.com/transcribe/
10. Google Cloud Speech‑to‑Text (API)
Für Entwickler und Unternehmen, die eine Engine der Enterprise-Klasse suchen, repräsentiert die Speech-to-Text-API von Google Cloud die leistungsstarke Technologie, die vielen kommerziellen Anwendungen zugrunde liegt. Obwohl es sich nicht um ein Endbenutzer-Tool handelt, bietet es eine großzügige kostenlose Stufe seiner v1-API, was es zu einer praktikablen kostenlosen Speech-to-Text-Software-Option für technische Benutzer macht, die ein Projekt pilotieren oder Transkriptionsaufgaben mit geringem Volumen durchführen. Es bietet Zugriff auf hochmoderne Modelle, die für verschiedene Audioarten optimiert sind, einschließlich Telefonanrufen und Videoinhalten.
Die Plattform zeichnet sich durch ihre leistungsstarken Funktionen wie Sprecher-Diarisierung, Keyword-Boosting und Unterstützung für Mehrkanal-Audio aus, die typischerweise in kostenpflichtigen Diensten zu finden sind. Dies macht sie zu einer starken Wahl für komplexe Transkriptionsanforderungen. Die Nutzung ihrer Funktionen erfordert jedoch ein Google Cloud Platform (GCP)-Konto, eine Abrechnungseinrichtung und etwas technisches Know-how, um mit der API zu interagieren. Die kostenlosen Minuten sind spezifisch für die ältere v1-API, und die Kosten können anfallen, sobald die Nutzung skaliert oder neuere v2-Modelle erforderlich sind.
Schneller Einstieg & Anwendungsfall
Um zu beginnen, richten Sie ein GCP-Projekt ein, aktivieren Sie die Speech-to-Text-API und verwenden Sie eine Client-Bibliothek (wie Python oder Node.js), um Audiodateien zur Transkription zu senden. Dies ist ideal für Entwickler, die Transkriptionsfunktionen in ihre eigenen Anwendungen integrieren, Datenwissenschaftler, die Audiodatensätze analysieren, oder Unternehmen, die automatisierte Transkriptionen für Callcenter-Aufzeichnungen benötigen. Sie eignet sich hervorragend sowohl für Echtzeit-Streaming als auch für die Stapelverarbeitung von vorab aufgenommenen Dateien.
| Funktionsanalyse | Details |
|---|---|
| Hauptfunktion | API für Stapel- und Echtzeit-Audio-Transkription |
| Zugänglichkeit | Kostenlose Stufe verfügbar; erfordert GCP-Konto und Abrechnungseinrichtung |
| Hauptmerkmale | Sprecher-Diarisierung, Keyword-Boosting, spezialisierte Modelle |
| Einschränkungen | Erfordert technische Einrichtung, Kosten können mit der Skalierung steigen |
Letztendlich ist die API von Google Cloud eine Lösung für technische Benutzer, die eine leistungsstarke, skalierbare und hochgenaue Transkriptions-Engine für benutzerdefinierte Projekte benötigen.
Website: https://cloud.google.com/speech-to-text
11. Live Transcribe (Android)
Für Android-Benutzer, die ein sofortiges, auf Barrierefreiheit ausgerichtetes Transkriptionswerkzeug suchen, sticht Googles Live Transcribe als leistungsstarkes kostenloses Speech-to-Text-Software-Tool hervor. Diese App wurde hauptsächlich für die Gehörlosen- und Schwerhörigen-Gemeinschaft entwickelt und bietet Echtzeit-Untertitel für Live-Gespräche, was sie zu einem unverzichtbaren Werkzeug für die persönliche Kommunikation macht. Sie verwandelt das Mikrofon Ihres Telefons in ein hochpräzises, mobiles Transkriptionsgerät.

Was Live Transcribe einzigartig macht, ist sein Fokus auf sofortige Umgebungsbewusstheit. Neben der Transkription gesprochener Wörter in über 70 Sprachen identifiziert es auch Nicht-Sprachgeräusche wie "Hundebellen" oder "Applaus" und liefert so wichtigen Kontext. Obwohl es für Live-Interaktionen konzipiert ist und keine Datei-Uploads unterstützt, bietet seine geräteinterne Verarbeitungsoption eine Privatsphäre-Ebene, die bei Cloud-basierten Diensten nicht immer vorhanden ist. Kontinuierliche Nutzung kann die Akkulaufzeit Ihres Geräts beeinträchtigen. Daher ist das Erlernen von Apps, die den Akku auf Android verbrauchen, verwalten ein praktischer Schritt für Power-User.
Schneller Einstieg & Anwendungsfall
Um zu beginnen, laden Sie Live Transcribe aus dem Google Play Store herunter oder finden Sie es vorinstalliert auf Pixel-Geräten. Öffnen Sie die App, gewähren Sie Mikrofonberechtigungen, und sie beginnt sofort mit der Transkription von Umgebungsgeräuschen. Dies ist perfekt für Studenten in Vorlesungen, Fachleute in spontanen Besprechungen oder jeden, der gesprochene Dialoge in einer lauten Umgebung verstehen muss. Es ist eine außergewöhnliche Hilfsmittel für Barrierefreiheit, kein Werkzeug für die Postproduktion-Transkription.
| Funktionsanalyse | Details |
|---|---|
| Hauptfunktion | Live-Untertitel für persönliche Gespräche |
| Zugänglichkeit | Kostenlos auf den meisten modernen Android-Geräten |
| Hauptmerkmale | Über 70 Sprachen, Geräuschereignis-Labels, Offline-Modus |
| Einschränkungen | Nur Android, keine Datei-Uploads zur Transkription |
Letztendlich ist Live Transcribe hervorragend darin, Kommunikationsbarrieren in Echtzeit abzubauen und bietet eine einfache, aber leistungsstarke Lösung direkt auf dem Gerät, das Sie täglich bei sich tragen.
Website: https://www.android.com/accessibility/live-transcribe/
12. Deepgram
Für Entwickler und Start-ups, die leistungsstarke Transkriptionsfunktionen in ihre eigenen Anwendungen integrieren möchten, bietet Deepgram einen hochentwickelten, API-first-Ansatz. Im Gegensatz zu Endbenutzer-Tools ist Deepgram eine Engine, die für die Erstellung benutzerdefinierter Lösungen entwickelt wurde und großzügige kostenlose Credits im Wert von 200 US-Dollar für neue Benutzer bietet, um seine Fähigkeiten zu erkunden. Diese Plattform wird für ihre Geschwindigkeit, Genauigkeit und fortschrittlichen Funktionen wie Sprecher-Diarisierung, Keyword-Boosting und intelligente Formatierung gefeiert, was sie zu einer erstklassigen Wahl für die Produktion von automatischer Spracherkennung (ASR) macht.
Was Deepgram auszeichnet, ist sein Fokus auf moderne KI-Modelle, wie seine Nova-Serie, die eine hohe Genauigkeit bei verschiedenen Audioqualitäten und Akzenten liefert. Obwohl die Implementierung technisches Wissen erfordert, ist die gebotene Flexibilität unübertroffen für diejenigen, die Transkriptionsdienste testen oder skalieren müssen. Es fungiert als leistungsstarke Infrastruktur und nicht als einfaches, sofort einsatzbereites kostenloses Speech-to-Text-Software-Tool.
Schneller Einstieg & Anwendungsfall
Um zu beginnen, können Entwickler einen kostenlosen API-Schlüssel beantragen und die bereitgestellte Dokumentation verwenden, um vorab aufgenommene Audiodateien zu senden oder eine Echtzeit-Streaming-Verbindung herzustellen. Es ist eine ideale Lösung für Unternehmen, die sprachaktivierte Assistenten entwickeln, Medienunternehmen, die Untertitel generieren, oder Callcenter, die Konversationsdaten analysieren müssen. Die kostenlosen Credits ermöglichen umfangreiche Tests, bevor Sie sich für einen kostenpflichtigen Plan entscheiden.
| Funktionsanalyse | Details |
|---|---|
| Hauptfunktion | API für vorab aufgenommene und Echtzeit-Transkription |
| Zugänglichkeit | Kostenlos mit 200 US-Dollar an Credits; Pay-as-you-go |
| Hauptmerkmale | Sprecher-Diarisierung, Keyword-Boosting, Modellauswahl |
| Einschränkungen | Erfordert Programmierkenntnisse; kein Endbenutzer-Tool |
Letztendlich ist Deepgram die erste Wahl für technische Benutzer, die eine schnelle, genaue und skalierbare Transkriptions-Engine benötigen, um ihre eigenen Software und Produkte zu betreiben.
Website: https://deepgram.com
12 Speech-to-Text Tools im Vergleich
| Produkt | Kernfunktionen ✨ | Genauigkeit & UX ★ | Preis / Wert 💰 | Zielgruppe 👥 |
|---|---|---|---|---|
| Transcript.LOL 🏆 | Whisper-Basis; 10-Stunden-Uploads; Sprecher-Kennzeichnung; Zusammenfassungen, Exporte, Integrationen ✨ | ★4.8 (~99.8%); schneller Editor & Suche | 💰 Kostenlose Stufe; Unbegrenzt 120 $/Jahr; Team 240 $/Jahr — hoher Wert | 👥 Podcaster, Vermarkter, Pädagogen, Rechtsteams |
| Google Docs – Spracheingabe | Browser-Diktierfunktion; grundlegende Sprachbefehle ✨ | ★3–4; am besten für klare Diktierfunktion für einzelne Sprecher | 💰 Kostenlos mit Google-Konto | 👥 Studenten, Autoren, Gelegenheitsnutzer |
| Microsoft Windows 11 – Sprachzugriff | Geräteinterne Diktierfunktion & Systemsteuerung; Offline-Unterstützung ✨ | ★3–4; stark für Barrierefreiheit; benötigt Textfeld | 💰 In Windows 11 enthalten | 👥 Nutzer mit Barrierefreiheitseinschränkungen; Offline-Bevorzuger |
| Otter.ai | Live-Besprechungstranskription; Sprecher-ID; durchsuchbare Notizen; Zusammenfassungen ✨ | ★4; gute Besprechungs-UX; Mehrfachsprecher abhängig vom Audio | 💰 Freemium; kostenpflichtige Stufen für höheres Volumen | 👥 Teams, Besprechungsnotizenschreiber |
| Descript | Textbasierte Audio-/Video-Bearbeitung; Entfernung von Füllwörtern; Mehrspur-Tools ✨ | ★4; exzellenter Editor + Transkriptions-Workflow | 💰 Kostenpflichtige Pläne (kein permanenter kostenloser Plan) — auf Kreative fokussiert | 👥 Podcaster, Kreative, Redakteure |
| OpenAI Whisper (Open Source) | Mehrsprachige ASR; Übersetzung; Python CLI/Bibliothek ✨ | ★4; starke Genauigkeit, erfordert aber Einrichtung & QA | 💰 Kostenloser Code; Rechenkosten fallen an | 👥 Entwickler, Forscher, datenschutzbewusste Benutzer |
| whisper.cpp | CPU-optimierter Whisper-Port; Apple Silicon & quantisierte Modelle ✨ | ★4; schnelle lokale CPU-Inferenz (CLI) | 💰 Kostenlos; Kosten für lokale Ressourcen & Speicher | 👥 Entwickler, Offline-/Apple-Silicon-Benutzer |
| Vosk (Open Source) | Kleine Offline-Modelle; Mehrsprachig; viele Sprachbindungen ✨ | ★3–4; leichtgewichtig, Genauigkeit variiert je nach Modell | 💰 Kostenlos; Apache-2.0-Lizenz | 👥 Eingebettete Apps, Umgebungen mit geringen Ressourcen |
| Amazon Transcribe (AWS) | Stapel- & Streaming; PII-Schwärzung; benutzerdefinierte Vokabulare ✨ | ★4; skalierbarer Enterprise-Service | 💰 Pay-per-Minute; 12-monatige kostenlose Testphase | 👥 Entwickler, Unternehmen auf AWS |
| Google Cloud Speech‑to‑Text | Echtzeit & Stapel; Diarisierung; Keyword-Boost; Mehrkanal ✨ | ★4–5; starke Genauigkeit & Sprachunterstützung | 💰 Pay-per-Use; begrenzte kostenlose Minuten | 👥 Unternehmen, GCP-Kunden, Entwickler |
| Live Transcribe (Android) | Echtzeit-Untertitel; Geräusch-Labels; geräteinterne Privatsphäre ✨ | ★4; zuverlässig für persönliche Gespräche | 💰 Kostenlos | 👥 Gehörlose/Schwerhörige, Alltagsnutzer |
| Deepgram | Streaming & vorab aufgenommene API; Diarisierung; Keyword-Boosting ✨ | ★4; leistungsstarke API für Produktionsumgebungen | 💰 200 $ kostenlose Credits; Pay-per-Minute-Preise | 👥 Start-ups, Entwickler, Produktionsteams |
Die richtige Wahl treffen: Unsere endgültigen Empfehlungen
🎯 Passen Sie das Tool an Ihren Audiotyp an
Live-Diktate, Besprechungen, Podcasts oder voraufgezeichnete Dateien – jedes Tool ist für spezifische Audioszenarien optimiert. Wählen Sie basierend darauf, wie und wann Ihr Audio erstellt wird.
🔍 Balance zwischen Genauigkeit und Aufwand
Hohe Genauigkeit erfordert manchmal Einrichtung oder Bearbeitung. Entscheiden Sie, ob Sie sofortige Bequemlichkeit oder professionelle Ergebnisse mit geringfügiger Überprüfung bevorzugen.
🔐 Entscheiden Sie, wie wichtig Ihnen die Privatsphäre ist
Cloud-Tools sind praktisch, aber Offline- oder No-Training-Plattformen sind sicherer für sensible Besprechungen, Recherchen oder Kundengespräche.
💸 Denken Sie über die kostenlose Stufe hinaus
Kostenlose Pläne sind großartig zum Testen, aber die langfristige Nutzung kann Upgrades erfordern. Verstehen Sie die Grenzen bei Minuten, Exporten und Funktionen, bevor Sie skalieren.
Die Navigation in der Landschaft der kostenlosen Speech-to-Text-Software kann überwältigend sein, aber wie wir gesehen haben, ist das richtige Tool selten eine Einheitslösung. Ihre ideale Wahl hängt direkt von Ihren spezifischen Bedürfnissen ab, von der Art des Audios, das Sie transkribieren, bis hin zu Ihren Prioritäten in Bezug auf Datenschutz, Workflow-Integration und Offline-Zugriff. Die Reise vom gesprochenen Wort zum geschriebenen Text ist jetzt zugänglicher als je zuvor, angetrieben von einer vielfältigen Palette leistungsstarker und oft kostenloser Tools.
Speech-to-Text ist nicht mehr nur Transkription
Moderne Tools gehen heute über die Transkription hinaus und umfassen Zusammenfassungen, Content-Erstellung und Zusammenarbeit. Die Wahl der richtigen Plattform heute kann Ihren Workflow zukunftssicher machen, da die KI-Fähigkeiten weiter ausgebaut werden.
Im gesamten Leitfaden haben wir alles analysiert, von einfachen, integrierten Betriebssystem-Tools bis hin zu hochentwickelten Open-Source-Modellen und leistungsstarken Cloud-basierten APIs. Die wichtigste Erkenntnis ist, dass die "beste" kostenlose Speech-to-Text-Software diejenige ist, die nahtlos in Ihren Workflow passt, und nicht diejenige mit der längsten Funktionsliste.
Wichtigste Erkenntnisse für die Auswahl Ihres Tools
Um unsere Ergebnisse zusammenzufassen, lassen Sie uns die Kernentscheidungsfaktoren noch einmal durchgehen. Ihre endgültige Wahl wird wahrscheinlich ein Kompromiss zwischen Komfort, Genauigkeit, Kosten und Kontrolle sein.
- Für sofortigen, alltäglichen Gebrauch: Wenn Ihre Anforderungen einfach sind, wie z. B. das Verfassen von E-Mails, das Erstellen schneller Notizen oder die grundlegende Dokumentenerstellung, sind die integrierten Lösungen unschlagbar. Google Docs Spracheingabe und Windows Sprachsteuerung bieten unglaublichen Komfort ohne Einrichtung und sind daher perfekt für spontane Aufgaben.
- Für kollaborative und automatisierte Workflows: Teams und Fachleute, die automatisierte Besprechungsnotizen, Sprecheridentifizierung und Cloud-basierte Zusammenarbeit benötigen, werden enormen Wert in Diensten wie Otter.ai und Descript finden. Ihre kostenlosen Tarife bieten einen großzügigen Ausgangspunkt, um komplexe Transkriptions-Workflows zu optimieren.
- Für maximale Privatsphäre und Kontrolle: Wenn Datenschutz nicht verhandelbar ist oder Sie sensible Informationen verarbeiten müssen, sind Open-Source-Offline-Modelle der Goldstandard. OpenAI Whisper und sein effizientes Gegenstück whisper.cpp bieten hochmoderne Genauigkeit und stellen gleichzeitig sicher, dass Ihre Daten niemals Ihren lokalen Rechner verlassen.
- Für spezialisierte und volumenintensive Anforderungen: Entwickler und Unternehmen, die skalierbare, hochgenaue Transkriptionen für Anwendungen benötigen, sollten sich die leistungsstarken APIs von Google Cloud Speech-to-Text, Amazon Transcribe und Deepgram ansehen. Ihre kostenlosen Tarife sind darauf ausgelegt, Ihnen das Erstellen und Testen zu ermöglichen, bevor Sie sich für einen kostenpflichtigen Plan entscheiden.
Umsetzbare nächste Schritte zur Implementierung
Nachdem Sie nun ein klareres Bild von den verfügbaren Optionen haben, ist es an der Zeit zu handeln. Verfallen Sie nicht in Analyse-Paralyse; der beste Weg, die richtige Lösung zu finden, ist, mit dem Experimentieren zu beginnen.
- Identifizieren Sie Ihren primären Anwendungsfall: Sind Sie ein Podcaster, der Episodentranskripte benötigt, ein Student, der Vorlesungen aufzeichnet, oder ein Entwickler, der eine sprachaktivierte App erstellt? Definieren Sie zuerst Ihre wichtigste Anforderung.
- Testen Sie Ihre Top-Zwei-Kandidaten: Wählen Sie basierend auf Ihrem primären Bedarf zwei Tools aus unserer Liste aus, die am vielversprechendsten erscheinen. Wenn Sie beispielsweise ein Videoersteller sind, könnten Sie den kostenlosen Tarif von Descript mit einer lokalen Installation von Whisper vergleichen.
- Führen Sie einen realen Test durch: Verwenden Sie eine kurze, repräsentative Audiodatei (5-10 Minuten) und verarbeiten Sie sie mit beiden Tools. Vergleichen Sie die Ergebnisse anhand von Genauigkeit, Formatierung, Geschwindigkeit und der allgemeinen Benutzererfahrung. Hat ein Tool Fachbegriffe oder mehrere Sprecher besser verarbeitet? War der Bearbeitungsprozess bei einem einfacher als beim anderen?
- Bewerten Sie die Workflow-Auswirkungen: Überlegen Sie, wie jedes Tool in Ihren bestehenden Prozess passt. Erfordert es zusätzliche Schritte oder spart es Ihnen Zeit? Die beste kostenlose Speech-to-Text-Software liefert nicht nur ein großartiges Transkript, sondern macht auch Ihren gesamten Workflow effizienter.
Letztendlich liegt die Stärke der modernen Speech-to-Text-Technologie in ihrer Fähigkeit, den Wert freizusetzen, der in Ihren Audio- und Videoinhalten steckt. Indem Sie gesprochene Worte in durchsuchbaren, bearbeitbaren und teilbaren Text umwandeln, eröffnen Sie neue Möglichkeiten für die Inhaltserstellung, Barrierefreiheit, Forschung und Produktivität. Das perfekte Tool wartet darauf, in Ihren Workflow integriert zu werden, bereit, Ihnen Zeit und Mühe zu sparen.
Sind Sie bereit, ein Transkriptionstool zu erleben, das Wert auf Datenschutz, Genauigkeit und einen wunderschön einfachen Workflow legt? Während viele kostenlose Tools Einschränkungen bei Datenschutz oder Funktionen haben, ist Transcript.LOL für Fachleute konzipiert, die zuverlässige, sichere Transkriptionen ohne Komplexität benötigen. Verleihen Sie Ihrem Audio die hochwertige, private Transkription, die es verdient, indem Sie noch heute Transcript.LOL ausprobieren.