Entmystifizierung der Genauigkeit von Sprache-zu-Text
Ein vollständiger Leitfaden zur Genauigkeit von Sprache-zu-Text. Erfahren Sie, wie sie gemessen wird, welche Faktoren sie beeinflussen und welche umsetzbaren Strategien Sie für klarere Transkriptionen anwenden können.
Kate
October 4, 2023
Wir alle kennen die komisch schlechten automatischen Untertitel, die völlig daneben liegen. Aber wenn es um viel geht, ist die Genauigkeit von Sprache-zu-Text nicht verhandelbar. Sie ist das entscheidende Maß dafür, wie gut eine Maschine gesprochene Worte in geschriebenen Text umwandelt, und selbst winzige Fehler können massive Probleme verursachen.
Warum Branchen mit hohen Einsätzen Präzision verlangen

Denken Sie an einen Gerichtsreporter, der jedes Wort einer juristischen Aussage festhält. Eine einzige fehlinterpretierte Formulierung – wie die Transkription von „er hat eine bekannte Vorgeschichte von Gewalt“ als „er hat keine Vorgeschichte von Gewalt“ – könnte den Ausgang eines Falles komplett verändern. Dies ist ein perfektes Beispiel dafür, warum Genauigkeit mehr als nur ein technischer Wert ist; sie ist die Grundlage des Vertrauens für kritische Anwendungen.
Dasselbe gilt für das Gesundheitswesen, wo ein Transkriptionsfehler in den Notizen eines Arztes zu einer falschen Diagnose oder Medikation führen könnte. Und für Unternehmen, die Kundenservice-Gespräche verstehen wollen, bedeuten unordentliche Transkripte fehlerhafte Daten. Sie treffen strategische Entscheidungen auf der Grundlage eines verzerrten Bildes dessen, was Ihre Kunden tatsächlich sagen.
Die Entwicklung der Genauigkeit
Der Weg zu den heutigen Standards war lang. Im Jahr 2001 erreichte die Spracherkennung eine Genauigkeit von etwa 80 %, was damals eine Sensation war. Dies basierte auf statistischen Modellen aus den 1980er Jahren, die Vokabulare von nur wenigen hundert Wörtern auf Tausende erweiterten.
Dann, um 2007, beschleunigte sich die Entwicklung wirklich, als die Google-Sprachsuche ihren riesigen Datensatz – erstaunliche 230 Milliarden Wörter aus Nutzeranfragen – in das Problem einbrachte und ihre Vorhersagekraft dramatisch verbesserte. Sie können die Geschichte dieser Verbesserungen erkunden und sehen, wie weit die Technologie gekommen ist.
Ungenaue Transkriptionen erzeugen einen Welleneffekt. Sie verursachen nicht nur Verwirrung; sie untergraben das Vertrauen in die Technologie, schmälern den Wert datengesteuerter Erkenntnisse und können ernsthafte Compliance-Risiken mit sich bringen.
Die Quintessenz ist einfach: schlechte Genauigkeit macht Sprachdaten nutzlos oder schlimmer, gefährlich irreführend. Die höchstmögliche Genauigkeit von Sprache zu Text ist für jedes Unternehmen, das Sprache nutzt, absolut unerlässlich für:
-
Compliance und juristische Dokumentation: Jedes Wort präzise für Gerichtsakten, Zeugenaussagen und behördliche Einreichungen erfassen.
-
Business Intelligence: Klare, umsetzbare Erkenntnisse aus Kundenfeedback, Verkaufsgesprächen und internen Besprechungen ohne beschädigte Daten gewinnen.
-
Benutzererfahrung: Zuverlässige Untertitel, zugängliche Inhalte und Sprachbefehle liefern, die tatsächlich funktionieren, und so das Vertrauen der Benutzer stärken statt Frustration zu erzeugen.
Wie wir die Transkriptionsgenauigkeit messen
Bevor Sie die Genauigkeit von Sprache zu Text verbessern können, müssen Sie sie zuerst messen. Wie bewertet man tatsächlich, wie gut eine Maschine „zuhört“?
Der branchenweite Standard dafür ist eine Metrik namens Word Error Rate (WER). Stellen Sie es sich wie eine Golfpunktzahl für Ihre Transkripte vor – je niedriger die Zahl, desto besser die Leistung. Sie gibt uns eine einfache, konkrete Möglichkeit zu beurteilen, wie genau eine KI-Transkription mit einer perfekten, menschlich verifizierten Version übereinstimmt.
Ein perfektes Transkript erzielt eine 0 % WER. Anstatt einer komplexen Formel ist es im Grunde nur eine einfache Zählung der Fehler, die die KI gemacht hat, geteilt durch die Gesamtzahl der Wörter im korrekten Transkript.
Die drei Arten von Transkriptionsfehlern
Wenn wir die WER berechnen, suchen wir nach drei spezifischen Fehlertypen. Jeder von ihnen erhöht die Fehlerzahl und treibt die Punktzahl in die Höhe.
-
Substitutionen (S): Hier hört die KI ein Wort, schreibt aber ein anderes. Zum Beispiel sagt der Sprecher: „Treffen wir uns am Dienstag“, aber das Transkript lautet: „Treffen wir uns am Donnerstag“.
-
Löschungen (D): Das ist einfach – die KI übersieht ein Wort komplett. Die Audioaufnahme könnte lauten: „Bitte senden Sie den endgültigen Bericht“, aber das Transkript erfasst nur: „Bitte senden Sie den Bericht“.
-
Einfügungen (I): Das Gegenteil einer Löschung. Hier fügt die KI ein Wort hinzu, das nie tatsächlich gesprochen wurde. Zum Beispiel wird „Prüfen Sie den Status“ als „Prüfen Sie den Status“ transkribiert.
Um die endgültige Punktzahl zu erhalten, addieren Sie einfach alle Substitutionen, Löschungen und Einfügungen und teilen diese Summe durch die Anzahl der Wörter im ursprünglichen, korrekten Transkript.
Die Formel lautet: WER = (S + D + I) / N
Wobei S = Substitutionen, D = Löschungen, I = Einfügungen und N = Gesamtzahl der Wörter im korrekten Transkript.
Lassen Sie uns ein kurzes Beispiel durchgehen, um dies in Aktion zu sehen.
Beispiel für die Berechnung der Wortfehlerrate (WER)
Diese Tabelle zeigt, wie Fehler gezählt werden, wenn die ursprünglichen gesprochenen Wörter mit dem von der KI transkribierten Text verglichen werden.
Fehlertyp | Ursprünglicher Satz | Transkribierter Text | Fehleranzahl |
|---|---|---|---|
Löschung | „Senden Sie mir die Rechnung“ | „Senden Sie mir Rechnung“ | 1 |
Einfügung | „Prüfen Sie den Status“ | „Prüfen Sie den Status“ | 1 |
Substitution | „Treffen am Dienstag“ | „Treffen am Donnerstag“ | 1 |
Gesamte Fehler | 3 |
In diesem einfachen Fall mit insgesamt 10 ursprünglichen Wörtern und 3 identifizierten Fehlern wäre die WER 30 %. Dieser einzelne Prozentsatz gibt uns einen klaren Maßstab für die Leistung.
Das folgende Bild zeigt, wie sehr verschiedene reale Faktoren dazu führen können, dass sich diese Fehler stapeln und die WER in die Höhe treiben.
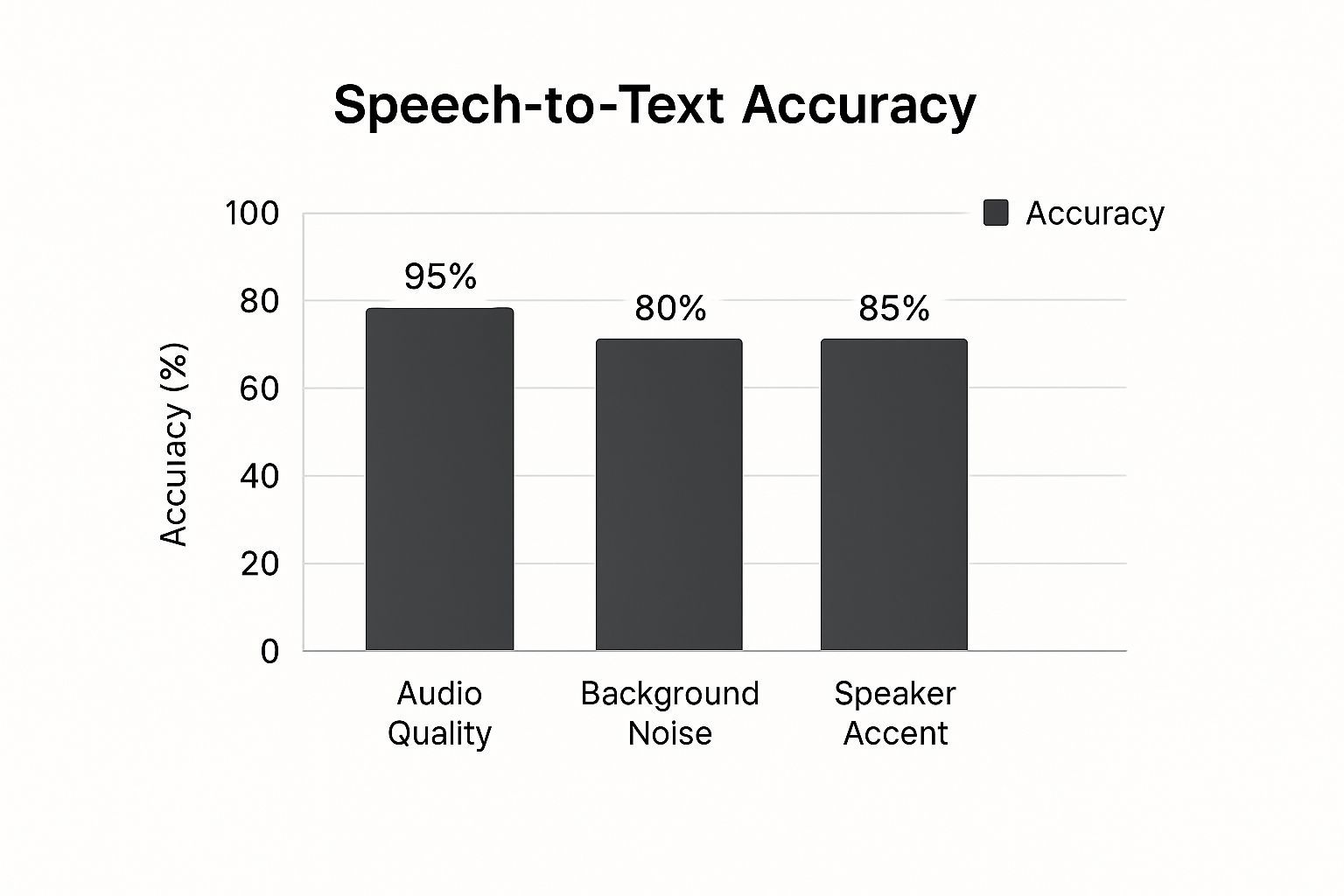
Wie Sie sehen können, ist nichts wichtiger als eine saubere, qualitativ hochwertige Audioaufnahme. Dinge wie starker Hintergrundlärm, mehrere gleichzeitig sprechende Personen oder starke Akzente können die Genauigkeit schnell verschlechtern. Zu verstehen, was diese Fehler verursacht, ist der erste Schritt, um sie zu verhindern.
Reale Faktoren, die die Genauigkeit beeinflussen

Wenn Sie jemals „Hey, Siri!“ gerufen haben und eine verwirrende Antwort erhalten haben, wissen Sie bereits, dass die Genauigkeit von Sprache zu Text keine Selbstverständlichkeit ist. Eine Minute meistert Ihr Sprachassistent einen komplexen Befehl. In der nächsten stolpert er über einen einfachen Namen.
Das ist kein Zufall. Es ist das Ergebnis realer Bedingungen, die im Weg stehen und selbst die intelligentesten KI-Modelle herausfordern.
Stellen Sie es sich so vor: Ein KI-Transkriptionstool ist wie eine Person, die versucht, einem Gespräch zu folgen. In einer ruhigen Bibliothek wird sie jedes Wort verstehen. Aber setzen Sie dieselbe Person in ein lautes Café mit Hintergrundgesprächen und klapperndem Geschirr, und sie wird Dinge verpassen. Für eine KI gilt genau dasselbe Prinzip.
Die makellose Audioqualität aus dem Labor, die für Tests verwendet wird, ist Welten entfernt von der unordentlichen, unvorhersehbaren Audioqualität unseres täglichen Lebens. Wenn Sie diese Einflussfaktoren verstehen, ist das der erste Schritt, um herauszufinden, warum Ihre Genauigkeit möglicherweise nicht stimmt, und um realistische Erwartungen für Ihre Transkripte zu setzen.
Die Qualität Ihrer Audioquelle
Das ist der entscheidende Punkt. Der wichtigste Faktor für eine genaue Transkription ist die Qualität der Audioaufnahme, die Sie der Maschine zuführen. Es ist das klassische „Müll rein, Müll raus“-Szenario. Eine saubere, klare Aufnahme liefert der KI klare Daten, während schlechte Audioaufnahmen sie zu fundierten Vermutungen zwingen.
Mehrere Faktoren tragen zur Gesamtqualität der Audioaufnahme bei:
-
Mikrofonqualität: Das eingebaute Mikrofon Ihres Laptops? Aus der Ferne nimmt es einen dünnen, hallenden Klang auf. Ein dediziertes externes Mikrofon, das nah am Sprecher platziert ist, liefert dagegen ein reiches, klares Signal, das einen großen Unterschied macht.
-
Akustische Umgebung: Die Aufnahme in einem Raum mit vielen harten Oberflächen – denken Sie an Glaswände und Fliesenböden – erzeugt Echo und Hall, die den Klang verschwimmen lassen. Das verwirrt die KI. Weiche Einrichtungsgegenstände wie Teppiche, Vorhänge und sogar Bücherregale sind hier Ihre Freunde; sie absorbieren diese Schallwellen.
-
Audiokompression: Wenn Sie eine Audiodatei stark komprimieren, entfernen Sie subtile phonetische Details, um die Datei kleiner zu machen. Dieser Informationsverlust erschwert es der KI erheblich, zwischen ähnlich klingenden Wörtern wie „kann“ und „kann nicht“ zu unterscheiden.
Navigation durch laute Umgebungen und Sprecherunterschiede
Über die technischen Spezifikationen Ihrer Aufnahme hinaus spielt der Kontext der Sprache selbst eine massive Rolle. Hintergrundgeräusche sind der Hauptfeind. Studien haben immer wieder gezeigt, dass selbst moderate Geräusche die Genauigkeitsrate erheblich beeinträchtigen können.
Stellen Sie sich nur vor, Sie versuchen, einen Anruf aus einem geschäftigen Kundenservice-Center zu transkribieren. Die KI muss die Stimme einer Person aus einem Meer von anderen Agenten, klingelnden Telefonen und klappernden Tastaturen herausfiltern. Das ist eine enorme Herausforderung. Deshalb ist die Isolierung der Hauptstimme so entscheidend für brauchbare Transkripte.
Eine Studie darüber, wie gut verschiedene KI-Modelle mit Hintergrundgeräuschen umgehen, ergab, dass ein führendes Modell 73 % weniger falsche Ausgaben durch Lärm erzeugte als ein Konkurrent. Dies unterstreicht, wie wichtig die Rauschunterdrückungstechnologie eines Modells für die Genauigkeit in der realen Welt ist.
Aber es geht nicht nur um Lärm. Eine ganze Reihe von sprecherbezogenen Faktoren spielt eine Rolle:
-
Akzente und Dialekte: Die meisten KI-Modelle werden auf riesigen Datensätzen trainiert, aber sie können immer noch einen „Standardakzent“ haben. Ein starker regionaler Akzent führt zu phonetischen Eigenheiten, die die KI möglicherweise nicht erkannt hat.
-
Mehrere Sprecher: Das ist schwierig. Wenn Menschen sich gegenseitig ins Wort fallen, verschmelzen ihre Stimmen buchstäblich zu einer einzigen Schallwelle. Der Versuch, zu entwirren, wer was gesagt hat, ist eines der schwierigsten Probleme bei der Transkription.
-
Sprechgeschwindigkeit und Deutlichkeit: Schnelle Sprecher und Nuscheler sind für eine KI genauso schwer zu verstehen wie für uns. Klare Aussprache ist entscheidend.
-
Spezialisierte Terminologie: Eine KI wird nicht magisch die internen Akronyme Ihres Unternehmens oder komplexen Branchenjargon kennen. Sie weiß nur, worauf sie trainiert wurde. Hier sind Funktionen wie benutzerdefinierte Vokabulare ein absoluter Game-Changer.
Vergleich von KI-Transkription mit menschlichen Experten
Wenn es an der Zeit ist, Audio zu transkribieren, stehen Sie vor einer wichtigen Entscheidung: Entscheiden Sie sich für eine hochentwickelte KI oder einen erfahrenen menschlichen Profi? Die wirkliche Antwort liegt nicht darin, welche besser ist, sondern welche das richtige Werkzeug für die anstehende Aufgabe ist.
Es ist der klassische Wettkampf: automatisierte Geschwindigkeit gegen menschliche Einsicht.
KI-Transkription ist Ihr bester Freund, wenn Geschwindigkeit, Kosten und Skalierbarkeit am wichtigsten sind. Denken Sie daran, stundenlange Aufnahmen von internen Besprechungen durchzuarbeiten oder einen schnellen, groben Entwurf einer Podcast-Episode zu erhalten. Für solche Aufgaben sind automatisierte Systeme unübertroffen. Sie können riesige Mengen an Audio in Minuten statt Tagen verarbeiten und das zu einem Bruchteil dessen, was ein menschlicher Dienst kosten würde. Das macht KI zu einer Selbstverständlichkeit für inhaltsreiche, wenig kritische Inhalte, bei denen „gut genug“ wirklich alles ist, was Sie brauchen.
Aber die Diskussion über Genauigkeit wird ernster, wenn Perfektion das Ziel ist. Für Arbeiten mit hohen Einsätzen – denken Sie an juristische Zeugenaussagen, medizinische Diktate oder ausführliche Marktforschungsinterviews – sind menschliche Experten immer noch die unangefochtenen Champions.
Wo Menschen immer noch die Oberhand haben
Ein professioneller menschlicher Transkriptionist tut weit mehr als nur Wörter abzutippen. Er versteht den Kontext, die Nuancen und die Absicht hinter dem Gesagten. Diese menschliche Note ist unerlässlich, um die kniffligen Situationen zu meistern, die die KI immer wieder stolpern lassen.
-
Umgang mit Mehrdeutigkeit: Menschen können überlappende Gespräche entwirren, herausfinden, wer spricht, und Sarkasmus oder subtile Tonänderungen erkennen, die ein Algorithmus einfach nicht verarbeitet.
-
Bewältigung schlechter Audioqualität: KI gibt auf, wenn sie mit starkem Hintergrundlärm oder starken Akzenten konfrontiert wird. Ein Mensch kann dagegen oft durch das Rauschen hindurchhören und die beabsichtigten Worte extrahieren.
-
Gewährleistung der wortgetreuen Genauigkeit: In juristischen und medizinischen Kontexten kann jedes einzelne Wort, jede Pause und jedes „Ähm“ kritisch wichtig sein. Menschen liefern ein echtes wortgetreues Transkript, das Maschinen einfach nicht mit perfekter Genauigkeit nachbilden können.
Das ist nicht nur ein Gefühl; die Zahlen sprechen dafür. Während einige KI-Tools in einem perfekten, ruhigen Labor eine Genauigkeit von etwa 86 % aufweisen, liegt ihre Leistung in der realen Welt näher bei 61,92 %. Im scharfen Gegensatz dazu erreicht ein professioneller menschlicher Transkriptionist durchweg fast 99 % Genauigkeit. Das ist ein riesiger Unterschied, wenn es auf die Details ankommt.
Um Ihnen die Kompromisse zu verdeutlichen, hier eine kurze Übersicht, wie KI- und menschliche Transkription im Vergleich abschneiden.
KI vs. menschliche Transkription Ein direkter Vergleich
Diese Tabelle zeigt die wichtigsten Unterschiede, die Ihnen bei der Entscheidung helfen, welcher Dienst Ihren spezifischen Projektanforderungen entspricht.
Merkmal | KI-Transkription | Menschliche Transkription |
|---|---|---|
Geschwindigkeit | Extrem schnell, liefert Transkripte oft in Minuten. | Langsamer, dauert in der Regel Stunden oder Tage, abhängig von der Audiolänge. |
Kosten | Sehr niedrig, normalerweise pro Minute oder über ein Abonnement abgerechnet. | Deutlich höher, abgerechnet pro Audio-Minute. |
Genauigkeit | Variabel, von 60-90 %. Schwierigkeiten mit Lärm, Akzenten und Fachjargon. | Sehr hoch, durchweg etwa 99 %. |
Kontextuelles Bewusstsein | Fehlendes Verständnis von Nuancen, Sarkasmus oder der Sprecherabsicht. | Hervorragend bei der Interpretation von Kontext, Emotionen und der Identifizierung verschiedener Sprecher. |
Umgang mit schlechter Audioqualität | Erhebliche Schwierigkeiten mit Hintergrundgeräuschen, Überlagerungen und geringer Qualität. | Viel fähiger, schwierige Audioaufnahmen zu entschlüsseln. |
Am besten geeignet für | Interne Besprechungen, Rohentwürfe, durchsuchbare Archive, inhaltsreiche Inhalte. | Gerichtsverfahren, medizinische Aufzeichnungen, Marktforschung, Veröffentlichungen und öffentliche Inhalte. |
Letztendlich hängt die beste Wahl davon ab, wofür Sie bereit sind, Kompromisse einzugehen: Geschwindigkeit und Kosten gegen nahezu perfekte Genauigkeit und Nuancen.
Auswahl der richtigen Transkriptionsmethode
Ihre Entscheidung hängt wirklich von den Bedürfnissen Ihres Projekts ab und davon, wie viel Spielraum Sie für Fehler haben. Benötigen Sie eine schnelle, durchsuchbare Textversion einer Vorlesung? KI ist Ihre Antwort. Benötigen Sie eine fehlerfreie Aufzeichnung einer eidesstattlichen Aussage für einen Gerichtsfall? Ein menschlicher Experte ist der einzige Weg. Um den aktuellen Stand der Sprachfähigkeiten der KI wirklich zu verstehen, ist es interessant, sich Analysen wie die Leistung von Google Translate im Turing-Test anzusehen.
In vielen Fällen ist der intelligenteste Ansatz ein hybrider. Viele moderne Arbeitsabläufe beginnen jetzt mit einem schnellen, KI-generierten Transkript, um einen ersten Entwurf zu erstellen. Dann kommt ein menschlicher Redakteur, um die Fehler zu korrigieren, die notwendigen Nuancen hinzuzufügen und sicherzustellen, dass die endgültige Version perfekt poliert ist.
Umsetzbare Schritte zur Verbesserung Ihrer Transkriptionsergebnisse

Anstatt sich einfach mit fehlerhaften Transkripten abzufinden, können Sie die Kontrolle übernehmen und Ihre Genauigkeit von Sprache zu Text erheblich verbessern. Die Optimierung Ihres Aufnahmeverfahrens und die Unterstützung der KI im Voraus können Ihre Ergebnisse dramatisch verbessern.
Ein paar kleine Anpassungen am Anfang ersparen Ihnen später Stunden mühsamer Bearbeitung.
Stellen Sie es sich vor, Sie geben jemandem eine Wegbeschreibung. Sie könnten aus einem lauten Raum murmeln und auf das Beste hoffen, oder Sie könnten klar sprechen und ihm eine Karte geben. Der zweite Ansatz wird immer besser funktionieren, und dieselbe Logik gilt für Transkriptions-KI.
Kontrollieren Sie Ihre Aufnahmeumgebung
Die einfachsten Gewinne für die Transkriptionsgenauigkeit beginnen mit Ihrer Quell-Audioaufnahme. Bevor Sie überhaupt daran denken, auf „Aufnahme“ zu drücken, nehmen Sie sich einen Moment Zeit, um sich auf den Erfolg vorzubereiten. Dabei geht es weniger um teures Studio-Equipment als vielmehr um ein paar clevere, einfache Entscheidungen.
Schalten Sie zuerst die Hintergrundgeräusche aus. Ein ruhiger Raum ist nicht verhandelbar. Das bedeutet, Lüfter auszuschalten, Ihr Handy stummzuschalten und das Fenster zu schließen. Selbst ein leises Summen, das Sie vielleicht nicht bemerken, kann die KI aus dem Takt bringen und Fehler verursachen.
Als Nächstes gehen Sie näher an Ihr Mikrofon heran. Egal, ob Sie ein professionelles USB-Mikrofon oder nur das auf Ihrem Handy verwenden, die Verringerung des Abstands zwischen Ihrem Mund und dem Mikrofon ist das effektivste, was Sie für die Klarheit der Audioaufnahme tun können. Das lässt Ihre Stimme im Mittelpunkt stehen, nicht das Echo des Raumes.
Die Genauigkeit eines KI-Modells ist nur so gut wie die Daten, die es erhält. Indem Sie klare, deutliche Audioaufnahmen bereitstellen, hoffen Sie nicht nur auf ein besseres Transkript – Sie leiten die KI von Anfang an aktiv zu den richtigen Ergebnissen.
Um das Beste aus Ihrer Audioaufnahme herauszuholen, beherrschen Sie diese Schlüsselbereiche:
-
Investieren Sie in ein gutes Mikrofon: Sie werden erstaunt sein, welche Qualitätssteigerung Sie mit einem externen USB-Mikrofon im Vergleich zu jedem integrierten Laptop- oder Webcam-Mikrofon erzielen.
-
Reduzieren Sie Raumhall: Nehmen Sie in einem Raum mit weichen Oberflächen auf. Teppiche, Vorhänge und sogar ein voller Kleiderschrank wirken Wunder, um Schall zu absorbieren und diesen hohlen, nachhallenden Effekt zu verhindern.
-
Sprechen Sie klar und konsistent: Versuchen Sie, nicht zu schnell zu sprechen oder zu nuscheln. Ein gleichmäßiges, natürliches Tempo und klare Aussprache geben der KI eine viel bessere Chance, die Dinge richtig zu machen.
Verbessern Sie die Genauigkeit der KI-Transkription
Nachdem Sie sichergestellt haben, dass Ihre Audioaufnahme klar ist, können Sie die Transkriptionsgenauigkeit weiter verbessern, indem Sie der KI relevante Kontexte liefern. Obwohl moderne Transkriptionstools ziemlich fortschrittlich sind, sind sie möglicherweise nicht mit Ihren spezifischen Akronymen, Markennamen oder technischen Fachbegriffen vertraut. Hier wird Ihre Eingabe wertvoll.
Viele Plattformen wie Transcript LOL bieten die Möglichkeit, ein benutzerdefiniertes Vokabular zu erstellen. Indem Sie der KI eine Liste von einzigartigen oder weniger gebräuchlichen Wörtern zur Verfügung stellen, die sie möglicherweise antrifft, verbessern Sie ihre Fähigkeit, diese korrekt zu erkennen. Die Einbeziehung von Begriffen wie „SaaS“, „ROI“ oder Projektnamen Ihres Unternehmens hilft dem Modell, diese jedes Mal korrekt zu identifizieren.
Genaue Transkriptionen
Modernste KI
Angetrieben von OpenAIs Whisper für branchenführende Genauigkeit. Unterstützung für benutzerdefinierte Vokabulare, bis zu 10 Stunden lange Dateien und ultraschnelle Ergebnisse.

Sprechererkennung
Identifiziere automatisch verschiedene Sprecher in deinen Aufnahmen und beschrifte sie mit ihren Namen.
Bearbeitungswerkzeuge
Bearbeite Transkripte mit leistungsstarken Werkzeugen wie Suchen und Ersetzen, Sprecherzuordnung, Rich-Text-Formate und Hervorhebungen.
Eine weitere wertvolle Funktion ist die Sprecher-Diarisierung (auch Sprecher-Labeling genannt). Diese identifiziert, wer spricht und wann, was sie unglaublich nützlich macht, um Dialoge in Besprechungen oder Interviews zu sortieren. Das Ergebnis ist ein klares, lesbares Transkript, bei dem jede Zeile korrekt dem Sprecher zugeordnet ist. Diese Funktion ist unerlässlich für die Wiederverwendung von Interviews oder für Anwendungen, bei denen die Sprecherklarheit erforderlich ist.
Um Ihre Ergebnisse zu maximieren, sollten Sie Transkriptionssoftware in Betracht ziehen, die diese erweiterten Funktionen bietet. Dieser proaktive Ansatz stellt sicher, dass Sie vertrauenswürdige Transkripte erstellen und einen nahtlosen Workflow für die Inhaltserstellung schaffen. Die beste Transkriptionssoftware für Besprechungen führt Sie zu Tools, die diese Verbesserungen unterstützen.
Die Zukunft der Genauigkeit der Spracherkennung
Die Reise der Genauigkeit von Sprache zu Text ist nichts weniger als unglaublich. Denken Sie darüber nach: Frühe Systeme konnten kaum ein paar Wörter erkennen, während heutige Modelle komplexe, schnelllebige Gespröns mit einer Fähigkeit meistern können, die fast menschlich wirkt. Dieser Fortschritt ist all den riesigen Datensätzen und den immer intelligenteren Deep-Learning-Modellen zu verdanken, die die Grenzen immer weiter verschieben.
Wenn man zurückblickt, kann man eine gerade Linie von den 1950er Jahren bis heute ziehen und die Rechenleistung direkt mit der Leistung verbinden. Das allererste System, eine Maschine namens Audrey im Jahr 1952, konnte einzelne Ziffern von einem einzelnen Sprecher mit über 90 % Genauigkeit erkennen – damals eine riesige Sache. Heute können die besten kommerziellen Systeme unter perfekten Bedingungen eine Decke von 95 % Genauigkeit erreichen.
Aber "perfekte Bedingungen" ist der Schlüsselbegriff. Die Fehlerraten können immer noch stark schwanken, von nahezu fehlerfrei bei einem kleinen, vorhersehbaren Vokabular bis hin zu einer frustrierenden Fehlerrate von 45 % bei einem riesigen, unvorhersehbaren Vokabular. Das zeigt nur, wie viele Herausforderungen noch zu lösen sind.
Jenseits von Worten zu echtem Verständnis
Mit Blick auf die Zukunft ist die nächste große Hürde nicht nur das Abknabbern der Wortfehlerrate. Es geht darum, Maschinen beizubringen, echtes Verständnis zu entwickeln – all die subtilen, menschlichen Kommunikationsschichten zu erfassen, die immer außer Reichweite waren.
Das bedeutet einen vollen Angriff auf einige ernsthaft komplexe Probleme, wie zum Beispiel:
-
Emotionale Nuancen: Kann die KI den Unterschied zwischen echter Aufregung und bissigem Sarkasmus nur anhand des Stimmtons erkennen?
-
Kontextuelles Bewusstsein: Versteht sie den Insider-Witz, die Redewendung oder den Rückbezug auf etwas, das vor zehn Minuten erwähnt wurde?
-
Das Chaos der realen Welt: Wie gut kann sie einen bellenden Hund, eine heulende Sirene oder zwei Personen, die sich versehentlich ins Wort fallen, bewältigen?
Das eigentliche Ziel ist es, die Lücke zwischen einfacher Transkription und echtem Verständnis endlich zu schließen. Die Zukunft ist nicht nur eine KI, die Worte hört; es ist eine KI, die die Bedeutung, die Absicht und das Gefühl dahinter versteht, genau wie wir.
Dieser Drang nach tieferem Verständnis wird die nächste Welle ausgeklügelter Werkzeuge antreiben. Zum Beispiel steht und fällt die Effektivität von KI-Empfangstechnologie mit ihrer Fähigkeit, gesprochene Anfragen ohne einen einzigen Haken zu verarbeiten. Da diese Modelle besser darin werden, zu verstehen, was wir wirklich meinen, werden diese Werkzeuge völlig nahtlos.
Häufig gestellte Fragen zur Transkriptionsgenauigkeit
Wenn Sie sich mit Sprache-zu-Text beschäftigen, werden Sie unweigerlich auf einige praktische Fragen stoßen. Es spielt keine Rolle, ob Sie es zum ersten Mal benutzen oder seit Jahren transkribieren – das Verständnis der kleinen Details hilft Ihnen zu wissen, was Sie erwarten können und, was noch wichtiger ist, wie Sie bessere Ergebnisse erzielen.
Lassen Sie uns einige der häufigsten Fragen klären, die wir hören.
Was ist ein guter Genauigkeitswert für Sprache-zu-Text?
Das ist die große Frage, und die ehrliche Antwort ist immer: Es kommt darauf an, wofür Sie es brauchen. Es gibt keine einzelne Zahl, die "gute" Genauigkeit definiert. Es geht darum, was für Ihre spezifische Aufgabe funktioniert.
-
Für Ihre eigenen Notizen oder einen groben ersten Entwurf: Eine Genauigkeit von 80-85 % ist oft mehr als ausreichend. Sie erhalten die wichtigsten Punkte und Kernbotschaften, ohne Perfektion zu benötigen.
-
Für öffentliche Inhalte wie Blogbeiträge oder Video-Untertitel: Hier sollten Sie 95 % oder mehr anstreben. Es wird immer noch eine menschliche Nachbearbeitung erforderlich sein, aber die Hauptarbeit ist erledigt.
-
Für juristische oder medizinische Transkripte: Der Goldstandard ist 99 % oder mehr. In diesen Bereichen kann ein einziger Fehler erhebliche Auswirkungen haben, daher ist Genauigkeit nicht verhandelbar.
Ein "guter" Wert bedeutet nicht, eine magische Zahl zu erreichen. Es geht darum, ob das Transkript seine Aufgabe erfüllt, ohne dass Sie Stunden mit schmerzhaftem Bearbeiten verbringen müssen.
Warum variieren die Genauigkeitswerte so stark?
Haben Sie jemals zwei verschiedene Audiodateien in dasselbe Tool hochgeladen und völlig unterschiedliche Genauigkeitswerte erhalten? Das ist kein Fehler; so funktioniert diese Technologie einfach.
Die Leistung einer KI ist ein direktes Spiegelbild der Audioqualität, die Sie ihr zuführen.
Ein kristallklarer Podcast mit einem Sprecher, der ein hochwertiges Mikrofon verwendet, kann über 95 % Genauigkeit erreichen. Aber nehmen Sie eine verrauschte Konferenzschaltung, bei der sich Leute ins Wort fallen und Fachjargon verwenden, und Sie haben vielleicht Glück, wenn Sie 75 % erreichen. Die KI ist nur so gut wie das Ausgangsmaterial.
Wenn Sie weitere Fragen haben, finden Sie auf unserer Seite mit den FAQs zu Transkriptionsdiensten noch mehr Details.
Bereit, Ihre Audio- und Videoinhalte in klare, umsetzbare Texte umzuwandeln? Transcript.LOL bietet schnelle, hochgenaue KI-gestützte Transkriptionen mit den Funktionen, die Sie benötigen, um die Arbeit richtig zu erledigen. Starten Sie noch heute kostenlos unter https://transcript.lol.