From Sound to Text Your Guide to Speech to Text Software
Discover how speech to text software transforms audio into valuable content. Learn how it works, what features matter, and how to choose the right tool.
Praveen
February 17, 2025
Speech-to-text software is the magic that turns spoken words from an audio file into plain, usable text. Think of it as your own digital stenographer, ready to listen to recordings, meetings, or voice notes and churn out an editable, searchable document in minutes. It’s a must-have for anyone looking to save a ton of time and make their audio content way more useful.
Unlocking Your Audio: From Sound Waves to Searchable Text
AI Transcription Features
IA all'avanguardia
Alimentato da Whisper di OpenAI per una precisione leader nel settore. Supporto per vocabolari personalizzati, file fino a 10 ore e risultati ultra rapidi.

Importa da più fonti
Importa file audio e video da varie fonti tra cui caricamento diretto, Google Drive, Dropbox, URL, Zoom e altro.

Rilevamento dei parlanti
Identifica automaticamente diversi parlanti nelle tue registrazioni e etichettali con i loro nomi.
Immagina questo: hai appena terminato un brillante episodio di podcast di due ore o una serie di interviste approfondite ai clienti. Quell'audio è pieno d'oro: spunti preziosi, citazioni efficaci e idee rivoluzionarie, ma è tutto intrappolato all'interno di un file audio. Non puoi cercarlo, non puoi citarlo facilmente e riutilizzarlo è un incubo. Ti ritrovi a fissare una montagna di audio con il compito snervante di digitare ogni singola parola.
Questo è un classico collo di bottiglia per creatori, ricercatori, marketer e studenti allo stesso modo. Tutto quel tempo trascorso chino sulla tastiera, trascrivendo manualmente, potrebbe essere speso in analisi, creazione di nuovi contenuti o pensiero strategico effettivo. Il software speech-to-text abbatte questa barriera, agendo da ponte tra le tue parole pronunciate e contenuti digitali attuabili.
Ma questa tecnologia non serve più solo a digitare per te; si tratta di sbloccare il potenziale nascosto nel tuo audio. Trasforma i tuoi file audio e video da registrazioni statiche in risorse dinamiche e polivalenti.
- Indice di ricerca: Una trascrizione rende i tuoi contenuti audio indicizzabili dai motori di ricerca, aiutando un pubblico completamente nuovo a trovare il tuo lavoro.
- Accessibilità: Offre un'alternativa testuale per le persone sorde o con problemi di udito, ampliando istantaneamente la tua portata.
- Riutilizzo: Ti consente di estrarre rapidamente citazioni per i social media, trasformare interviste in post di blog o creare note dettagliate dello show senza sudare.
La domanda per questo è in crescita esponenziale. Il mercato globale delle API speech-to-text è stato valutato a 2,2 miliardi di dollari nel 2021 e si prevede che raggiungerà i 5,4 miliardi di dollari entro il 2026. Questa incredibile crescita dimostra quanto la tecnologia vocale sia diventata essenziale in quasi tutti i settori. Puoi vedere la ripartizione completa in questo rapporto dettagliato sul mercato delle API speech-to-text.
Nella sua essenza, il processo è piuttosto semplice. Se vuoi capire le meccaniche di base, puoi esplorare come creare una trascrizione da qualsiasi file audio. Gli strumenti moderni hanno reso questo processo semplicissimo, fornendoti un documento altamente accurato con quasi nessuno sforzo. L'aggiunta di funzionalità come i timestamp è anche un punto di svolta per la sincronizzazione del testo con l'audio, il che è un salvavita per editor video e ricercatori. Per vedere come funziona, consulta la nostra guida su come ottenere una trascrizione con timecode per una precisione millimetrica.
Come l'IA Impara ad Ascoltare e Trascrivere
Hai mai usato un software speech-to-text? Può sembrare magia. Carichi un file audio o inizi a parlare e pochi istanti dopo, una trascrizione quasi perfetta appare sullo schermo. Ma dietro quel processo apparentemente semplice c'è un'affascinante collaborazione tra diversi modelli di IA che lavorano insieme per ascoltare, capire e scrivere, molto simile a come farebbe un essere umano.
Pensala come addestrare una stenografa alle prime armi. Prima, deve imparare a distinguere i singoli suoni. Poi, deve riconoscere quei suoni come parole. Infine, deve mettere insieme quelle parole in frasi che abbiano un senso. Un'IA segue un percorso sorprendentemente simile per raggiungere la sua elevata accuratezza.
L'intero processo inizia non appena il software mette le mani sul tuo file audio. Inizia scomponendo l'onda sonora continua della tua voce in migliaia di piccole unità sonore individuali. Queste sono chiamate fonemi, i mattoni più piccoli del linguaggio parlato, come il suono "c" in "cane" o "sc" in "scena".
Il Modello Acustico: Sentire le Parole
Una volta che l'audio è stato suddiviso in questi morsi sonori fondamentali, interviene il modello acustico. Questo è l'orecchio dell'IA. È stato addestrato su una vasta libreria di linguaggio parlato, contenente centinaia di migliaia di ore di audio che sono state meticolosamente abbinate alle loro trascrizioni testuali.
Questo intenso addestramento rende il modello acustico un esperto in una cosa: abbinare i fonemi in ingresso alle lettere e alle parole che già conosce. Analizza le frequenze e i pattern specifici di ogni suono e fa un'ipotesi informata, chiedendosi: "Questo piccolo frammento sonoro corrisponde al fonema per 't', 'o' o 'p'?"
Naturalmente, questo da solo raramente è perfetto. Fattori come accenti, rumori di fondo o semplicemente parlare molto velocemente possono facilmente confondere il modello acustico. Il risultato può essere un miscuglio di parole che suonano corrette ma non hanno assolutamente senso. È qui che entra in gioco il livello successivo di IA.
Questo diagramma mostra il flusso di base da un'onda sonora a un documento di testo finito.
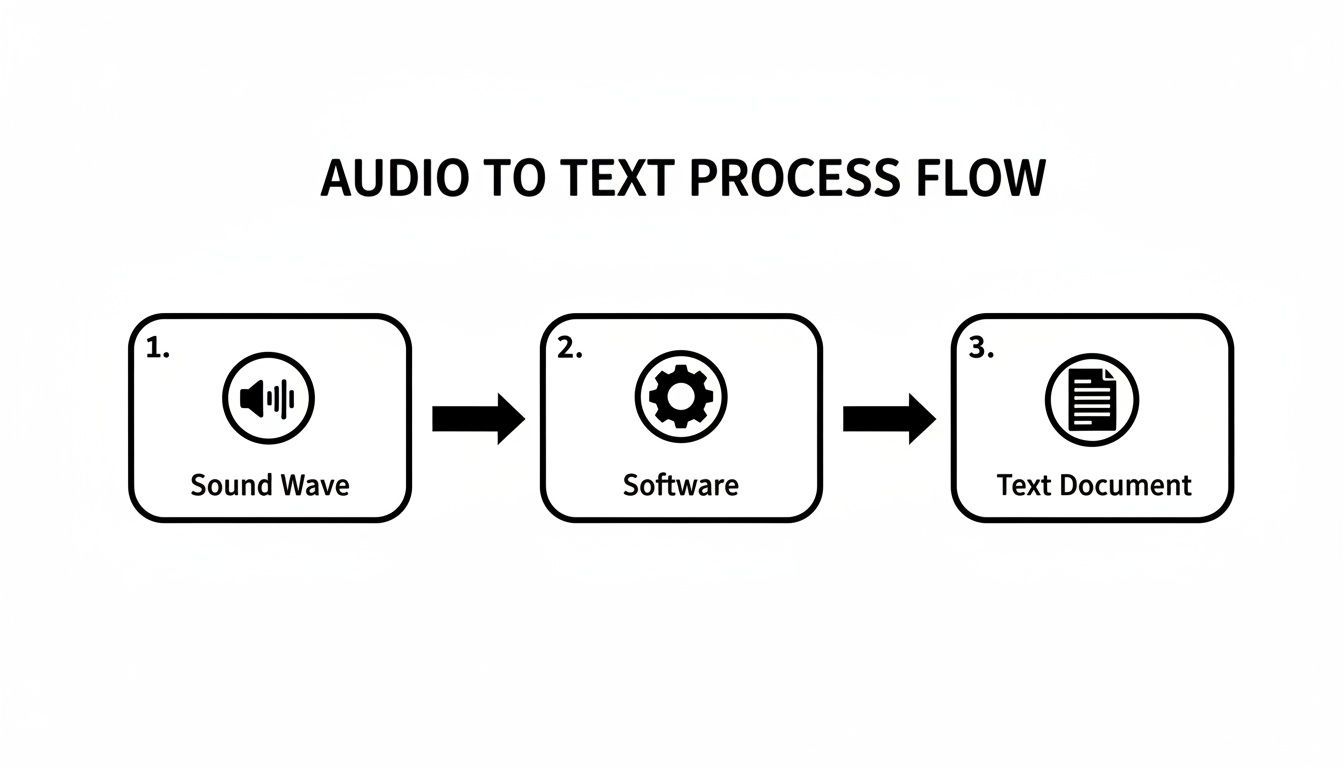
Questa semplice conversione è alimentata da complessi modelli di IA che lavorano in tandem per garantire che il testo finale sia sia accurato che leggibile.
Il Modello Linguistico: Dare un Senso a Tutto
Dopo che il modello acustico ha prodotto la sua bozza grezza, interviene il modello linguistico. Puoi pensarlo come il cervello dell'IA o il suo editor interno. Mentre il modello acustico si occupa dei suoni, il modello linguistico è ossessionato dal contesto, dalla grammatica e dalla probabilità.
È stato addestrato su una gigantesca libreria di testi: libri, articoli, siti web, tutto ciò che puoi immaginare, quindi ha una profonda comprensione di come le parole dovrebbero stare insieme. Guarda l'output grezzo del modello acustico e inizia a porsi alcune domande critiche:
- Grammatica: Questa frase è costruita correttamente?
- Contesto: Questa parola segue logicamente quella precedente?
- Probabilità: È più probabile che l'oratore abbia detto "Io urlo per il gelato" o "Occhio urla per io urlo"?
Ad esempio, un modello acustico potrebbe sentire "riconoscere il parlato" e "rovinare una bella spiaggia" come quasi identici. Ma il modello linguistico sa che "riconoscere il parlato" è una frase molto più comune e logica, specialmente nel contesto di una trascrizione. Corregge questi tipi di errori, leviga le frasi goffe e aggiunge persino la punteggiatura in base alle pause e all'intonazione dell'oratore. Questo sistema a due parti è il segreto del successo di come l'IA audio-testo raggiunge risultati così impressionanti.
Why Two Models Matter
Acoustic models focus on sound accuracy, while language models ensure context and readability. Together, they reduce errors caused by accents, homophones, and unclear pronunciation. This layered approach is why modern speech-to-text tools outperform older dictation systems.
Punto chiave: L'accuratezza del software di sintesi vocale si basa su un potente duo. Il modello acustico trasforma il suono grezzo in un elenco di parole probabili, e il modello linguistico utilizza il contesto e la grammatica per trasformare quell'elenco in testo coerente e accurato.
Tutta questa collaborazione avviene in una frazione di secondo, trasformando un flusso audio disordinato in un documento pulito e strutturato, pronto per essere utilizzato.
Scegliere il Tuo Kit di Strumenti: Funzionalità Essenziali e Avanzate
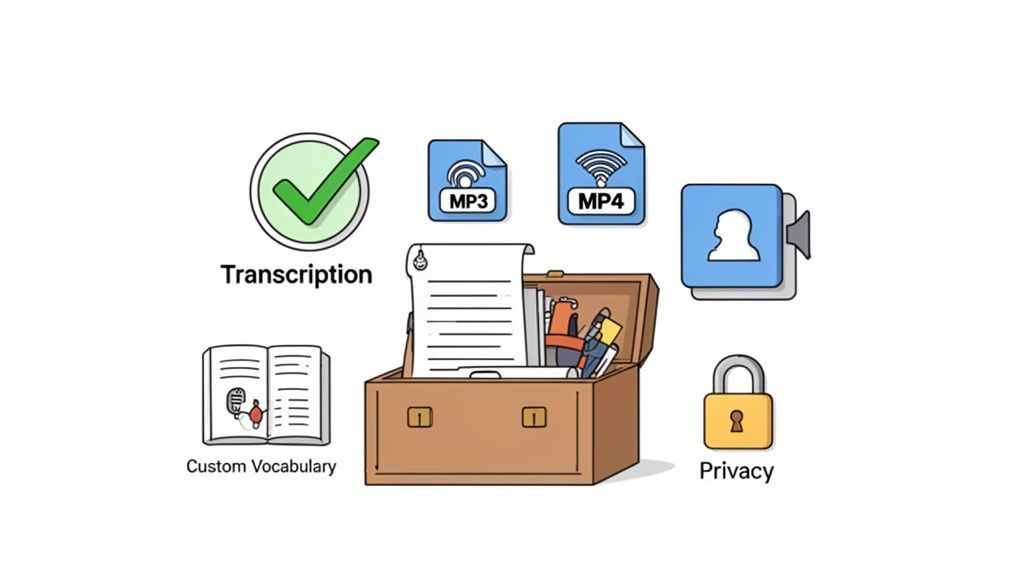
Scegliere il giusto software di sintesi vocale è un po' come scegliere un'auto. Una berlina di base ti porta dal punto A al punto B, senza problemi. Ma se devi trasportare attrezzature pesanti, avrai bisogno di un camion specializzato.
Allo stesso modo, quasi ogni strumento può trasformare l'audio in parole, ma i migliori sono ricchi di funzionalità progettate per gestire flussi di lavoro impegnativi e specifici senza sudare. Per scegliere quello giusto, devi separare ciò che è indispensabile da ciò che è un "bello avere".
I Non Negoziabili: Funzionalità di Trascrizione Fondamentali
Prima di lasciarti distrarre da campane e fischietti luccicanti, devi assicurarti che il software gestisca bene le basi. Questi sono i pilastri che rendono uno strumento veramente utile invece di una fonte di frustrazione costante.
Pensa a questi come al motore, alle ruote e allo sterzo del tuo veicolo di trascrizione: se li sbagli, non andrai da nessuna parte.
- Alta Accuratezza: Questo è tutto. Una trascrizione piena di errori crea più lavoro di quanto ne risparmi, lasciandoti a passare ore a correggere. Dovresti cercare piattaforme che raggiungano costantemente il 95% di accuratezza o superiore su audio chiaro.
- Ampio Supporto per Formati di File: I tuoi file audio e video sono di tutte le forme e dimensioni. Un buon strumento dovrebbe gestire formati comuni come MP3, MP4, M4A e WAV senza costringerti a convertire i file prima.
- Limiti Generosi sui File: I progetti del mondo reale spesso significano contenuti di lunga durata. Che si tratti di un podcast di due ore o di una conferenza di un'intera giornata, il software deve gestire file di grandi dimensioni e registrazioni lunghe senza bloccarsi.
Queste tre funzionalità sono la base assoluta per qualsiasi software di sintesi vocale efficace. Sono ciò che rende uno strumento affidabile e flessibile per il lavoro effettivo.
Oltre le Basi: Funzionalità Avanzate che Risparmiano Tempo Prezioso
Una volta che uno strumento ha padroneggiato i fondamenti, è ora di esaminare le funzionalità avanzate. È qui che un buon servizio diventa un ottimo servizio, trasformando un semplice strumento di trascrizione in una vera centrale di produttività.
Productivity & Export Features
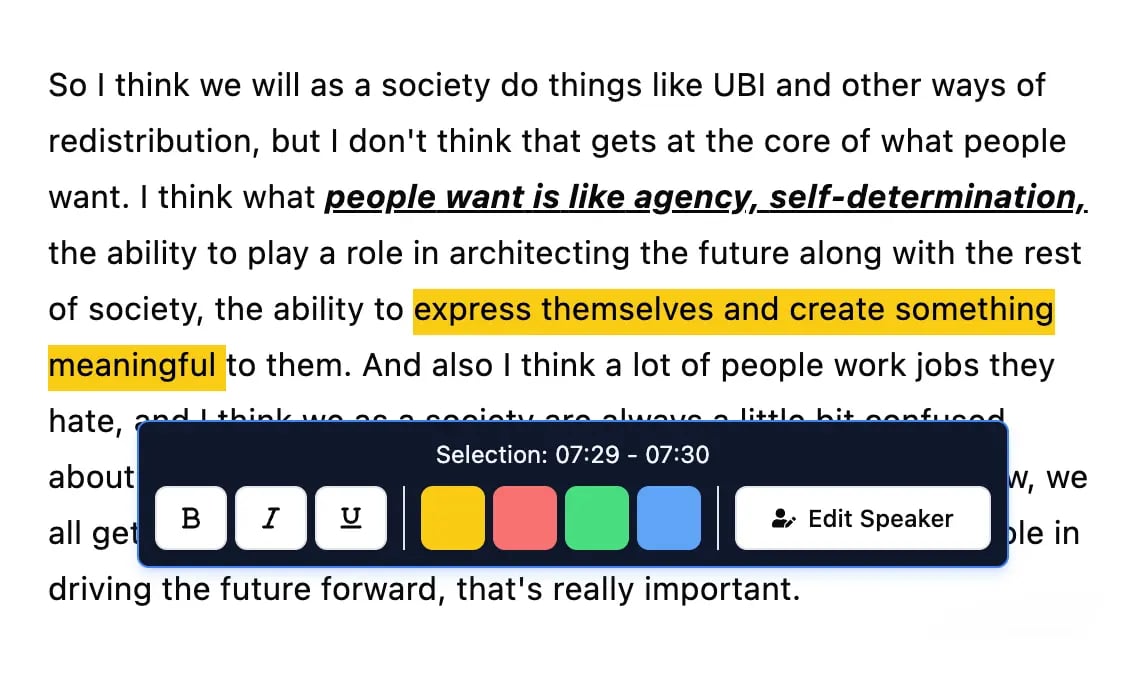
Strumenti di modifica
Modifica le trascrizioni con strumenti potenti tra cui trova e sostituisci, assegnazione dei parlanti, formati di testo arricchito ed evidenziazione.
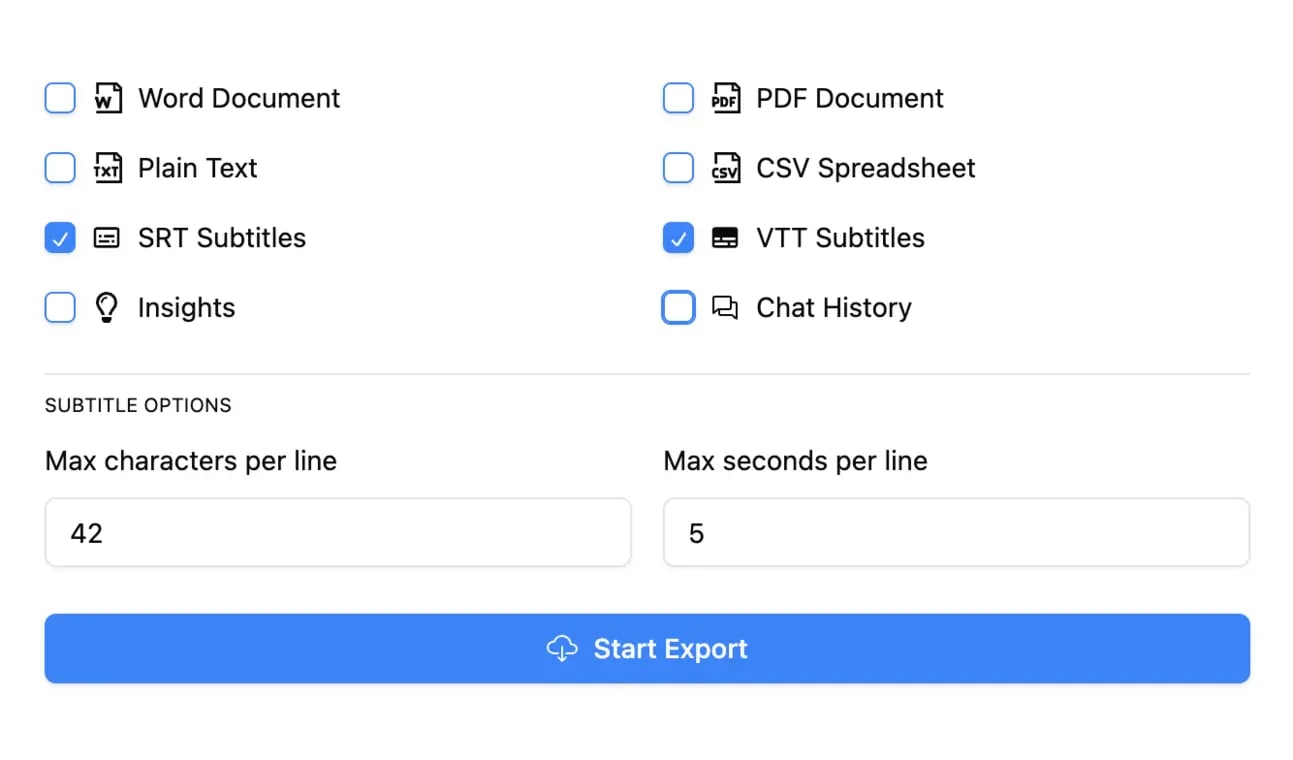
Esporta in più formati
Esporta le tue trascrizioni in più formati tra cui TXT, DOCX, PDF, SRT e VTT con opzioni di formattazione personalizzabili.
Riassunti e Chatbot
Genera riassunti e altri approfondimenti dalla tua trascrizione, prompt personalizzati riutilizzabili e chatbot per i tuoi contenuti.
Questi sono il GPS, la trazione integrale e lo spazio di carico extra del tuo software: ti aiutano a navigare in progetti complicati, a gestire un carico di lavoro più pesante e a performare quando le condizioni si fanno difficili. E il mercato per questi strumenti è in piena espansione. Il mercato delle API speech-to-text è stato valutato a 2,77 miliardi di dollari nel 2023 e si prevede che raggiungerà i 9,86 miliardi di dollari entro il 2032, secondo un recente report sul mercato delle API speech-to-text.
Insight chiave: Per i professionisti, le funzionalità avanzate non sono solo vantaggi. Si traducono direttamente in tempo risparmiato, lavoro di qualità superiore e flussi di lavoro più fluidi.
Ecco i fattori che cambiano il gioco da cercare:
- Etichettatura automatica degli altoparlanti (Diarizzazione): Questo è un salvavita per qualsiasi registrazione con più persone: interviste, riunioni, focus group, ecc. Il software capisce automaticamente chi sta parlando e tagga il dialogo ("Speaker 1", "Speaker 2"), risparmiandoti il noioso lavoro di farlo manualmente.
- Vocabolario personalizzato: I modelli AI standard spesso inciampano su gergo settoriale, acronimi aziendali o nomi unici. Una funzionalità di vocabolario personalizzato ti consente di "insegnare" all'AI questi termini specifici, il che aumenta enormemente l'accuratezza per contenuti specializzati in campi come medicina, legge o tecnologia.
- Integrazioni senza interruzioni: I migliori strumenti funzionano bene con gli altri. Cerca integrazioni con piattaforme che già utilizzi, come Google Drive, Dropbox o YouTube. Questo crea un flusso di lavoro automatico in cui i tuoi file vengono trascritti automaticamente, senza caricamenti manuali. La nostra guida sul software di trascrizione basato su AI mostra come queste connessioni creano un sistema molto più efficiente.
- Opzioni di esportazione versatili: Un semplice file .txt spesso non è sufficiente. Le piattaforme di alto livello ti consentono di esportare trascrizioni in più formati, come DOCX per report, SRT/VTT per sottotitoli video e PDF per una facile condivisione. Questa flessibilità rende la tua trascrizione immediatamente utile per qualsiasi cosa tu ne abbia bisogno.
- Politica di privacy dei dati robusta: Questo è un punto importante. Quando carichi conversazioni sensibili, devi sapere che i tuoi dati sono al sicuro. Scegli solo un provider con una chiara politica sulla privacy che garantisca che non utilizzerà i tuoi dati per addestrare i propri modelli AI. Questo è l'unico modo per garantire che le tue informazioni riservate rimangano tali.
Per aiutarti a decidere cosa è giusto per te, ecco una rapida ripartizione delle funzionalità essenziali rispetto a quelle più avanzate.
Funzionalità Essenziali vs Avanzate di Speech to Text
| Funzionalità | Cosa Fa | Chi Ne Ha Più Bisogno |
|---|---|---|
| Alta Precisione | Fornisce una trascrizione con errori minimi, che richiede poca o nessuna correzione. | Tutti. Questo è il requisito fondamentale per qualsiasi strumento di trascrizione utile. |
| Ampio Supporto Formati File | Accetta file audio e video comuni (MP3, MP4, WAV) senza la necessità di conversione. | Utenti che lavorano con diverse fonti multimediali e non vogliono il fastidio della preparazione dei file. |
| Limiti Generosi sui File | Gestisce registrazioni lunghe (ad es. 2+ ore) e file di grandi dimensioni senza errori. | Podcaster, ricercatori, giornalisti e chiunque si occupi di contenuti di lunga durata. |
| Etichettatura degli Altoparlanti | Identifica e etichetta automaticamente diversi altoparlanti nella trascrizione (ad es. "Speaker 1"). | Intervistatori, organizzatori di riunioni e ricercatori qualitativi che hanno bisogno di distinguere tra le voci. |
| Vocabolario Personalizzato | Ti consente di aggiungere termini specifici, nomi o gergo per migliorare l'accuratezza del riconoscimento. | Professionisti in campi tecnici (medico, legale, finanziario) dove la precisione è fondamentale. |
| Integrazioni | Si collega ad altre app come Google Drive o YouTube per automatizzare il flusso di lavoro di trascrizione. | Creatori di contenuti, marketer e team che cercano di costruire pipeline di contenuti efficienti e automatizzate. |
| Opzioni di Esportazione Versatili | Ti consente di scaricare trascrizioni in più formati (DOCX, SRT, VTT, PDF) per usi diversi. | Editor video che necessitano di sottotitoli, scrittori che redigono report e chiunque riutilizzi contenuti su più piattaforme. |
| Garanzie sulla Privacy dei Dati | Garantisce che i tuoi file audio/video riservati non vengano utilizzati per addestrare modelli AI. | Professionisti legali, terapisti, team aziendali e chiunque gestisca informazioni sensibili o proprietarie. |
In definitiva, lo strumento migliore è quello che si adatta al tuo flusso di lavoro. Comprendendo la differenza tra le necessità fondamentali e i potenti add-on, puoi trovare una soluzione che non solo risolva i problemi di oggi, ma sia pronta a crescere con te.
Mettere la Trascrizione al Lavoro in Diversi Settori
Certo, la tecnologia alla base dello speech-to-text è affascinante, ma è nella risoluzione di problemi quotidiani che davvero brilla. Non si tratta solo di trasformare l'audio in parole; è un motore di produttività che fa risparmiare innumerevoli ore, sblocca nuovi contenuti e rende le informazioni più accessibili in decine di campi. L'impatto è reale: trasforma ore di noioso lavoro manuale in minuti di azione focalizzata e strategica.
Dai team di marketing alle aule universitarie, le applicazioni sono tanto diverse quanto preziose. Ogni settore utilizza la trascrizione per affrontare le proprie sfide uniche, che si tratti di scalare la produzione di contenuti, migliorare i risultati degli studenti o mantenere registri meticolosi per la conformità legale e medica.
How Different Teams Use Speech-to-Text?
Content Creators
Podcasters and YouTubers turn episodes into blogs, captions, and social posts without extra recording time. One file becomes multiple content assets.
Researchers & Academics
Interview transcripts become searchable datasets, speeding up qualitative analysis and reducing research turnaround time.
Corporate Teams
Meeting recordings transform into clear minutes, action items, and knowledge archives that keep teams aligned.
Healthcare Professionals
Doctors dictate notes directly into systems, reducing admin workload while maintaining accurate medical records.
Il filo conduttore è sempre l'efficienza. Si tratta di liberare i professionisti per concentrarsi su lavori di alto valore invece di impantanarsi nella trascrizione manuale.
Content Marketing e Produzione Multimediale
Per chiunque si occupi di marketing o media, un singolo file audio o video è una miniera d'oro. Un podcast o un webinar di un'ora, una volta trascritti, diventano il materiale grezzo per una dozzina di altri contenuti. Questa strategia "crea una volta, distribuisci molte" è il segreto per massimizzare il tuo ROI e raggiungere un pubblico molto più ampio.
Pensa a una singola intervista podcast. L'audio è ottimo, ma la trascrizione è un coltellino svizzero per il marketing.
- Post del Blog e Articoli: La trascrizione completa può essere rifinita in un post del blog completo, arricchito di parole chiave per attirare traffico organico dai motori di ricerca.
- Contenuti per i Social Media: Estrai le migliori citazioni e i migliori spezzoni per creare grafiche accattivanti, brevi clip video e post incisivi per i social media.
- Newsletter via Email: Un breve riassunto o un elenco di punti chiave rendono una newsletter ricca di valore che mantiene il tuo pubblico coinvolto.
- Lead Magnet: Formatta la trascrizione in un PDF scaricabile e offrila come risorsa gratuita per acquisire nuovi lead.
È qui che entrano in gioco strumenti specializzati, come strumenti di trascrizione podcast progettati per migliorare l'accessibilità e la SEO. Questo semplice flusso di lavoro trasforma una singola registrazione in una campagna di marketing completa e multicanale.
Educazione e Ricerca Accademica
Nel mondo accademico, chiarezza e accesso sono tutto. Il software speech-to-text è un vero e proprio punto di svolta per studenti ed educatori, trasformando lezioni parlate e interviste di ricerca in testo ricercabile e digeribile.
Per gli studenti, una lezione trascritta è uno strumento di studio incredibile. Possono cercare istantaneamente termini specifici o concetti menzionati da un professore senza dover scorrere ore di video. Rende la preparazione agli esami molto più efficiente e aiuta gli studenti con diversi stili di apprendimento a connettersi con il materiale.
Anche i ricercatori vedono enormi vantaggi. La trascrizione di interviste qualitative era un lavoro manuale dolorosamente lento. La trascrizione automatizzata trasforma completamente questo flusso di lavoro, consentendo ai ricercatori di passare dalla raccolta dati all'analisi in una frazione del tempo. Fa risparmiare un'incredibile quantità di tempo e budget.
Ambienti Legali e Aziendali
Nei mondi legale e aziendale, accuratezza e documentazione non sono solo desiderabili, ma obbligatorie. Ogni riunione, deposizione, chiamata con il cliente e sessione di formazione sulla conformità contiene informazioni critiche che devono essere catturate perfettamente.
Affidarsi a note manuali è una ricetta per errori umani e dettagli mancati. Un servizio di trascrizione automatizzato fornisce un resoconto verbatim, creando un'unica fonte di verità affidabile.
- Legale: Gli avvocati possono scansionare rapidamente deposizioni e procedimenti giudiziari, cercando testimonianze specifiche senza dover riascoltare intere registrazioni.
- Aziendale: I team possono generare verbali di riunione perfetti, completi di chi ha detto cosa, garantendo che tutti siano allineati sugli elementi d'azione e sulle decisioni. Questo crea responsabilità e un archivio ricercabile della conoscenza aziendale.
Il Ruolo Crescente nella Sanità
Da nessuna parte il bisogno di documentazione accurata e sicura è più critico che nella sanità. L'industria sanitaria è ora l'utente in più rapida crescita del riconoscimento vocale, spinta dall'aumento del monitoraggio remoto dei pazienti, delle consultazioni virtuali e dalla costante necessità di documentazione medica.
I medici utilizzano il software speech-to-text per dettare note sui pazienti, riassunti di consultazioni e referti medici direttamente nei sistemi di cartelle cliniche elettroniche (EHR). Questo non solo velocizza la burocrazia, ma riduce il carico amministrativo sui medici, liberandoli per dedicare più tempo alla cura effettiva dei pazienti.
Data la sensibilità di questi dati, funzionalità come una solida privacy dei dati e vocabolari personalizzati per il gergo medico sono non negoziabili. Per vedere come funziona in pratica, consulta la nostra guida ai flussi di lavoro di trascrizione medica e sanitaria.
Ottimizzazione del Flusso di Lavoro dall'Audio all'Asset
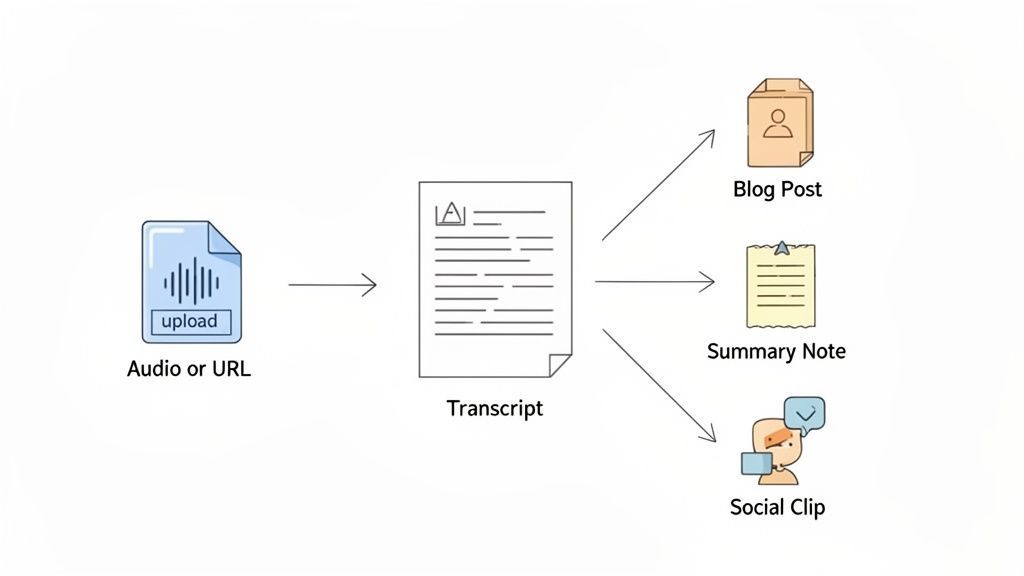
È una cosa capire le funzionalità del software speech-to-text, ma un'altra è vedere come si incastrano in un flusso di lavoro fluido e senza interruzioni. Uno strumento moderno fa più che semplicemente mettere parole su carta: trasforma il lavoro gravoso della trascrizione in un trampolino di lancio per tutti i tipi di asset creativi. Non stai solo trascrivendo; stai trasformando un file audio grezzo in qualcosa di prezioso con quasi nessuno sforzo.
Tutto inizia con un semplice passaggio. Puoi trascinare e rilasciare un file dal tuo computer o collegare servizi cloud come Google Drive e Dropbox. Molte piattaforme, inclusa Transcript.LOL, ti consentono persino di incollare un URL da YouTube o Vimeo, e loro estrarranno l'audio per te. Questa flessibilità elimina qualsiasi intoppo iniziale e porta subito i tuoi contenuti nel sistema.
In pochi minuti, l'IA fa il suo lavoro e restituisce una trascrizione altamente accurata. È qui che vedi immediatamente il valore. Invece di un blocco di testo gigante e intimidatorio, ottieni un documento pulito e strutturato con etichettatura automatica degli oratori. Niente più mal di testa nel cercare di capire chi ha detto cosa.
Dal Testo Grezzo al Documento Rifinito
Una volta completata la bozza iniziale, il tuo lavoro passa dalla trascrizione alla rifinitura. I migliori strumenti ti offrono un editor intuitivo dove puoi controllare il testo mentre ascolti la riproduzione audio. Rende facile correggere eventuali piccoli errori, assegnare nomi corretti agli oratori e modificare i timestamp per sincronizzare tutto perfettamente.
Il vero risparmio di tempo, tuttavia, è la funzionalità di vocabolario personalizzato. Prima ancora di iniziare, puoi insegnare all'IA gergo specifico, nomi di prodotti o strane grafie uniche del tuo mondo. Fare questo passaggio iniziale significa che non dovrai correggere manualmente termini come "cardiopopolmonare" o un nome di marchio come "AcuTech" più e più volte.
Questa intera prima fase è costruita per la velocità. È progettata per farti passare da una registrazione grezza a un documento rifinito e accurato in una frazione del tempo che ci vorrebbe per farlo a mano. L'obiettivo è semplice: dedicare meno tempo alla correzione e più tempo alla creazione.
La Potenza degli Strumenti AI Post-Trascrizione
Ottenere una trascrizione eccellente è solo il punto di partenza. La vera magia delle piattaforme moderne è ciò che puoi fare dopo che le parole sono sulla pagina. Invece di esportare semplicemente un file DOCX o SRT e considerarlo finito, puoi utilizzare strumenti AI integrati per riutilizzare istantaneamente i tuoi contenuti.
Immagina di cliccare su un singolo pulsante e ottenere:
- Un riassunto conciso che riduce una riunione di un'ora ai suoi punti chiave.
- Un post del blog pronto per la pubblicazione tratto da un'intervista podcast.
- Un elenco pulito di elementi d'azione estratti da un brainstorming di team.
- Una manciata di post coinvolgenti per i social media, completi di citazioni e hashtag.
Questo è il grande cambiamento. Il software smette di essere un semplice trascrittore e diventa un motore di contenuti a tutti gli effetti, moltiplicando il valore di ogni singola registrazione che fai.
Naturalmente, l'intero processo deve essere costruito su una base di solida sicurezza e privacy. Se hai a che fare con riunioni sensibili con i clienti o interviste riservate, devi utilizzare un servizio che si impegni a una rigorosa politica di non addestramento. Questo garantisce che le tue conversazioni private non vengano utilizzate per addestrare i modelli AI di altre aziende. I tuoi dati rimangono tuoi, punto.
Alcune Domande Comuni che Sentiamo
Immergersi nella trascrizione automatizzata solleva molte domande. È una tecnologia potente, ma i dettagli contano davvero quando si sceglie lo strumento giusto e si capisce come usarlo in modo efficace. Abbiamo raccolto alcune delle domande più comuni sul software speech to text per darti risposte chiare e dirette.
Consideralo la tua guida per tagliare il rumore del marketing. Affronteremo le preoccupazioni del mondo reale su accuratezza, funzionalità e sicurezza in modo che tu possa fare una scelta fiduciosa.
Quanto è Accurata Questa Roba, Davvero?
I moderni servizi basati sull'IA sono diventati incredibilmente bravi. In condizioni ideali - pensa a una registrazione audio pulita con un singolo oratore e nessun rumore di fondo - il miglior software può raggiungere oltre il 95% di accuratezza. È un enorme miglioramento rispetto ai goffi strumenti di dettatura del passato, tutto grazie ai modelli AI addestrati su un'incredibile quantità di linguaggio parlato.
Ma il mondo reale è disordinato. L'accuratezza può diminuire quando si introducono accenti forti, persone che parlano contemporaneamente o semplicemente un microfono scadente. Per campi specializzati come la medicina o il diritto, dove il gergo è ovunque, l'IA può inciampare. Ecco perché una funzionalità di vocabolario personalizzato è così critica per i professionisti: ti permette di "insegnare" al software termini unici, il che può aumentare drasticamente la sua precisione.
Può Gestire Più di un Oratore?
Sì, assolutamente. Infatti, questa è una delle funzionalità più preziose che troverai negli strumenti moderni. La magia dietro di essa si chiama diarizzazione dell'oratore. È un termine elegante per un processo semplice: l'IA ascolta l'audio, capisce chi sta parlando e quando, e separa le voci automaticamente.
Una volta rilevato un nuovo oratore, etichetta il suo testo di conseguenza (come "Oratore 1", "Oratore 2", ecc.). Questa è una funzionalità indispensabile per chiunque trascriva:
- Interviste
- Riunioni di team
- Podcast con più ospiti
- Focus group
- Deposizioni legali
Senza di essa, ottieni solo un enorme muro di testo. Dovresti ascoltare manualmente e capire chi ha detto cosa, il che è un mal di testa enorme. L'etichettatura automatica degli oratori fa risparmiare ore di lavoro e rende la trascrizione utile fin da subito.
Qual è la Differenza tra una Trascrizione e i Sottotitoli?
Questa è una confusione comune, ma i due servono scopi completamente diversi. Entrambi provengono dallo stesso audio, ma sono formattati e utilizzati in modi totalmente diversi.
Distinzione Chiave: Una trascrizione è un documento di testo per la lettura e l'analisi. I sottotitoli sono frammenti di testo temporizzati progettati per apparire su uno schermo in sincronia con un video.
Una trascrizione è il testo completo di un file audio o video, tipicamente consegnato come un singolo documento (come un file DOCX o TXT). Le persone lo usano per cercare parole chiave, modificare contenuti o trasformare una conversazione in un post del blog o in un articolo.
I sottotitoli, d'altra parte, sono disponibili in formati speciali come SRT o VTT. Questi file suddividono la trascrizione in piccoli blocchi temporizzati. Ogni blocco è programmato per apparire sullo schermo nel momento esatto in cui le parole vengono pronunciate. Il loro compito principale è rendere i video accessibili agli spettatori sordi o con problemi di udito e attirare l'attenzione sui social media, dove la maggior parte dei video viene guardata senza audio.
I Miei Dati Sono Sicuri Quando Li Carico?
Questa è una questione importante, e la risposta dipende davvero dal provider che scegli. Quando carichi un file con informazioni sensibili - una riunione riservata, una consultazione con un paziente, un'intervista privata - stai riponendo molta fiducia in quell'azienda.
I buoni servizi utilizzano una forte crittografia per proteggere i tuoi file mentre vengono caricati e mentre sono archiviati sui loro server. Ma la cosa più importante da controllare è l'informativa sulla privacy dell'azienda, specialmente ciò che dice sull'uso dei tuoi dati per l'addestramento dei modelli AI.
Molte piattaforme si riservano il diritto di utilizzare il tuo audio e le tue trascrizioni per migliorare la propria IA. Se hai a che fare con informazioni riservate, questo è un enorme campanello d'allarme. Hai assolutamente bisogno di trovare un provider con una politica di non addestramento chiara ed esplicita. Questo garantisce che i tuoi dati privati rimangano privati e non vengano mai utilizzati per nulla se non per generare la tua trascrizione. Metti sempre, sempre la tua privacy al primo posto.
Data Privacy Is Not Optional
Not all transcription platforms protect your data. Some providers reuse uploaded audio to train their AI models. Always verify a clear no-training policy before uploading confidential or sensitive recordings.
Ready to turn your audio and video into accurate, actionable text with a platform that respects your privacy? Transcript.LOL offers an AI-powered solution with speaker detection, custom vocabulary, and a strict no-training policy to keep your data secure. Experience the difference by visiting https://transcript.lol today.
Start Transcribing Smarter Today
Turn audio into accurate, secure, and reusable text with AI-powered transcription built for professionals.